Neymar e Vini Jr na partida contra a Escócia (imagem: reprodução/Fifa)Resumo
O data center da Elea no Rio de Janeiro registrou um pico de 951,89 Gb/s de trânsito de dados durante a partida da seleção brasileira contra a Escócia.
A alta demanda de internet durante a Copa do Mundo levou as operadoras a se prepararem para picos de tráfego, com a TIM projetando uma demanda cinco vezes maior do que o habitual.
A TIM está preparando sua infraestrutura de rede, incluindo a redução da latência e a utilização de inteligência artificial para gestão dinâmica da rede, para oferecer uma experiência mais estável aos clientes.
O interesse do brasileiro pela Copa do Mundo, com direito a jogos transmitidos em variados apps, levou a uma alta nunca antes vista de consumo de internet, segundo empresas do setor. O data center da Elea no Rio de Janeiro atingiu pico durante a partida de ontem (24/06), com 951,89 Gb/s de trânsito de dados durante o segundo gol de Vini Jr, por volta das 19h30.
O jogo do Brasil contra a Escócia voltou a evidenciar o impacto dos grandes eventos esportivos sobre a infraestrutura digital. Ao longo da competição, a empresa especializada em data centers também detectou outros dois momentos de tráfego intenso: 865,27 Gb/s na partida contra o Haiti (em 19/06) e 865,02 Gb/s na estreia contra o Marrocos (13/06).
No servidor identificado como RJO1 são processadas as transmissões da Globo e do Globoplay.
De acordo com a Elea, a alta decorre não apenas da transmissão dos jogos, mas também da procura por redes sociais, aplicativos de mensagens, plataformas digitais e serviços financeiros durante jogos da seleção masculina de futebol.
Como as operadoras se preparam para os picos de tráfego?
A operadora TIM projeta uma demanda cinco vezes maior do que o habitual nas próximas etapas do evento esportivo. Por conta disso, disse que está preparando a infraestrutura de rede. Ela afirmou que reduziu a latência e tomou outras providências para oferecer uma experiência mais estável aos clientes, mesmo nos momentos de pico extremo de acessos simultâneos.
Por exemplo, a TIM utiliza inteligência artificial para realizar a gestão dinâmica da rede. Tudo corre em tempo real. Há ainda parcerias com plataformas de streaming.
Conheça as diferentes formas de ver as mensagens do Mail do iCloud (imagem: Lupa Charleaux/Tecnoblog)
Existem diferentes meios de acessar o Mail do iCloud para centralizar as comunicações e checar as mensagens em diferentes dispositivos. No iPhone, iPad e computadores Mac, é necessário ativar uma configuração nos “Ajustes” do dispositivo para que o serviço de e-mail seja integrado automaticamente ao app nativo Mail.
Para os usuários de Android ou PC com Windows, o caminho ideal é acessar o site oficial do serviço via navegador. Em todos os cenários, o usuário pode responder e-mails, gerenciar pastas ou escrever novas mensagens de forma rápida e segura.
A seguir, veja o passo a passo para acessar o e-mail do iCloud no celular ou PC.
Abra o aplicativo “Ajustes” para acessar as configurações do iPhone ou iPad. Essa etapa inicial é essencial para preparar o dispositivo para acessar o iCloud Mail.
Abrindo os “Ajustes” do iPhone (imagem: Lupa Charleaux/Tecnoblog)
2. Toque no seu perfil da Conta Apple
Toque no seu nome no topo da tela para abrir as opções de configurações e gerenciamento do ID Apple.
Abrindo o menu da Conta Apple (imagem: Lupa Charleaux/Tecnoblog)
3. Selecione a opção “iCloud”
Toque em “iCloud” para abrir o menu com detalhes sobre os serviços e aplicativos relacionados ao armazenamento na nuvem da Apple.
Selecionando o menu “iCloud” (imagem: Lupa Charleaux/Tecnoblog)
4. Abra as configurações do “Mail”
Na seção “Salvos no iCloud”, toque em “Mail” para iniciar a configuração do e-mail do iCloud.
Abrindo a opção “Mail” do iCloud (imagem: Lupa Charleaux/Tecnoblog)
5. Ative a opção “Usar neste dispositivo”
Ative a chave ao lado da opção “Usar neste iPhone” ou “Usar neste iPad”, dependendo do aparelho. Ao executar essa ação, o iCloud Mail será automaticamente configurado com o app “Mail” do dispositivo.
Ativando o uso do Mail do iCloud no dispositivo (imagem: Lupa Charleaux/Tecnoblog)
6. Acesse o app “Mail”
Por fim, abra o aplicativo “Mail” para ver o e-mail do iCloud no iPhone ou iPad imediatamente.
Acessando o app “Mail” para ver a caixa de entrada (imagem: Lupa Charleaux/Tecnoblog)
Como acessar o e-mail do iCloud no Mac
1. Acesse os “Ajustes do Sistema” do Mac
Clique no ícone de maçã, no canto superior esquerdo da tela do Mac, e selecione “Ajustes do Sistema”. Esse painel gerencia todos os recursos internos do computador e é o ponto de partida para as configurações de acesso ao e-mail do iCloud.
Abrindo os “Ajustes do Sistema” do Mac (imagem: Lupa Charleaux/Tecnoblog)
2. Clique no seu nome do ID Apple
Clique no seu nome exibido no topo da barra lateral esquerda na janela de “Ajustes” para abrir mais configurações do Mac.
Acessando o menu do ID Apple (imagem: Lupa Charleaux/Tecnoblog)
3. Abra o menu “iCloud”
Clique na opção “iCloud” para acessar as configurações do serviço de armazenamento na nuvem da Apple.
Acessando a opção “iCloud” (imagem: Lupa Charleaux/Tecnoblog)
4. Selecione a opção “Mail do iCloud”
Navegue pela lista de serviços integrados e clique em “Mail do iCloud” para abrir um menu de configurações da ferramenta.
Selecionando o “Mail do iCloud” (imagem: Lupa Charleaux/Tecnoblog)
5. Ative a ferramenta de e-mail
Na janela pop-up, clique no botão “Ativar” ao lado da opção “Mail do iCloud” para habilitar o recurso e, em seguida, clique em “OK” para confirmar. Essa mudança permite entrar no e-mail do iCloud diretamente pelo app “Mail” do Mac.
Ativando a configuração automática do Mail do iCloud (imagem: Lupa Charleaux/Tecnoblog)
6. Abra o app “Mail” no Mac
Localize o aplicativo “Mail” no Dock ou no Launchpad e clique nele para abrir a caixa de entrada do iCloud Mail no seu computador Mac.
Abrindo o app “Mail” no Mac (imagem: Lupa Charleaux/Tecnoblog)
Como acessar o e-mail do iCloud via navegador
1. Entre no site oficial do Mail do iCloud
Use o navegador do celular Android ou do computador Windows para acessar: icloud.com/mail. Esta é a página oficial para quem precisa acessar o e-mail iCloud pelo PC ou outros sistemas.
Acessando o site oficial do Mail do iCloud pelo navegador (imagem: Lupa Charleaux/Tecnoblog)
2. Inicie a sessão da Conta Apple
Toque em “Iniciar sessão” e, em seguida, faça login na Conta Apple vinculada ao seu e-mail do iCloud que você deseja acessar para avançar. Caso a verificação em duas etapas esteja ativada, confirme o código enviado aos seus aparelhos autorizados.
Fazendo login na Conta Apple (imagem: Lupa Charleaux/Tecnoblog)
3. Ajuste as opções de privacidade do e-mail
Caso você seja assinante do iCloud+, escolha as formas de proteção de privacidade. Após ajustar os parâmetros, toque em “Continuar” para entrar no e-mail do iCloud pelo Android ou computador.
Definindo as configurações de privacidade do Mail (imagem: Lupa Charleaux/Tecnoblog)
4. Navegue pela caixa de entrada do e-mail do iCloud
Por fim, acesse a caixa de entrada do e-mail do iCloud e cheque suas mensagens pelo navegador do PC ou smartphone Android.
Navegando pela caixa de entrada do e-mail do iCloud (imagem: Lupa Charleaux/Tecnoblog)
Por que não consigo acessar o e-mail do iCloud?
Existem alguns motivos que podem impedir o acesso ao e-mail do iCloud. Os mais comuns são:
Conta não ativada: antes de sincronizar o serviço nos dispositivos Apple, o primeiro passo obrigatório é criar um e-mail no iCloud por meio das configurações do ID Apple;
Bloqueio preventivo de segurança: errar a senha sucessivas vezes ou acessar a conta de locais incomuns faz a Apple aplicar uma retenção de segurança, suspendendo o acesso temporariamente;
Falha na autenticação de dois fatores (2FA): o sistema impede o login se o usuário não estiver com um dispositivo confiável por perto para receber ou gerar o código de verificação obrigatório;
Instabilidade de rede ou servidores: o serviço de e-mail do iCloud pode estar fora do ar devido a manutenções internas ou a própria conexão Wi-Fi e dados móveis está instável;
Incompatibilidade de sistema ou dados corrompidos: sistemas operacionais desatualizados geram falhas no aplicativo, enquanto arquivos temporários corrompidos (cache) impedem a atualização da caixa de entrada.
O que fazer se não lembro a senha do iCloud Mail?
O caminho mais seguro para recuperar a senha do iCloud é utilizar um dispositivo confiável da Apple, como o iPhone ou o iPad. Basta acessar “Ajustes”, tocar no seu nome na parte superior da tela e selecionar “Iniciar Sessão e Segurança” para redefinir o código.
Caso esteja sem o aparelho por perto, acesse o site oficial iforgot.apple.com em qualquer navegador para iniciar o resgate. Outra opção é baixar o aplicativo “Suporte da Apple” em um dispositivo emprestado e utilizar o recurso dedicado a ajudar terceiros.
Se a Apple não validar a identidade de imediato, a saída é acionar o protocolo de recuperação de conta. Esse processo exige uso de um número de telefone confiável e pode demandar alguns dias de espera enquanto a empresa analisa os dados.
Também posso configurar o iCloud Mail em outros apps de cliente de e-mail?
Sim, o ecossistema da Apple permite integrar o iCloud Mail a outros aplicativos de e-mail de forma simples. Em plataformas como o Outlook para Windows ou em aplicativos do iOS e macOS, o processo é facilitado por fluxos de login automatizados.
Para apps que exigem configuração manual, é preciso inserir as credenciais dos servidores IMAP e SMTP da Apple. Essa ponte de comunicação deve ser feita utilizando os servidores imap.mail.me.com (porta 993) e smtp.mail.me.com (porta 587), ambos protegidos com criptografia SSL ou TLS.
O segredo dessa integração está na segurança: o usuário precisará gerar uma senha específica de aplicativo. Essa combinação temporária substitui a senha padrão, protegendo a conta principal de acessos não autorizados de terceiros.
Gmail agora permite troca de endereço no Brasil (imagem: Vitor Pádua/Tecnoblog)Resumo
Google liberou no Brasil a opção de mudar o endereço principal do Gmail sem criar uma nova conta.
Mudança permite que o usuário troque o nome antes do @gmail.com e mantenha os dados da conta.
O endereço antigo continua funcionando como um endereço alternativo vinculado à conta do Google.
O Google começou a liberar no Brasil a opção de mudar o endereço principal do Gmail sem precisar criar uma nova conta. Com o recurso, o usuário pode trocar o nome que aparece antes do @gmail.com, mantendo a mesma Conta do Google, os dados dela e o histórico de uso.
A novidade pode ser útil para quem criou um e-mail antigo, quer corrigir um nome pouco profissional ou precisa atualizar a conta sem refazer cadastros do zero. Antes, a alternativa mais comum era criar outro Gmail e migrar manualmente contatos, serviços e assinaturas.
Gmail já permite alteração de e-mail da Conta do Google (imagem: Igor Shimabukuro/Tecnoblog)
Como mudar o endereço do Gmail?
A alteração pode ser feita pelas configurações da Conta do Google no aplicativo do Gmail:
Abra o app do Gmail e toque no ícone de perfil;
Selecione “Gerenciar sua Conta do Google”;
Acesse a aba “Informações pessoais”;
Entre em “E-mail”;
Clique em “E-mail da Conta do Google”;
Toque em “Alterar o e-mail da Conta do Google”;
Digite o novo endereço desejado.
Endereço antigo continua funcionando
Endereço antigo continuará valendo para receber e enviar mensagens (ilustração: Vitor Pádua/Tecnoblog)
A troca não apaga o endereço anterior, que continuará funcionando como um endereço anternativo vinculado à conta do Google. Ou seja, mensagens enviadas para o Gmail antigo ainda chegam à mesma caixa de entrada.
Dessa forma, caso o endereço antigo esteja vinculado em redes sociais e outros serviços, e-mails de verificação, mensagens promocionais e outras mensagens devem continuar chegando. Importante frisar que, nesses casos, o usuário precisará atualizar manualmente as credenciais de login em cada site, app e serviço que usam o Gmail antigo.
O endereço antigo pode ser usado como opção de recuperação da conta em caso de perda de senha ou bloqueio de acesso, e o usuário também poderá continuar enviando e-mails pelo endereço anterior, se quiser.
Google impõe limites para a troca
A mudança de endereço, no entanto, não poderá ser feita sem algumas restrições:
Cada usuário só poderá escolher um novo endereço a cada 12 meses.
Haverá um limite de três novos nomes de usuário por conta ao longo do tempo.
É possível voltar ao endereço anterior, em caso de arrependimento, mas a reversão bloqueia a escolha de um novo e-mail por 30 dias.
O nome antigo não ficará disponível para criar uma nova Conta do Google. Ele permanece reservado e vinculado ao titular original.
Veja o passo a passo para migrar as mídias do Google Fotos para o iCloud (imagem: Reprodução)
A transferência de imagens do Google Fotos para o iCloud é feita pelo Google Takeout, permitindo a migração direta entre os servidores na nuvem. Basta acessar a plataforma, configurar a exportação dos dados e autorizar o envio para as mídias serem movidas de forma automatizada e segura.
Durante o processo, as mídias mantêm os metadados de data e localização e são organizadas em um álbum específico. Vale dizer que as imagens originais permanecem na plataforma de origem, exigindo a remoção manual caso o objetivo seja liberar espaço na nuvem.
Como alternativa para a transferência, é possível baixar toda a biblioteca do Google Fotos para um computador e fazer o upload manual no iCloud. Outra opção, caso as fotos estejam sincronizadas localmente no aparelho, é enviá-las manualmente para a nuvem da Apple.
A seguir, veja o passo a passo para transferir fotos do Google Fotos para o iCloud.
Use o navegador do celular ou computador para acessar o Google Takeout e, se necessário, faça login na Conta Google. Essa é a plataforma oficial do Google que centraliza as opções de portabilidade e permite mover os arquivos armazenados diretamente para outras nuvens.
Acessando o Google Takeout (imagem: Lupa Charleaux/Tecnoblog)
2. Inicie o processo de migração de mídias
Verifique as informações do Google Fotos sobre os álbuns e mídias da galeria que serão incluídos no pacote de envio. Em seguida, toque em “Continuar” para iniciar a configuração do processo de migração.
Iniciando a configuração da migração entre as nuvens do Google e Apple (imagem: Lupa Charleaux/Tecnoblog)
3. Faça login na Conta Google
Insira as credenciais de login da Conta Google onde estão salvas as imagens que você deseja enviar para o iCloud.
Fazendo login na Conta Google de origem (imagem: Lupa Charleaux/Tecnoblog)
4. Autorize o acesso do Google Takeout à Conta Google
Leia os termos de privacidade do Google Takeout e toque em “Continuar” para autorizar o acesso da plataforma aos arquivos do Google Fotos. Essa permissão temporária permite que o sistema organize o lote de imagens para a migração.
Autorizando o acesso do Google Takeout ao armazenamento na nuvem (imagem: Lupa Charleaux/Tecnoblog)
5. Selecione o iCloud como destino da transferência
Ao retornar ao Google Takeout, vá até a seção “Mover para:” e escolha a opção “Apple – Fotos do iCloud” como o serviço que receberá as mídias do Google Fotos.
Selecionando o iCloud como destino para o envio dos arquivos (imagem: Lupa Charleaux/Tecnoblog)
6. Confirme a migração do Google Fotos para o iCloud
Após selecionar o serviço, toque em “Continuar” para avançar no processo de transferência de arquivos.
Confirmando o destino da migração dos arquivos do Google Fotos (imagem: Lupa Charleaux/Tecnoblog)
7. Inicie a sessão na conta Apple
Faça login na conta Apple que receberá os conteúdos do Google Fotos. Certifique-se de que o perfil possui espaço de armazenamento disponível na nuvem para acolher o lote de arquivos.
Iniciando a sessão na Conta Apple (imagem: Lupa Charleaux/Tecnoblog)
8. Autorize o acesso do Google Takeout à conta Apple
Na próxima tela, leia as informações e toque em “Permitir” para autorizar o acesso do Google Takeout à conta Apple e, por consequência, ao iCloud.
Autorizando o acesso do Google Takeout ao iCloud (imagem: Lupa Charleaux/Tecnoblog)
9. Confirme a transferência entre o Google Fotos e o iCloud
Ao voltar ao Google Takeout, leia as informações sobre a cópia dos dados e o processo de transferência. Por fim, toque em “Concordar e continuar” para iniciar a migração entre as nuvens.
Um e-mail do Google confirmará o início da transferência das fotos e vídeos do Google Fotos para o iCloud. Quando a transferência for finalizada, a marca enviará outra mensagem informando a conclusão do processo.
Iniciando a migração das mídias do Google Fotos para o iCloud (imagem: Lupa Charleaux/Tecnoblog)
Existem outras formas de mandar fotos do Google Fotos para o iCloud?
Sim, uma alternativa prática é sincronizar localmente a galeria do Google Fotos no dispositivo. Em seguida, o usuário poderá acessar o iCloud via app ou navegador e fazer upload dos arquivos para a plataforma da Apple.
O que acontece ao transferir fotos do Google Fotos para o iCloud?
Estas são algumas ações que ocorrem durante a migração do Google Fotos para o iCloud:
Migração direta entre nuvens: o envio ocorre direto entre os servidores das empresas, sem consumir os dados de internet do usuário ou o armazenamento local do dispositivo;
Permanência dos arquivos originais: as imagens originais não são apagadas automaticamente. Se o objetivo é liberar espaço no Google Fotos, será necessário deletá-las manualmente após o processo;
Preservação de metadados: informações cruciais embutidas nos arquivos, como localização, data, hora, nome e formato original, são mantidas para garantir a organização cronológica no destino;
Organização automatizada no destino: os itens chegam direto ao aplicativo Fotos do ecossistema Apple, organizados em um álbum específico batizado como “Importado do Google” para facilitar a localização;
Tratamento de formatos e resoluções: as mídias são transferidas na qualidade máxima fornecida pelo Google, mas extensões incompatíveis com a Apple podem ser convertidas ou movidas para o iCloud Drive;
Prazo de conclusão: dependendo do tamanho do acervo no Google Fotos, o processo pode levar de algumas horas a vários dias. O usuário receberá um e-mail de confirmação assim que a transferência for concluída.
Por que não consigo passar fotos do Google Fotos para o iCloud?
Existem alguns pontos que podem impedir a transferência de arquivos do Google Fotos para o iCloud. Os principais são:
Falta de armazenamento na Apple: o ecossistema da Maçã rejeitará novos arquivos se o limite de armazenamento for atingido, sendo necessário expandir o plano ou liberar espaço no iCloud;
Falha de autorização entre contas: a transferência direta (server-to-server) exige login e permissão explícita da Conta Google para enviar os dados ao Apple ID. Sem essa autorização, o processo não é iniciado;
Barreiras de segurança ativadas: recursos de privacidade estrita, como a Proteção Avançada de Dados da Apple, podem bloquear a importação dos arquivos;
Formatos ou tamanhos incompatíveis: arquivos excessivamente pesados ou extensões de imagem não suportadas pelo sistema iOS podem travar o envio de itens específicos e interromper a migração;
Instabilidade temporária nos servidores: sobrecargas nos sistemas das empresas ou oscilações de rede geram falhas de tempo limite (timeout), interrompendo o processo e exigindo uma nova tentativa.
Consigo cancelar a transferência de fotos e vídeos do iCloud para o Google Fotos?
Sim, é possível cancelar o processo acessando o menu “Gerenciar exportações” do Google Takeout. Por lá, o usuário consegue ver o andamento da transferência e interromper a migração dos dados para o iCloud.
Vale dizer que a interrupção não apaga os arquivos já enviados do Google Fotos, pois o sistema trabalha com cópias espelhadas de servidores. Se a pessoa decidir transferir o restante da biblioteca mais tarde, será necessário reativar a função do iCloud e abrir uma nova solicitação de transferência.
Também posso migrar fotos do iCloud para o Google Fotos?
Sim, a Apple oferece uma ferramenta oficial em seu portal de privacidade que permite transferir fotos do iCloud para o Google Fotos. O usuário pode selecionar as mídias e realizar o envio direto de uma cópia dos arquivos automatizadamente para os servidores do Google.
Essa migração ocorre sem a necessidade de downloads e mantém a biblioteca original do iCloud intacta. Dependendo das configurações da conta, os conteúdos adicionados após o início do processo podem até continuar sendo sincronizados automaticamente no destino.
Saiba como o CGNAT é utilizado para compensar a escassez de endereços IPs públicos (imagem: Reprodução/Proxidize)
O CGNAT é uma tecnologia adotada por provedores de internet para compartilhar um único endereço público (IPv4) entre diversos assinantes. Essa solução foi criada para contornar a escassez global de endereços, permitindo a expansão das redes enquanto ocorre a transição gradual para o padrão IPv6.
O funcionamento ocorre na infraestrutura da operadora, que traduz os endereços privados de uma residência para um IP público compartilhado antes de roteá-los à rede. O processo é transparente para navegação comum, possibilitando que múltiplos usuários usem o mesmo recurso de endereçamento sem conflitos.
Entre as vantagens, a tecnologia viabiliza a expansão rápida da conectividade com custos reduzidos, mantendo a internet acessível a milhões de pessoas. No entanto, a grande desvantagem é o bloqueio de redirecionamento de portas, o que frequentemente causa instabilidades em jogos online e redes VPN.
A seguir, saiba mais sobre o conceito do CGNAT, para que serve e como saber se você está navegando utilizando esta tecnologia.
O CGNAT é uma técnica de provedores de internet que compartilha um único IP público (IPv4) entre vários assinantes para contornar a falta de endereços. Essa espécie de “ramal de rede” economiza conexões, mas pode bloquear o redirecionamento de portas e afetar jogos online, câmeras de segurança e VPNs.
O que significa “CGNAT”?
O termo CGNAT une o conceito de Carrier-Grade, que define a infraestrutura de grande porte dos provedores de internet, à tecnologia NAT (Network Address Translation), que remapeia IPs. Essa fusão conceitual surgiu para diferenciar o robusto sistema de operadoras do roteamento simples em equipamentos domésticos.
A expressão ganhou força nos anos 2000 com a chegada das redes móveis e a iminente escassez global de endereços IPv4. O padrão nasceu como uma solução de engenharia emergencial para estender a vida útil da antiga internet antes da transição para o IPv6.
A técnica do CGNAT é aplicada a partir da infraestrutura dos provedores de internet (imagem: Kevin Ache/Unsplash)
Para que serve o CGNAT?
O CGNAT atua como uma sobrevida para a internet antiga, compartilhando um único IP público (IPv4) entre vários assinantes diante da escassez global de endereços. Essa manobra reduz custos operacionais das operadoras e viabiliza a expansão das redes enquanto o mercado migra gradualmente para o padrão IPv6.
Na prática, a tecnologia acelera a ativação de novos clientes sem depender de novos blocos de IP, funcionando também como uma blindagem inicial. Ao esconder os dispositivos atrás de um endereço coletivo, o sistema cria uma barreira extra que dificulta ataques cibernéticos diretos contra os usuários.
Como funciona o CGNAT?
O funcionamento do CGNAT se baseia em uma dupla tradução que adiciona uma camada extra de remapeamento diretamente na infraestrutura do provedor de internet (ISP). Primeiro, o roteador doméstico recebe os dados dos dispositivos locais e os converte em um endereço IP privado intermediário.
Na segunda etapa, esse fluxo chega ao gateway da operadora, que converte esse endereço temporário em um IP público IPv4. Para que milhares de clientes naveguem ao mesmo tempo, a tecnologia utiliza o PAT (Tradução de Portas), distribuindo portas TCP/UDP exclusivas para cada conexão.
Para garantir que as respostas da internet voltem ao usuário correto, o sistema adota o mecanismo de State Tracking (Rastreamento de Estado). Essa ferramenta mantém uma tabela de tradução dinâmica que monitora ativamente a entrada e saída de dados de milhões de assinantes.
Essa engenharia complexa opera em escala massiva para driblar as limitações físicas do protocolo IPv4. Enquanto o mercado faz a transição definitiva para o IPv6, os provedores conseguem reaproveitar os mesmos endereços sem interromper a navegação geral da web.
Esquema de funcionamento do CGNAT (imagem: Reprodução/RapidSpeed)
Qual é o limite de clientes por endereço IP no CGNAT?
O teto de clientes por endereço IP público no CGNAT não depende do hardware da operadora, mas da matemática das portas lógicas disponíveis. Como cada IP possui um limite fixo de 65.535 portas, esse ecossistema precisa ser fatiado milimetricamente para os usuários navegarem simultaneamente.
Especialistas de rede apontam que o equilíbrio ideal é de 128 assinantes compartilhando o mesmo IP, reservando cerca de 500 portas para cada residência. Em cenários de tráfego intenso, os provedores reduzem essa média para 32 clientes por endereço, evitando quedas e lentidões nas conexões.
Tem como saber se estou em CGNAT?
É possível saber se a conexão está sob CGNAT ao cruzar duas informações básicas da rede. Primeiro, você deve acessar a página de administração do roteador doméstico e localizar o endereço de IP cadastrado na aba WAN ou Internet.
Em seguida, entre em um site verificador público, como o whatsmyip.org, e compare o código exibido na tela com o do aparelho. Se o número do roteador for diferente daquele apontado pelo site, você está navegando por meio do IP compartilhado.
Outro sinal definitivo é se o identificador interno do roteador começar com os dígitos entre 100.64 e 100.127. Essa faixa numérica específica foi reservada globalmente pela engenharia de redes para servir como a assinatura exclusiva da tecnologia CGNAT.
Plataformas como WhatsMyIP podem ajudar a identificar se a conexão está sob CGNAT (imagem: Lupa Charleaux/Tecnoblog)
Quais são as vantagens do CGNAT?
Estes são os pontos fortes da tecnologia CGNAT:
Sobrevida ao IPv4: permite que múltiplos assinantes compartilhem o mesmo endereço público, estendendo a vida útil desse protocolo escasso enquanto a migração para o IPv6 avança;
Economia e eficiência: evita a compra inflacionada de novos blocos de IP, otimizando a infraestrutura atual das operadoras para suportar milhões de conexões sem encarecer o serviço;
Expansão simplificada: facilita a entrada rápida de novos clientes e dispositivos na rede do provedor, agilizando o gerenciamento interno de tráfego em larga escala;
Barreira de segurança: cria uma camada de proteção nativa ao esconder os IPs residenciais atrás de um endereço coletivo, dificultando ataques cibernéticos diretos aos equipamentos;
Rastreamento legal: gera relatórios detalhados de tráfego (logs) que ajudam a diagnosticar gargalos e servem como exigência legal para identificar cibercriminosos quando necessário.
Quais são as desvantagens do CGNAT?
Estes são pontos fracos do CGNAT:
Bloqueio de conexões diretas: impede o redirecionamento de portas, inviabilizando o acesso remoto a câmeras de segurança, servidores domésticos, dispositivos de armazenamento (NAS) e à hospedagem de jogos;
Gargalos em P2P e streaming: prejudica o tráfego ponto a ponto, como torrents, e pode fazer com que plataformas de vídeo bloqueiem o acesso ao confundirem o IP coletivo com uma VPN;
Instabilidade em jogos e VoIP: causa quedas de sessão, picos de latência e variações de IP, afetando diretamente a qualidade de chamadas de vídeo e o desempenho em partidas online;
Risco de punição coletiva: se um único usuário cometer crimes virtuais ou disparar spam, o IP compartilhado pode ser banido de sites e jogos, punindo dezenas de vizinhos de rede inocentes;
Efeito cascata em ataques DDoS: ataques de negação de serviço direcionados ao endereço comum podem sobrecarregar o gateway do provedor, derrubando a internet de vários clientes de uma só vez.
Em alguns casos, uma VPN compatível pode solucionar os problemas gerados pelo CGNAT (imagem: Reprodução/Oslks)
CGNAT atrapalha os jogos online?
O CGNAT não impede a jogabilidade, mas costuma afetar negativamente partidas multiplayer online. O sistema altera o NAT para o Tipo 3 (Estrito/Fechado), dificultando o bate-papo por voz e bloqueando o redirecionamento de portas nos consoles.
Títulos modernos com servidores centralizados rodam sem problemas, já que a comunicação não depende de uma rota direta. O gargalo surge em jogos baseados em conexões P2P ou quando o jogador tenta hospedar seu próprio servidor de jogo.
Para escapar desse isolamento, existem saídas práticas que restabelecem a estabilidade das partidas. As alternativas envolvem ativar o protocolo IPv6 na rede, utilizar uma VPN compatível ou solicitar IP público dinâmico diretamente com o provedor de internet.
É possível desativar o CGNAT?
Não é possível desativar o CGNAT mudando as configurações do roteador doméstico, já que esse controle pertence exclusivamente à infraestrutura do provedor. A saída é entrar em contato com o suporte técnico da operadora e solicitar a migração para um IP público dinâmico.
Caso a empresa aceite o pedido, o que varia segundo as políticas da operadora, o aparelho sairá da faixa restrita de IPs privados compartilhados e liberará recursos bloqueados. Para consolidar a mudança e validar o novo mapeamento de portas, basta reiniciar o modem após a confirmação do suporte.
Qual é a diferença entre CGNAT e NAT?
O NAT (Network Address Translation) é a tecnologia clássica que opera em residências ou empresas. Ela permite que o roteador doméstico gerencie vários IPs privados internos e os converta em um único IP público, conectando todos os dispositivos à internet.
O CGNAT (Carrier-Grade NAT) eleva essa mesma tecnologia à escala industrial, funcionando diretamente na infraestrutura do provedor de internet. Ele cria uma camada extra de tradução para fazer com que milhares de assinantes diferentes compartilhem um grupo ainda menor de IPs públicos.
Alexa+ roda em dispositivos Echo (foto: Thássius Veloso/Tecnoblog)Resumo
Amazon lançou a Alexa+ no Brasil, uma versão atualizada da assistente virtual com inteligência artificial generativa.
A Alexa+ é compatível com 98% dos dispositivos, como o Echo Dot (2ª geração em diante) e o Echo tradicional (2ª geração em diante).
Modelos Echo Dot (1ª geração), Echo (1ª geração), Echo Plus (1ª geração), Echo Show (1ª e 2ª gerações) e Echo Spot (1ª geração) não são compatíveis.
A Amazon anunciou ontem (18/06) a chegada da Alexa+ ao Brasil, introduzindo uma versão atualizada da assistente virtual equipada com inteligência artificial generativa. O objetivo é ampliar o processamento de comandos e entregar conversas contínuas aos consumidores na maioria dos eletrônicos da companhia.
A novidade foi oficializada em um evento em São Paulo, acompanhado pelo Tecnoblog, e chega em acesso antecipado após uma etapa de testes com clientes selecionados. A Amazon utilizou o período para analisar o tempo de resposta e a precisão do reconhecimento do idioma antes da distribuição oficial.
Vale mencionar que a nova assistente já está inclusa na assinatura Amazon Prime. Para os consumidores que não participam do programa, os recursos avançados podem ser habilitados por uma assinatura avulsa, estipulada em R$ 99 mensais.
Veja os dispositivos compatíveis com a Alexa+
Os aparelhos a partir da segunda geração contam com suporte garantido. A lista de produtos habilitados inclui:
Echo Dot, incluindo o Echo Dot Max;
Echo tradicional;
Echo Show 5, Echo Show 8, Echo Show 10, Echo Show 11 e Echo Show 15;
Echo Studio, e caixas compactas, como o Echo Pop.
Produtos recentes, como o novo Echo Show 8, Echo Show 11, Echo Dot Max e Echo Studio, foram desenvolvidos nativamente para a plataforma Alexa+, com chips focados em IA que conseguem processar as interações com mais agilidade.
Projetado para IA, Echo Show 11 processa comandos mais rápido (foto: Thássius Veloso/Tecnoblog)
Ainda que exista uma probabilidade alta de que o seu aparelho atual receba a atualização, segundo os dados oficiais da Amazon que indicam 98% de compatibilidade na base ativa do Brasil, uma pequena parcela dos aparelhos não será contemplada com a atualização.
A Amazon oficializou que a Alexa+ não funciona e não será distribuída para os seguintes aparelhos:
Echo Dot (1ª geração);
Echo (1ª geração);
Echo Plus (1ª geração);
Echo Show (1ª e 2ª gerações);
Echo Spot (1ª geração).
A empresa explica que o processamento dos novos algoritmos e grandes modelos de linguagem (LLMs) acontece na nuvem, aliviando a carga sobre os componentes das caixas de som e permitindo entregar o serviço sem forçar a troca da maioria dos equipamentos.
No entanto, limitações físicas de memória e processamento dos chips mais antigos não suportam as exigências da nova Alexa turbinada.
Mas, se isso não é um problema para usuários desses produtos mais antigos, não há com o que se preocupar: a Alexa original continuará funcionando com as habilidades tradicionais de forma gratuita, apenas sem a integração com a nova inteligência artificial.
Como funciona a Alexa+?
Alexa+ já está disponível no Brasil (ilustração: Vitor Pádua/Tecnoblog)
Conforme verificamos, a Alexa+ utiliza a IA generativa para entender o contexto. Agora, o usuário não precisa mais repetir o comando de ativação “Alexa” no começo de cada nova instrução, por exemplo, o que torna as interações mais fluidas.
Segundo a Amazon, mais de 70 grandes modelos de linguagem operam em segundo plano. O software decide sozinho qual desses modelos é o mais eficiente para gerar a resposta correta. O sistema também passou por localização para identificar sotaques, gírias e expressões regionais dos brasileiros.
Pelo celular, o aplicativo da Alexa também ganha uma interface no formato de chatbot, permitindo que os clientes enviem documentos, relatórios ou imagens. A assistente lê o conteúdo do arquivo, estrutura um resumo e sugere ações, como marcar reuniões ou enviar e-mails.
O acesso antecipado já está ativo. Clientes que possuem dispositivos Echo compatíveis e desejam usar as funções da Alexa+ no Brasil podem se inscrever pela página oficial da Amazon ou utilizando o comando de voz: “Alexa, quero Alexa+”.
Saiba o passo a passo para retornar as mídias deletadas para a fototeca do iCloud (imagem: Lupa Charleaux/Tecnoblog)
Recuperar fotos do iCloud é um processo simples de restaurar os arquivos deletados que estão na “lixeira” do armazenamento na nuvem da Apple. No iPhone ou iPad, basta abrir o app “Fotos”, navegar até “Coleções” e selecionar a pasta “Apagados” para visualizar e resgatar as mídias.
Nos computadores Mac ou PC, o procedimento ocorre acessando o portal iCloud.com. Por lá, a pessoa precisa abrir o menu “Fotos”, clicar na pasta “Apagados recentemente” e selecionar os arquivos que deseja retornar para a biblioteca principal do iCloud.
Para a restauração funcionar, é essencial que a sincronização automática das fotos esteja ativa nas configurações dos dispositivos vinculados à conta Apple. Vale dizer que o sistema retém os arquivos deletados por um período máximo de 30 dias antes da exclusão definitiva dos servidores.
A seguir, veja o passo a passo para recuperar fotos e vídeos do iCloud no iPhone, iPad, Mac e PC.
Como recuperar fotos e vídeos do iCloud pelo iPhone ou iPad
1. Acesse o app “Fotos”
Acesse o aplicativo “Fotos” no iPhone ou iPad. Por meio dele, é possível gerenciar as mídias salvas tanto no dispositivo quanto armazenadas na nuvem do iCloud.
Importante: a sincronização de fotos do iCloud deve estar ativada nos ajustes do iOS. Se essa função estiver desabilitada, não é possível gerenciar os arquivos na nuvem.
Abrindo o aplicativo Fotos no iPhone (imagem: Lupa Charleaux/Tecnoblog)
2. Toque em “Coleções”
Na Fototeca do dispositivo, toque em “Coleções” para ver os álbuns e outras opções.
Acessando a guia “Coleções” (imagem: Lupa Charleaux/Tecnoblog)
3. Abra o menu “Apagados”
Desça a tela de “Coleções” até encontrar a seção “Mais itens”. Então, toque em “Apagadas” para acessar a pasta com mídias excluídas recentemente e restaurar fotos do iCloud.
Entrando na pasta “Apagados” (imagem: Lupa Charleaux/Tecnoblog)
4. Selecione as fotos que serão restauradas do iCloud
Toque no botão “Selecionar”, no canto superior direito da tela, para ativar o modo para marcar os vídeos ou fotos do iCloud que serão restaurados. Assim, é possível escolher várias mídias para serem recuperadas simultaneamente.
Selecionando as fotos e vídeos na pasta “Apagados” (imagem: Lupa Charleaux/Tecnoblog)
5. Restaure as fotos e vídeos excluídos
Após selecionar os itens, toque no ícone de três pontos, no canto superior direito. Ao abrir um submenu, toque em “Recuperar” para devolver as mídias para a Fototeca do dispositivo e sincronizar com o iCloud.
Restaurando as mídias para a biblioteca do iCloud (imagem: Lupa Charleaux/Tecnoblog)
Como recuperar fotos e vídeos do iCloud pelo Mac ou PC
Dica
Este método também pode ser realizado utilizando o iPhone ou iPad.
1. Acesse iCloud.com via navegador
Use o navegador do computador Mac ou PC para acessar iCloud.com. Em seguida, inicie a sessão na conta Apple que você deseja gerenciar os arquivos excluídos do iCloud.
Importante: para acessar as fotos e vídeos dos dispositivos vinculados à conta Apple, o recurso de sincronização do iCloud deve estar ativado nos ajustes dos aparelhos. Caso contrário, não será possível resgatar as mídias excluídas.
Fazendo login no iCloud.com (imagem: Lupa Charleaux/Tecnoblog)
2. Abra o menu “Fotos”
Após o login, clique no menu “Fotos” no painel de controle da conta para acessar as mídias armazenadas na nuvem via iCloud.
Acessando o menu “Fotos” (imagem: Lupa Charleaux/Tecnoblog)
3. Clique em “Apagados recentemente”
No canto esquerdo da tela, clique em “Apagados recentemente” para as fotos e vídeos que estão na lixeira do iCloud.
Abrindo a pasta “Apagados recentemente” (imagem: Lupa Charleaux/Tecnoblog)
4. Selecione as fotos e vídeos que serão restaurados
Clique em cima das fotos e vídeos que você deseja recuperar no iCloud.
Selecionando as mídias que serão recuperadas (imagem: Lupa Charleaux/Tecnoblog)
5. Restaure os itens excluídos do iCloud
Após selecionar os arquivos, clique em “Recuperar” no canto direito da tela para retornar as mídias para a Fototeca do iCloud. Automaticamente, esses itens serão sincronizados com todos os dispositivos vinculados à conta Apple.
Clicando em “Recuperar” para devolver as mídias para Fototeca do iCloud (imagem: Lupa Charleaux/Tecnoblog)
O que acontece ao recuperar fotos e vídeos do iCloud?
Estas são as ações que ocorrem ao recuperar fotos e vídeos do iCloud:
Retorno imediato à fototeca: os arquivos saem da pasta “Apagados” e voltam direto para os álbuns e datas originais na biblioteca principal, exatamente onde estavam antes da exclusão;
Sincronização em tempo real: as mídias ressurgem automaticamente em todos os aparelhos conectados à mesma conta Apple, como iPhone, iPad ou Mac, devido ao ecossistema integrado do iCloud;
Consumo de espaço em nuvem: ao saírem da área “Apagados”, os arquivos voltam a ocupar espaço real no plano de armazenamento do iCloud, reduzindo o total de GB disponíveis.
Qual é o prazo para recuperar fotos e vídeos apagados do iCloud?
O iCloud oferece um prazo fixo de até 30 dias para resgatar arquivos na pasta “Apagados recentemente”. Caso a pessoa não faça a restauração dentro dessa janela de segurança, o sistema realiza a exclusão permanente dos dados dos servidores da nuvem.
Posso recuperar fotos apagadas permanentemente do iCloud?
Sim, é possível recuperar fotos excluídas se o usuário tiver um backup do iCloud feito antes da exclusão. Aqui, o truque é formatar o iPhone e depois selecionar a opção de restaurar backup iCloud durante a configuração inicial.
Outra possibilidade é se a pessoa tiver desativado a sincronização com a nuvem em um dispositivo e apagado o conteúdo somente pelo iCloud. Então, o armazenamento local pode ser utilizado como uma cópia de segurança para restaurar os arquivos perdidos.
Consigo recuperar fotos do iCloud em outro iPhone?
Sim, dá para resgatar mídias em outro iPhone ao fazer login com ID Apple no novo aparelho. Em seguida, é necessário ativar a sincronização da biblioteca nas configurações do iOS para espelhar as mídias via internet.
Outra opção é baixar os arquivos específicos acessando o iCloud.com via navegador em qualquer dispositivo. Em ambos os casos, a única condição é que as fotos estejam salvas nos servidores da nuvem e não tenham sido apagadas permanentemente.
Amazon faz lançamento da Alexa+ em evento na capital paulista (ilustração: Vitor Pádua/Tecnoblog)Resumo
A Amazon lançou a Alexa+, uma versão mais inteligente da assistente virtual Alexa no Brasil, que utiliza inteligência artificial generativa para melhorar a compreensão e resposta a comandos.
A Alexa+ estará inclusa no serviço Prime ou poderá ser assinada por R$ 99 por mês, e oferece recursos como nova voz mais natural, conversas mais fluídas e capacidade de entender comandos complexos.
A nova assistente virtual é capaz de realizar tarefas como resumir documentos, interagir com serviços de streaming e realizar compras por voz, com recursos que dependem do aplicativo da Alexa no telefone.
A Alexa brasileira está ficando mais inteligente: a Amazon anuncia a chegada da Alexa+, serviço que se vale de inteligência artificial generativa para dar novas habilidades – e até uma nova voz, mais natural – à assistente que todos conhecem. A nova ferramenta estará inclusa no Prime ou terá preço avulso de R$ 99 por mês (sim, eu chequei com executivos e este valor está correto).
O Tecnoblog já havia revelado os testes realizados com consumidores locais para a liberação da Alexa+. A ideia da Amazon era checar se a assistente de IA entendia bem as perguntas feitas em português e se dava respostas condizentes. Menos de um mês depois, a tecnologia chega ao mercado. O anúncio ocorre num evento em São Paulo, para jornalistas, influenciadores e convidados.
A diretora-geral Talita Bruzzi Taliberti comemorou a novidade: “a Alexa+ é fruto do trabalho para entregar a melhor experiência ao nosso consumidor”. O trabalho de localização para o português incluiu o aprendizado de sotaques, gírias, expressões e formas de falar do brasileiro. Ela compreende quando um mineiro solta um “trem” sem necessariamente significar o meio de transporte.
Como funciona a Alexa+?
Alexa+ roda em diversos dispositivos Echo (imagem: Thássius Veloso/Tecnoblog)
Eu participei do anúncio global da Alexa+, em fevereiro de 2025, nos Estados Unidos. Na ocasião, os executivos bateram na tecla de que a ferramenta pode utilizar diferentes modelos, dependendo do que o usuário deseja fazer. O benefício está na melhor compreensão de instruções complexas, que fogem do “timer de 15 minutos” ou “qual a previsão do tempo”.
Já na demonstração durante um evento em São Paulo, realizado em 18/06, os executivos reforçaram que a assistente está mais conversacional. A ferramenta também mantém conversas mais naturais, sem precisar repetir o nome da Alexa no início de cada nova interação. Segundo a Amazon, ela também consegue entender o momento de parar de responder.
Alexa+ rodando em um Echo Show (imagem: Thássius Veloso/Tecnoblog)
Por exemplo, a Alexa+ sabe o que está na tela do Prime Video e dá respostas referentes àquele conteúdo, o que deve encantar os cinéfilos e seriemaníacos de plantão.
Outra funcionalidade tem a ver com documentos externos: o usuário pode enviar anexos pelo aplicativo da Alexa. O sistema escaneia, depreende as informações principais e pode realizar ações por conta própria, como enviar um resumo por email, adicionar itens à lista de compras ou criar novos compromissos no calendário. Alguns recursos dependem do aplicativo da Alexa no telefone, que recebe interface diferenciada, com cara de chatbot, quando o serviço premium é ativado.
Por fim, os consumidores devem notar que a nova Alexa se lembra das suas preferências expressas durante as interações. Ela grava suas restrições alimentares, quantos filhos você possui, e essencialmente qualquer coisa que a ajude a dar respostas melhores no futuro. Isso não existe na Alexa tradicional.
Alexa+ lembra de preferências e interações passadas (imagem: Thássius Veloso/Tecnoblog)
IA generativa
A Alexa+ roda mais de 70 modelos de inteligência artificial. A cada nova frase ou comando, um sistema de orquestração decide qual tecnologia utilizar para dar a melhor resposta possível.
Nas demonstrações que vimos na capital paulista, foi possível notar que, conforme as nossas frases ficam mais complexas, a Alexa+ leva mais tempo para responder. Às vezes é necessário esperar alguns bons segundos até que ela dê um retorno. Em outras palavras, deixa de ser instantâneo.
Alexa, peça um Uber
Uber no Alexa+ (imagem: Thássius Veloso/Tecnoblog)
Um dos pontos altos do evento em São Paulo foi o uso da Alexa para pedir um carro na Uber. Os sistemas ficam integrados e basta dizer o endereço para o qual você deseja ir. Por meio da interação de voz e os cards na tela do Echo Show, a assistente repete os endereços de origem e destino, informa a tarifa e pede a confirmação do consumidor.
Eu notei que o cliente precisa expressar muito claramente que deseja concluir aquela transação. O mesmo vale para a compra de produtos no marketplace da Amazon, que pode ser feita via comando de voz. Os representantes da empresa explicaram que a assistente digital reconhece a voz ou imagem do usuário antes de fazer o pedido – um alívio para quem tem criança travessa em casa.
Como obter o acesso antecipado?
Michele Butti e Talita Bruzzi Taliberti, executivos da Amazon (imagem: Thássius Veloso/Tecnoblog)
A Amazon inicia hoje o acesso antecipado. Existem duas possibilidades: inscrever-se com um dispositivo que você já possua ou comprar um novo produto das linhas Echo e Fire TV. Para se candidatar, é necessário entrar numa página especial ou dar o comando “Alexa, quero Alexa+”.
Microsoft Edge vai permitir login com uma Conta Google (imagem: Vitor Pádua/Tecnoblog)Resumo
Microsoft Edge enfim permitirá login com Conta Google para sincronizar favoritos, histórico de navegação e outras informações;
aparentemente, novidade visa conquistar usuários de outros navegadores, como o Google Chrome, que poderão mudar para o Edge sem perder seus dados sincronizados;
recurso estará disponível a partir de julho de 2026 para usuários do Edge no Windows e no macOS, com opção de configuração para administradores de TI em organizações.
O Edge é mantido pela Microsoft. Nada mais natural, portanto, que o navegador exija login com uma Conta Microsoft para sincronização de favoritos, histórico de navegação e outras informações. Mas isso vai mudar: em breve, a Microsoft permitirá login com uma Conta Google em seu browser.
Na primeira olhada, parece que a Microsoft está “se rendendo ao inimigo”. Mas, por incrível que pareça, essa decisão faz muito sentido, pois pode ajudar o Edge a conquistar mais usuários, muitos dos quais podem até vir do Chrome.
Então, eu uso o Chrome há uns 10 anos e agora ouvi falar do Edge por um amigo e queria mudar de navegador. Mas todas as minhas senhas, favoritos e histórico estão sincronizados com a minha Conta Google.
Eu também tenho um celular Android, que veio com o Chrome e os aplicativos do Google, e gosto do fato de o Google do computador me trazer todas as senhas e outras informações para o meu celular.
A questão é se eu posso sincronizar tudo do Edge com a minha conta do Google, para mantê-las presentes em todos os lugares.
Perceba que, na mensagem, o usuário deseja usar o Microsoft Edge, mas o fato de depender dos serviços do Google o prende no Chrome. Podemos presumir que, na época, se ele pudesse usar o Edge com a sua Conta Google, o navegador da Microsoft teria conquistado mais um usuário.
Atualmente, Edge só permite login com Conta Microsoft (imagem: Emerson Alecrim/Tecnoblog)
Edge vai permitir login com Conta Google a partir de julho
Demorou para a Microsoft entender que o login com Conta Google no Edge pode trazer usuários, mas finalmente essa possibilidade está a caminho. É o que a companhia revela na página do Microsoft 365 Roadmap. Ali, a empresa informa que a novidade valerá para usuários do Edge no Windows e no macOS.
Em organizações, administradores de TI poderão permitir ou não o login com Conta Google no browser por meio de uma política de configuração específica para isso.
Quando o recurso será liberado? Em algum momento de julho de 2026, revela a Microsoft.
Resta saber se o Google retribuirá com um gesto equivalente — permitir login no Chrome com uma Conta Microsoft. Mas eu acredito que não, afinal, o Chrome já é líder de mercado e, ao que parece, não há grande demanda de usuários do navegador sobre essa possibilidade.
É possível usar uma ferramenta da própria Apple para transferir mídias para o Google Fotos (imagem: Vitor Pádua/Tecnoblog)
Transferir mídias do iCloud para o Google Fotos é um processo de envio automatizado feito por meio do portal de privacidade da Apple. A ferramenta permite que o usuário solicite uma cópia da sua biblioteca, garantindo que todo o backup seja migrado com segurança para o serviço de destino.
O procedimento leva de 3 a 7 dias para ser concluído, gerando uma duplicata de todas as fotos e vídeos selecionados. Vale dizer que a exclusão manual dos conteúdos originais no iCloud ainda será necessária posteriormente, caso a intenção seja liberar espaço de armazenamento na conta Apple.
Como método alternativo, o usuário pode baixar os arquivos manualmente do iCloud para um computador e realizar o upload para o serviço do Google Fotos. No entanto, o método oficial automatizado é mais indicado para a transferência de amplas bibliotecas de mídia.
A seguir, veja o passo a passo para transferir fotos do iCloud para o Google Fotos.
Use o navegador do celular ou computador para acessar o site oficial de dados e privacidade da Apple: privacy.apple.com. Então, faça login na sua Conta Apple para iniciar o uso da ferramenta nativa de migração de arquivos.
Iniciando uma sessão na página de Dados e Privacidade da Apple (imagem: Lupa Charleaux/Tecnoblog)
2. Solicite a transferência de uma cópia de dados
Navegue pela página até encontrar a seção “Transferir uma cópia dos seus dados”. Depois, toque em “Solicitar transferência” para iniciar a migração entre as plataformas.
Tocando em “Solicitar a transferência de uma cópia dos seus dados” (imagem: Lupa Charleaux/Tecnoblog)
3. Escolha o conteúdo que será exportado
Na área “Escolha o que você quer exportar”, selecione a opção “Fotos e vídeos do iCloud”. Em seguida, toque em “Próximo” para continuar o processo para transferir fotos do iCloud para o Google Fotos.
Selecionado a opção “Fotos e vídeos do iCloud” para a transferência (imagem: Lupa Charleaux/Tecnoblog)
4. Defina o serviço de destino dos arquivos
Desça a página de privacidade, toque em “Selecionar destino” e escolha a opção do “Google Fotos” como o local para o envio do lote de mídias.
Escolhendo o Google Fotos como destino para cópia dos arquivos (imagem: Lupa Charleaux/Tecnoblog)
5. Marque as mídias que deseja transferir
Marque as caixas correspondentes aos formatos de mídia que você moverá do iCloud para o Google Fotos. Então, toque em “Continuar” para seguir com a organização do lote de transferência.
Marcando quais formatos de mídias serão transferidos do iCloud para o Google Fotos (imagem: Lupa Charleaux/Tecnoblog)
6. Revise os detalhes da exportação das mídias
Verifique os formatos de mídia que serão enviados do iCloud para o Google Fotos. Se estiver tudo certo, toque em “Continuar”.
Revisando os detalhes da exportação de arquivos (imagem: Lupa Charleaux/Tecnoblog)
7. Conecte a Conta Google
Insira o e-mail e a senha da conta Google para qual você realizará a transferência das fotos ou vídeos do iCloud. Essa autenticação garante que o ecossistema receptor reconheça o usuário legítimo dos dados.
Fazendo login na conta Google que receberá a transferência (imagem: Lupa Charleaux/Tecnoblog)
8. Autorize a transferência dos arquivos para o Google Fotos
Após o login, marque a opção “Adicione à biblioteca do Google Fotos” para conceder a permissão para o sistema receber os novos arquivos. Em seguida, toque em “Continuar” para seguir com a migração.
Autorizando a interação entre o iCloud e o Google Fotos (imagem: Lupa Charleaux/Tecnoblog)
9. Confirme a transferência entre o iCloud e o Google Fotos
Revise as informações da transferência, como o e-mail da conta Google de destino e o espaço de armazenamento necessário para receber o lote de arquivos. Se estiver tudo certo, toque em “Confirmar transferência” e aguarde a mensagem de confirmação.
Por fim, a Apple enviará um e-mail informando o prazo de conclusão da migração das fotos do iCloud para o Google Fotos. A marca também notifica o usuário quando o processo estiver completo.
Confirmando a transferência dos arquivos entre o iCloud e o Google Fotos (imagem: Lupa Charleaux/Tecnoblog)
Existem outras maneiras de migrar fotos do iCloud para o Google Fotos
Além da ferramenta oficial da Apple, existem outras formas práticas para salvar fotos na nuvem no celular ou PC. Uma delas é utilizar o aplicativo do Google Drive diretamente no iPhone para realizar o backup manual e sincronizar os arquivos de mídia.
A outra opção é baixar fotos do iCloud no PC via navegador e, em seguida, fazer upload manual direto na plataforma do Google Fotos. Esse método oferece total controle ao usuário, permitindo selecionar e transferir pastas ou mídias específicas de um servidor para o outro.
O que acontece ao transferir fotos do iCloud para o Google Fotos?
A migração entre as nuvens da Apple e Google envolve regras automatizadas de processamento e armazenamento. Os principais pontos são:
Cópia de segurança intacta: o procedimento gera apenas uma duplicata dos arquivos no destino e não serve para liberar espaço no iCloud automaticamente, sendo necessário uma exclusão manual na conta Apple após o envio;
Janela de processamento e aviso: o ecossistema leva entre 3 a 7 dias para concluir a migração devido às checagens de segurança da ID Apple, que envia uma notificação por e-mail ao finalizar upload;
Conversão de formatos padrão: as mídias são transferidas em extensões universais (.jpg, .png e .mp4), mas imagens em formato RAW ou extensões proprietárias da Apple podem sofrer incompatibilidade e ficar de fora do lote;
Edições definitivas e perda de Live Photos: as modificações visuais feitas nas imagens tornam-se permanentes após a migração, enquanto as Live Photos perdem os metadados de movimento e se transformam em imagens estáticas;
Restrições de álbuns e organizações: álbuns inteligentes e compartilhados não são transferidos, os vídeos saem das pastas originais e recebem o prefixo “Cópia de” nos servidores do Google;
Duplicatas e limite de armazenamento: o sistema do Google elimina imagens idênticas para otimizar o espaço, mas o usuário deve respeitar o teto de 20 mil mídias por álbum e o limite do plano de armazenamento da conta Google.
Por que não consigo passar as fotos do iCloud para o Google Fotos?
Há alguns pontos que podem interferir na migração de fotos do iCloud para o Google Fotos. O motivo mais comum é a falta de autenticação de dois fatores ativa (2FA) na conta Apple ou o recurso iCloud Photos estar desabilitado.
Outro obstáculo frequente é o gargalo no armazenamento, já que o Google Fotos precisa de espaço suficiente para receber o lote de mídias. Caso novos arquivos entrem na fila após o início do processo, o sistema pode falhar por falta de limite.
Por fim, a incompatibilidade de formatos, como arquivos pesados em RAW ou mídias proprietárias da Apple, costuma causar rejeições nos servidores. Nesses casos, o ecossistema do Google barra a conversão automática, interrompendo a transferência de partes da biblioteca.
Posso cancelar a transferência de fotos do iCloud para o Google Fotos?
Sim, é possível interromper a migração diretamente pela página de Dados e Privacidade da Apple durante o prazo de transferência, que leva de 3 a 7 dias. Basta acessar a plataforma, verificar o status do envio dos arquivos e selecionar a opção para encerrar o procedimento.
Caso o cancelamento seja feito no meio do caminho, os dados já processados pelos servidores continuarão salvos no Google Fotos. A interrupção impede apenas o envio do restante do lote, exigindo a exclusão manual do conteúdo parcial se você desistir do processo.
Também posso migrar as fotos do Google Fotos para o iCloud?
Sim, é viável transferir fotos do Google Fotos para o iCloud utilizando ferramentas oficiais ou manuais. O caminho mais simples é o Google Takeout, que envia os arquivos em segundo plano diretamente para os servidores da Apple após a autenticação.
Para quem prefere uma curadoria detalhada, o método tradicional de download e upload via navegador confere total controle ao usuário. Enquanto o ecossistema automatizado agiliza o envio de amplas bibliotecas, o processo manual se destaca na seleção de mídias específicas de uma nuvem para a outra.
Saiba como otimizar o espaço no iCloud e garantir mais GB livres de espaço na nuvem (imagem: Lupa Charleaux/Tecnoblog)
Liberar espaço no iCloud é um meio de remover dados desnecessários salvos nos servidores da Apple, recuperando capacidade para novos arquivos. Essa manutenção é essencial para evitar interrupção na sincronização do iPhone ou Mac, garantindo que os backups continuem ocorrendo com segurança.
Uma estratégia eficaz é gerenciar as mídias, deletando fotos e vídeos pesados que ocupam a maior parte da cota disponível. Também é recomendado excluir backups de dispositivos antigos ou desativar a sincronização automática de apps que não precisam de armazenamento na nuvem.
Outra opção é transferir arquivos importantes para uma pasta local no PC antes de removê-los do servidor, mantendo uma cópia física. É importante lembrar que é necessário esvaziar a pasta “Apagados Recentemente” após a limpeza para, de fato, liberar espaço na conta.
A seguir, conheça 7 práticas que ajudam a liberar espaço no iCloud.
É possível apagar fotos e vídeos do iCloud de forma simples e rápida via navegador no iCloud.com ou pelo app Fotos do iPhone. Por conta do recurso de sincronização automática da Apple, qualquer imagem deletada some instantaneamente de todos os dispositivos conectados.
Ao fazer isso, os arquivos vão para a pasta “Apagados Recentemente”, onde continuam ocupando a cota de armazenamento por 30 dias. Para liberar espaço imediatamente, você deve abrir esse álbum e limpar o lixo permanentemente do servidor na nuvem.
Como as mídias são as grandes vilãs do armazenamento na nuvem, essa faxina reduz drasticamente o volume de dados. Cada arquivo removido recupera de 2 MB a 100 MB de memória, otimizando o espaço total disponível na hora.
O site iCloud.com permite acessar a Fototeca para excluir fotos e vídeos armazenados na nuvem (imagem: Lupa Charleaux/Tecnoblog)
2. Baixe mídias do iCloud no PC
Você pode baixar fotos e vídeos do iCloud para o computador utilizando o site iCloud.com, o sistema nativo do Mac ou o aplicativo para Windows. Esse processo cria uma cópia de segurança no HD, permitindo escolher arquivos em formatos de alta compatibilidade.
Contudo, fazer o download isolado não libera espaço na nuvem automaticamente, já que os originais continuam ocupando a cota de armazenamento. Após salvar os conteúdos em uma pasta local, você pode deletar as mídias salvas no serviço e esvaziar a pasta de itens apagados para recuperar essa memória.
A estratégia de transferir arquivos para o armazenamento físico reduz drasticamente o volume de dados consumidos pelo perfil da Apple. Além de garantir total controle sobre os registros, evita custos extras com assinaturas de planos de dados mais caros.
É possível baixar até 1.000 fotos no iCloud para o armazenamento local (imagem: Victor Toledo/Tecnoblog)
3. Migre fotos do iCloud para o Google Fotos
A Apple oferece uma ferramenta nativa para mover fotos do iCloud para o Google Fotos diretamente entre os servidores das empresas. Feita por meio da página oficial da Maçã, a migração leva de três a sete dias e preserva a organização original dos álbuns diretamente na conta de destino.
Vale destacar que a transferência apenas duplica as mídias, sem liberar espaço de armazenamento na Apple automaticamente. Para recuperar a cota após a transferência completa, é necessário apagar manualmente os arquivos originais do iCloud e, depois, esvaziar a pasta de itens apagados.
Essa estratégia limpa os dados mais pesados dos servidores da Apple, transferindo o consumo de memória para o serviço do Google. O processo é ideal para quem deseja centralizar ou dividir os arquivos em uma plataforma diferente, equilibrando o uso de armazenamento na nuvem.
É possível usar uma ferramenta da própria Apple para transferir mídias para o Google Fotos (imagem: Reprodução/9to5Mac)
4. Verifique outros itens salvos no iCloud
Ao acessar os ajustes do iPhone e tocar na barra de gerenciamento do iCloud, você visualiza o gráfico com tudo o que consome a memória na nuvem. Esse painel detalha o espaço ocupado por backups de aparelhos antigos, e-mails com anexos pesados e dados de aplicativos.
A exclusão desses arquivos secundários reduz o volume total de dados salvos nos servidores e otimiza a cota digital. Ao desativar o backup de apps dispensáveis e limpar o histórico de conversas de e-mails e mensageiros, você recupera espaço instantaneamente
Embora as mídias dominem o armazenamento, essa faxina em documentos e backups esquecidos alivia significativamente o limite da conta Apple. Para garantir a liberação imediata dessa memória oculta, lembre-se de sempre esvaziar a lixeira do iCloud.
O iCloud permite verificar quais tipos de arquivos ocupam mais espaço de armazenamento (imagem: Lupa Charleaux/Tecnoblog)
5. Gerencie as sincronizações com o iCloud
Para gerenciar as sincronizações com o iCloud, basta acessar os ajustes do iPhone e selecionar quais aplicativos podem enviar dados para a nuvem. Ao desativar o pareamento de apps pesados, como Mensagens e Fotos, os dados passam a ser armazenados apenas localmente no aparelho.
Essa estratégia de segmentação reduz o volume da conta digital ao impedir que conteúdos pesados sobrecarreguem o servidor remoto. Além de otimizar o espaço disponível imediatamente, você passa a ter um controle muito mais rígido sobre a privacidade digital.
Vale lembrar que apenas desligar a sincronização não apaga o que já foi salvo nos servidores da Apple. Para recuperar a memória ocupada, você precisa deletar manualmente os arquivos na nuvem e, depois, esvaziar a pasta de itens apagados.
Selecionar quais arquivos serão sincronizados na nuvem ajuda a evitar dados desnecessários no iCloud (imagem: Lupa Charleaux/Tecnoblog)
6. Exclua ou diminua o backup na nuvem
Uma forma eficiente de reduzir o consumo na nuvem é acessar o ajuste do iPhone e entrar na área de gerenciamento de armazenamento. Para apagar um backup do iCloud de aparelhos antigos, basta selecionar o dispositivo desejado e confirmar a exclusão definitiva.
Outra opção para economizar espaço é diminuir o tamanho da cópia de segurança desmarcando apps pesados, como WhatsApp e Mensagens. Essa triagem impede que mídias redundantes sejam enviadas desnecessariamente para os servidores da Apple durante a rotina automática.
Essa faxina remove pacotes de dados obsoletos que costumam ocupar de 5 GB a 50 GB da conta digital de forma invisível. Ao eliminar esses arquivos pesados do servidor, a cota é liberada na hora, mantendo salvos apenas os dados essenciais.
Apagar backups de aparelhos antigos da Apple ajuda a liberar armazenamento na nuvem (imagem: Lupa Charleaux/Tecnoblog)
7. Apague o backup do WhatsApp no iCloud
Para excluir o backup do WhatsApp e recuperar espaço, acesse os ajustes do iPhone, toque no gerenciamento do iCloud e selecione o mensageiro da Meta. Depois, basta escolher a opção de apagar os dados salvos na nuvem e confirmar a remoção definitiva do pacote.
Essa ação elimina apenas a cópia de segurança remota nos servidores da Apple, mantendo o histórico de conversas e mídias intacto localmente no aparelho. Para evitar que o app volte a lotar a conta, lembre-se de desativar a chave de sincronização automática.
Como o acúmulo de arquivos do WhatsApp costuma ocupar de 1 GB a 10 GB de dados, a limpeza gera um alívio imediato no iCloud. Ao deletar esse conteúdo pesado do servidor, você recupera GB na hora para utilizar com documentos mais essenciais.
Excluir o backup do WhatsApp no iCloud pode oferecer um amplo ganho de espaço (imagem: Lupa Charleaux/Tecnoblog)
Por que o iCloud fica cheio?
O iCloud lota rapidamente porque os servidores da Apple armazenam em massa fotos, vídeos e backups de todos os dispositivos do usuário. Como a empresa disponibiliza apenas uma franquia gratuita de 5 GB, esse limite é facilmente superado pela sincronização contínua.
Além disso, muitos usuários confundem o serviço com uma expansão da memória física do iPhone, quando ele é um espelho independente. Esse acúmulo de arquivos pesados e históricos de mensagens satura o plano básico, exigindo limpezas constantes ou a assinatura de mais espaço.
O que acontece se eu não liberar espaço no iCloud?
Quando a conta Apple atinge o limite máximo do iCloud, o ecossistema dos dispositivos pode enfrentar algumas consequências técnicas. As principais são:
Bloqueio de mídias e e-mails: o aplicativo Fotos suspende o upload de novas imagens e impede o acesso aos arquivos em múltiplos dispositivos, enquanto o iCloud Mail deixa de enviar ou receber mensagens nos servidores;
Fim das cópias de segurança: os backups automatizados do iPhone são interrompidos, deixando dados e arquivos desprotegidos contra perdas, furtos ou falhas de hardware;
Falha na sincronização nativa: apps como Notas, Lembretes e Contatos param de compartilhar atualizações entre as telas, gerando inconsistências no histórico dos aparelhos;
Interrupção no WhatsApp: o mensageiro perde a capacidade de salvar novos históricos de conversas na nuvem, impedindo a recuperação do chat se a pessoa trocar de dispositivo;
Paralisação do iCloud Drive: o envio de novos documentos e o compartilhamento de pastas ficam congelados na rede, impedindo o trabalho em arquivos colaborativos;
Risco de exclusão definitiva: caso a conta permaneça acima do teto estipulado, a Apple pode congelar o perfil e, após notificações, eliminar o excesso de dados armazenados.
Consigo ver o que está ocupando armazenamento no iCloud?
Sim, você pode monitorar o consumo do iCloud por meio de um gráfico intuitivo disponível nos ajustes do iPhone, no Mac ou no app para Windows. Esse painel exibe uma visão completa do armazenamento, listando no topo da tela os aplicativos e recursos que mais consomem espaço.
Ao navegar por essa lista, o usuário visualiza a divisão exata por categorias, como fotos, backups e mensagens. Clicar em cada um desses tópicos permite examinar os arquivos em detalhes, facilitando a identificação dos grandes vilões do espaço digital.
Posso comprar mais armazenamento no iCloud?
Sim, você pode expandir o espaço em nuvem migrando para o iCloud+, uma assinatura premium da Apple. O processo para comprar armazenamento no iPhone é feito direto nos ajustes, elevando a cota para fotos e backups e liberando recursos extras de segurança.
Essa expansão digital oferece planos que vão de 50 GB até 12 TB, com a vantagem de poder compartilhar o espaço com a família. Além do iPhone, a contratação pode ser feita pelo Mac, app para Windows ou navegador, e o upgrade do perfil com novo limite de memória é atualizado na hora.
Tem como aumentar o armazenamento do iCloud de graça?
Não existe um método para expandir o armazenamento do iCloud além dos 5 GB gratuitos padrão da Apple. A empresa adota uma política rígida, exigindo a assinatura do plano pago iCloud+ caso o usuário precise de mais espaço nos servidores remotos.
A única alternativa sem custos para contornar esse teto é realizar uma faxina digital rigorosa para otimizar a franquia existente. Isso inclui desativar o backup de apps secundários, deletar arquivos duplicados e esvaziar permanentemente a lixeira do sistema.
Google Earth agora transforma seu navegador em simulador de voo (imagem: Emerson Alecrim/Tecnoblog)Resumo
Google Earth lançou simulador de voo gratuito que funciona diretamente na versão web, sem necessidade de baixar o aplicativo do serviço para desktop;
para usar o simulador, acesse o site do Google Earth, busque por um endereço ou localidade, vá em Ferramentas / Simulador de voo e use os comandos listados para controlar o voo;
novidade do Google Earth está em fase experimental e pode ter falhas.
O clássico, mas sempre fascinante Google Earth já tinha um simulador de voo, mas que exigia que você baixasse o aplicativo do serviço para desktop. Bom, não mais: agora você pode brincar de piloto de avião usando a versão web do Google Earth — isto é, o seu navegador.
É óbvio que a novidade não chega nem perto da experiência proporcionada pelo Microsoft Flight Simulator, por exemplo. O que o simulador de voo do Google Earth faz é permitir que você “flutue” sobre os mapas do serviço tendo uma visão de primeira pessoa.
Não por acaso, o próprio Google avisa que “o simulador de voo foi projetado para exploração casual, e não para treinamento aerodinâmico de alta fidelidade”.
Mas, sim, o simulador do Google Earth tem uma proposta divertida e, bom, não é necessário pagar nada por ele.
Como usar o simulador de voo do Google Earth?
Você só precisa acessar o site do Google Earth usando um navegador compatível (aqui, funcionou com o Chrome e o Edge). Pode ser necessário fazer login com a sua Conta Google. Agora, vá em Explorar a Terra. Na sequência:
busque por um endereço ou localidade no serviço (como “São Paulo / SP”), a não ser que você queira iniciar o voo de uma altitude muito elevada
vá em Ferramentas / Simulador de voo
voe seguindo os comandos da tabela mais abaixo
Se você estiver relativamente próximo do solo, verá que prédios, monumentos e afins serão exibidos com reprodução 3D.
Mas é preciso levar em conta que, no momento, o recurso está em fase experimental. Talvez isso explique o fato de que é relativamente fácil deixar o avião girando em “loop infinito” após apertar as setas. Aliás, na postagem no X que revela a novidade, muitos usuários reclamaram disso.
Simulador de voo do Google Earth no Chrome (imagem: Emerson Alecrim/Tecnoblog)
Principais comandos do simulador de voo do Google Earth
99Compras vem para ser nova opção de compras online de mercado e rotina (imagem: reprodução/99)Resumo
serviço de entregas de supermercado, farmácia e afins da 99 chega aos municípios paulistas de Santo André, São Bernardo do Campo e Diadema após piloto em Goiânia;
integrado ao aplicativo principal da 99, 99Compras ainda está em fase experimental para ajustar a interface entre lojistas, consumidores e entregadores antes do lançamento completo;
redes como Carrefour, Atacadão e Americanas já estão integradas à plataforma de entregas; plano da companhia é expandir a novidade para outras regiões em breve.
O segmento de compras online de itens de supermercado e rotina tem mais um competidor: a 99Compras. Depois de um período piloto em Goiânia (GO), o serviço estreou, nesta semana, nos munícipios paulistas de Santo André, São Bernardo do Campo e Diadema.
A proposta da 99Compras é permitir que o usuário adquira, pela internet, itens de supermercado, farmácia, pet shop, floricultura e de várias outras categorias. As compras são feitas dentro do aplicativo da própria 99, não havendo necessidade de instalação de um app dedicado, portanto.
Na prática, é como se a novidade fosse uma expansão da 99Food, só que direcionada a produtos diversos em vez de focar em refeições.
Ainda em fase experimental
Com o novo serviço, a 99 passa a disputar espaço com o iFood e com o Amazon Now, por exemplo. Ou melhor, passará a disputar, pois o serviço ainda está em fase experimental, tal como a companhia explica:
Durante esse período de testes, a operação estará focada no desempenho do aplicativo e em garantir que a interface entre lojistas, consumidores e entregadores funcione de maneira eficiente e fluida para o lançamento completo.
99
Os testes começaram em abril deste ano, em Goiânia. A recente expansão é direcionada ao ABCD Paulista — a novidade estreia agora em Santo André, São Bernardo do Campo e Diadema, e chegará a São Caetano do Sul em breve.
O plano é expandir a 99Compras para outras regiões, obviamente, o que tornará o serviço oficial. Ainda não há prazo para a chegada em outras localidades, mas a 99 dá a entender que isso não demorará a ocorrer.
Durante muito tempo, fazer compras online foi associado a preços mais altos do que no varejo físico, mas esse cenário vem mudando com a evolução da tecnologia e da logística.
Nosso objetivo é oferecer uma experiência acessível, prática e integrada à rotina das pessoas, conectando conveniência e variedade dentro do ecossistema da 99.
Talita Poleto, diretora comercial da 99Compras
Entre as lojas já integradas à 99Compras estão redes como Americanas, Farmácias Nissei, Carrefour e Atacadão.
Conheça as dicas para ter mais estabilidade na conexão quando estiver vendo os jogos da Copa do Mundo (imagem: Lupa Charleaux/Tecnoblog)
Há diferentes meios de melhorar a velocidade da internet e garantir uma transmissão ao vivo de qualidade durante os jogos do Brasil na Copa do Mundo. Conectar a smart TV via cabo Ethernet elimina interferências, enquanto usar a rede 5 GHz do roteador assegura maior largura de banda para vídeos em alta resolução.
Além disso, é possível otimizar a rede ao desconectar dispositivos ociosos e ajustar o DNS para acelerar o carregamento dos conteúdos. Vale dizer que o uso de IPTV pirata costuma resultar em instabilidades frequentes, sendo um risco desnecessário para quem busca uma experiência fluida e confiável.
A seguir, conheça seis dicas para assistir aos jogos da Copa do Mundo sem perder nenhum lance.
Conectar a smart TV diretamente ao roteador por meio de um cabo Ethernet elimina as barreiras físicas e a interferência de ondas eletromagnéticas que afetam o sinal Wi-Fi. Essa ligação direta estabiliza a entrega da banda contratada, anulando a perda de pacotes e a latência que causam os travamentos.
Na prática, a vantagem não é o aumento da velocidade bruta, mas a consistência no envio contínuo desses dados. O resultado é uma transmissão fluida e sem oscilações, dando um fim ao temido buffering em conteúdos via streaming, como os jogos da Copa.
Uso de cabo Ethernet pode melhorar streaming em geral, incluindo os jogos da Copa do Mundo (imagem: Mario Alberto Magallanes Trejo/FreeImages)
2. Conecte a TV na rede Wi-Fi de 5 GHz
Usar uma rede Wi-Fi na frequência de 5 GHz garante taxas de transferências mais altas para a smart TV, sendo ideal para a alta demanda do streaming em 4K. Essa banda sofre menos interferência de vizinhos que a antiga e congestionada rede de 2,4 GHz.
Essa largura de canal mais limpa reduz drasticamente o buffering, tornando o carregamento de aplicativos e a reprodução de vídeos imediata. O ganho de desempenho é nítido, entregando a velocidade máxima contratada diretamente para a tela da smart TV.
O único contraponto técnico do 5 GHz é o menor alcance de sinal e a dificuldade em ultrapassar barreiras físicas. Se houver muitas paredes no caminho, a estabilidade despenca e a rede 2,4 GHz pode ser uma opção mais confiável.
A frequência de 5 GHz oferece maiores taxas de transferência, melhorando o streaming de conteúdo em alta definição (imagem: Vitor Pádua/Tecnoblog)
3. Melhore o sinal do Wi-Fi
Para melhorar o sinal do Wi-Fi, a primeira regra é posicionar o roteador em um local central, alto e livre de barreiras físicas. Obstáculos como espelhos, paredes espessas e micro-ondas bloqueiam as ondas de rádio, degradando severamente a transmissão dos dados.
Caso o alcance continue baixo, instalar um repetidor ou utilizar um segundo roteador ajuda a expandir a cobertura para os cômodos distantes. Embora essa alternativa elimine as zonas mortas, ela pode reduzir a velocidade devido à divisão da banda.
Então, migrar para a tecnologia Mesh é a escolha ideal para ter máxima eficiência e criar uma rede única e inteligente pela casa. Esse sistema alterna a conexão entre os módulos de forma automática, rápida e sem interrupções.
Roteadores mesh podem ser uma solução para ampliar o raio de alcance do sinal Wi-Fi (imagem: Lucas Braga/Tecnoblog)
4. Desconecte outros dispositivos da rede Wi-Fi
Desconectar aparelhos ociosos da rede Wi-Fi libera mais largura de banda para a smart TV transmitir os jogos sem interrupções. Como todos os dispositivos compartilham a mesma capacidade do roteador, reduzir o tráfego de segundo plano alivia o congestionamento do canal.
Essa limpeza diminui a disputa pelo link de internet, otimizando o fluxo de dados direcionado exclusivamente para o streaming de vídeo. Na prática, o tempo de resposta da rede cai, fazendo com que os aplicativos da smart TV carreguem os conteúdos de forma muito mais veloz.
O benefício é nítido se outros eletrônicos estiverem realizando downloads pesados ou atualizações em segundo plano. Vale destacar que a otimização não ultrapassa o limite do plano contratado, mas garante que a smart TV utilize o teto máximo dessa velocidade.
Muitos dispositivos ociosos conectados a mesma rede podem deixar fluxo de dados mais lento (imagem: terimakasih0/Pixabay)
5. Troque o DNS da sua smart TV
Trocar o DNS da smart TV acelera o tempo de resposta para traduzir os endereços dos aplicativos, localizando os servidores de streaming mais rápido. Servidores otimizados evitam o atraso no carregamento de vídeos, entregam mais estabilidade e reduzem pequenos engasgos por buffering na transmissão.
Para mudar, acesse as configurações de rede da TV, altere o IP para “Manual” e insira opções confiáveis como o 1.1.1.1 (Cloudflare) ou 8.8.8.8 (Google). Embora o caminho exato varie por marca, a função costuma ficar oculta nas configurações avançadas de rede.
Definir manualmente os servidores DNS ajudam a acelerar o carregamento de conteúdos na smart TV (imagem: Lupa Charleaux/Tecnoblog)
6. Evite o IPTV pirata
Os aparelhos de IPTV piratas dependem de servidores clandestinos, sobrecarregados pelo excesso de acessos simultâneos durante os jogos da Copa. Essa infraestrutura precária sofre com constantes quedas de links e atrasos na retransmissão de fontes não autorizadas.
Enquanto a transmissão oficial via cabo ou streaming segue intacta, as caixinhas ilegais enfrentam congelamentos de imagem e buffering. Além disso, as constantes ações de bloqueio realizadas por órgãos reguladores tornam o sinal pirata instável e imprevisível na hora dos jogos.
Aparelhos de IPTV piratas podem apresentar instabilidades ao transmitir os jogos da Copa devido aos servidores ilegais sobrecarregados (imagem: Vitor Pádua/Tecnoblog)
Deixar a internet mais rápida evita o delay nas transmissões ao vivo?
Melhorar a velocidade da internet evita travamentos e quedas de resolução, mas é incapaz de eliminar o atraso das transmissões ao vivo. Esse delay em relação ao tempo real ocorre devido ao intervalo em que os servidores das plataformas levam para codificar e processar o sinal de vídeo.
Uma banda larga robusta garante apenas que o fluxo de dados chegue sem interrupções e com latência de rede reduzida. No entanto, o atraso de segundos nas lives continua existindo por conta do circuito de distribuição dos servidores e dos protocolos de segurança das redes.
Por que a velocidade da minha internet não melhora?
A estagnação da velocidade da internet geralmente ocorre porque a demanda de dados da casa já atingiu o teto máximo do plano contratado com a operadora. Quando o consumo de banda larga supera o limite contratual, a rede simplesmente não tem margem para lidar com o fluxo de dados exigido para as transmissões ao vivo.
Outra causa comum é um problema técnico por parte do provedor que pode estar entregando menos megabits devido a falhas na região. Nesses cenários, a única solução eficaz é acionar o suporte da empresa para exigir a estabilização do sinal.
Tem como saber se estou recebendo a velocidade de internet contratada?
Sim, a forma mais precisa de checar a entrega da internet é conectar um computador diretamente ao roteador via cabo e acessar plataformas como o Speedtest ou FAST.com. Fazer a medição pelo Wi-Fi ou com outros aparelhos ativos na rede pode mascarar o resultado real devido às interferências no sinal sem fio.
O ideal é repetir os testes em horários diferentes para monitorar possíveis oscilações no tráfego da rede do provedor. Se as taxas de upload e download ficarem consistentemente muito abaixo do contratado, a pessoa terá dados concretos para cobrar o suporte técnico da operadora.
Conheça mais detalhes sobre a plataforma de armazenamento na nuvem da Maçã (imagem: sdx15/Shutterstock)
O iCloud é o serviço de armazenamento em nuvem desenvolvido pela Apple para centralizar, fazer backups e sincronizar dados entre todos os dispositivos da marca. Ele atua integradamente ao ecossistema, permitindo o acesso seguro a fotos, documentos e senhas a partir de qualquer iPhone, iPad ou Mac.
A plataforma opera guardando os arquivos automaticamente em servidores remotos por meio de conexões de internet, sem a necessidade de cabos. Todo o processo ocorre em segundo plano com criptografia de ponta a ponta, garantindo que apenas o usuário tenha acesso às informações guardadas.
A versão básica do iCloud é gratuita e oferece 5 GB de armazenamento para mídias e backups. Já o iCloud+ é a assinatura premium que expande essa capacidade para até 12 TB, adicionando recursos avançados de privacidade e compartilhamento familiar.
A seguir, conheça mais detalhes sobre o iCloud, para que serve o serviço na nuvem da Apple e como utilizá-lo em diferentes dispositivos. Também saiba os limites de armazenamento e como expandir a memória digital.
O iCloud é o serviço de nuvem da Apple que centraliza e sincroniza automaticamente arquivos, fotos e senhas entre todos os dispositivos. Integrado ao ecossistema da marca, ele garante acesso seguro aos dados de qualquer lugar, seja por aparelhos conectados ou pelo navegador.
O que significa iCloud?
O nome iCloud segue a tradicional identidade visual da Apple, onde o famoso prefixo “i” faz referência direta à internet. Ele também representa os conceitos de individualidade e inovação que guiam a marca.
Já o termo “cloud” faz referência à computação em nuvem, tecnologia que armazena dados em servidores remotos. Isso significa que os arquivos ficam guardados na rede mundial, acessíveis de qualquer lugar e dispositivos.
O iCloud facilita o acesso a diferentes arquivos em qualquer dispositivos da Apple (imagem: Reprodução/Apple)
Para que serve o iCloud?
O iCloud é utilizado para armazenar, sincronizar e proteger seus dados na nuvem automaticamente em todos os dispositivos Apple. Estas são as principais funcionalidades:
Centralização e colaboração: unifica a biblioteca de fotos e vídeos em alta resolução e permite o compartilhamento de pastas e arquivos com outros usuários de forma simples e rápida;
Comunicação integrada: centraliza as mensagens no iCloud Mail e mantém notas, lembretes e históricos do navegador sempre idênticos em todas as telas do usuário;
Salvamento preventivo: realiza o backup do iPhone e iPad automaticamente via Wi-Fi, garantindo que configurações e dados de aplicativos sejam recuperados em um novo aparelho;
Segurança e localização: guarda senhas e cartões em um cofre digital criptografado e permite rastrear ou bloquear geograficamente dispositivos perdidos por meio do recurso Buscar;
Produtividade em tempo real: permite que diversas pessoas editem documentos, planilhas e apresentações simultaneamente por meio do portal web e dos apps de escritório do iWork;
Privacidade e família: bloqueia rastreadores da web e oculta o e-mail nas versões pagas, além de permitir dividir o espaço de armazenamento com até cinco familiares.
O iCloud é uma importante ferramenta para fazer backup do iPhone ou outro dispositivo da Apple (imagem: Emerson Alecrim/Tecnoblog)
Como funciona o iCloud
O iCloud opera como uma plataforma de computação em nuvem, armazenando os dados dos usuários em servidores remotos da Apple. O processo começa com o upload automático de arquivos e fotos assim que a pessoa faz login em um dispositivo da Maçã.
A partir daí, as notificações automáticas em segundo plano sincronizam todas as alterações sem a necessidade de cabos. Desse modo, qualquer informação atualizada sofre replicação imediata para outros dispositivos vinculados à mesma conta Apple ID.
Nos bastidores, o sistema garante total privacidade ao proteger os dados com criptografia em trânsito e em repouso. A segurança é reforçada pela criptografia de ponta a ponta, que gera chaves de proteção exclusivas nos próprios aparelhos.
Para reforçar a segurança do ecossistema, o iCloud utiliza a autenticação de dois fatores e chaves guardadas em módulos de hardware físicos. Até desenvolvedores terceiros podem integrar seus aplicativos nessa estrutura utilizando APIs exclusivas.
O iCloud permite sincronizar os arquivos de diferentes dispositivos da Apple (imagem: Reprodução)
Preciso ativar o iCloud?
Não é obrigatório ativar o iCloud para utilizar um aparelho da Apple, mas é altamente recomendável para não perder dados. O processo geralmente ocorre na configuração inicial do aparelho, sendo necessário criar uma conta no iCloud vinculada à Conta Apple.
Caso o recurso tenha sido pulado na configuração ou esteja desativado, basta acessar o menu de “Ajustes” e fazer o login manual a qualquer momento. Essa ativação rápida pode ser feita em múltiplos dispositivos para colocá-los em sincronia imediatamente.
O usuário mantém o controle total sobre o que vai para a nuvem, já que o sistema não obriga a sincronização de tudo. É possível personalizar cada dispositivo separadamente, escolhendo apenas os recursos e arquivos que deseja salvar na nuvem.
Os usuários ativar o iCloud para poupar espaço de armazenamento no aparelho (imagem: Igor Shimabukuro/Tecnoblog)
O iCloud é gratuito?
Sim, o iCloud oferece uma versão básica totalmente gratuita que disponibiliza 5 GB de armazenamento em nuvem. Esse espaço inicial sem custo é liberado automaticamente assim que o usuário configura seu Apple ID em qualquer dispositivo da marca.
Contudo, para quem precisa de mais espaço para fotos e backups, a alternativa é assinar o plano pago iCloud+. Esse upgrade expande o limite para até 12 TB, conforme o plano selecionado, e adiciona recursos extras de privacidade e segurança.
Como usar o iCloud
Para começar a usar o iCloud no iPhone, basta acessar o app “Ajustes”, tocar no nome do usuário no topo da tela e selecionar a opção “iCloud”. Neste menu, a pessoa escolhe quais apps e recursos, como fotos e contatos, serão sincronizados automaticamente.
No Mac, o caminho é bem parecido: clique no menu Apple, acesse “Ajustes do Sistema” e clique no nome do usuário na barra lateral. Em seguida, basta abrir o painel do iCloud para gerenciar o que deseja salvar na nuvem.
Em ambas as plataformas, o usuário consegue visualizar os arquivos salvos, gerenciar o espaço disponível ou fazer upgrade de plano. Todo o controle de downloads e exclusões de dados é feito centralizadamente e intuitivamente.
Também é possível entrar no iCloud pelo PC por meio do aplicativo oficial para Windows ou diretamente no site icloud.com pelo navegador. Essa versatilidade garante acesso rápido aos arquivos e fotos, mesmo quando a pessoa estiver longe dos dispositivos da Maçã.
O iCloud pode ser acessado pelo menu “Ajustes” do iPhone (imagem: Lupa Charleaux/Tecnoblog)
Qual é o limite de armazenamento do iCloud?
O plano gratuito do iCloud disponibiliza apenas 5 GB de armazenamento para mídias, documentos, senhas e backups de segurança. Como essa cota básica costuma esgotar rapidamente, a Apple oferece assinaturas pagas para quem precisa de mais espaço na nuvem.
Os planos do iCloud+ expandem essa capacidade, oferecendo opções que vão de 50 GB até o limite máximo de 12 TB. Além do espaço extra, os pacotes a partir de 200 GB permitem o compartilhamento familiar com até cinco pessoas.
Consigo aumentar o armazenamento do iCloud?
Sim, é possível expandir o limite migrando para o iCloud+, o serviço premium que oferece mais GB em nuvem. Para quem não quer gastar, a alternativa imediata é apagar arquivos antigos e gerenciar os backups para liberar espaço no iCloud.
Caso a limpeza não seja suficiente, o usuário pode comprar armazenamento no iCloud diretamente pelo menu do serviço em um dispositivo a qualquer momento. Esse upgrade resolve o problema de falta de memória e ainda traz ferramentas extras e compartilhamento familiar em alguns planos.
É possível expandir a memória em nuvem assinando o iCloud+ (imagem: Lupa Charleaux/Tecnoblog)
Qual é a diferença entre iCloud e iCloud+?
O iCloud é a versão gratuita da nuvem da Apple que oferece 5 GB para salvar fotos, arquivos e senhas de forma automática. Ele funciona como uma central básica para sincronizar dados e manter os aparelhos da marca em sintonia.
O iCloud+ é a assinatura premium que permite expandir esse armazenamento digital em planos que vão de 50 GB até 12 TB. Além de mais espaço, esse upgrade adiciona recursos avançados de privacidade, como navegação oculta na web e e-mails temporários.
Qual é a diferença entre iCloud e iCloud Drive?
O iCloud é a plataforma de nuvem completa da Apple que gerencia e sincroniza todo o ecossistema em segundo plano, como contatos, senhas e backups. Ele funciona como uma infraestrutura invisível que mantém o sistema operacional e seus aplicativos integrados.
O iCloud Drive é um recurso específico localizado dentro dessa nuvem, operando de forma parecida com um disco rígido virtual. É o espaço dedicado para criar pastas, organizar arquivos manualmente e compartilhá-los entre diferentes aparelhos.
Samsung Cloud deve voltar a ter armazenamento nas nuvens (imagem: reprodução/Samsung)Resumo
Samsung Cloud deve voltar a oferecer armazenamento em nuvem com planos Premium de 50 GB, 200 GB e 2 TB;
indícios surgem após confirmação de que integração nativa entre app Galeria e OneDrive acabará em setembro de 2026;
valores do Samsung Cloud Premium são equivalentes aos do iCloud+, e próximos das opções oferecidas pelo Google One.
Nesta semana, a Microsoft confirmou que a Samsung encerrará a integração do OneDrive com dispositivos Galaxy. Coincidência ou não, vieram à tona fortes indícios de que, em breve, a companhia coreana lançará uma nova versão da plataforma Samsung Cloud, com opções de armazenamento nas nuvens que vão de 50 GB a 2 TB.
Talvez você se lembre que, em 2021, o Samsung Cloud deixou de armazenar e sincronizar arquivos do usuário usando servidores próprios. Como alternativa, a companhia passou a oferecer, em celulares e tablets Galaxy, sincronização nativa com o OneDrive para backup ou recuperação de fotos e vídeos.
Com essa mudança, o Samsung Cloud continuou existindo, mas como um mero serviço de sincronização e restauração de dados entre dispositivos (como quando você recupera dados de um smartphone antigo em um aparelho novo).
Eis que, nos últimos dias, usuários de contas Samsung passaram a ser avisados de que a mencionada integração com o OneDrive será mantida somente até 30 de setembro de 2026, como mostra a imagem a seguir:
Aviso de término de integração com o OneDrive em aparelhos Galaxy (imagem: Thássius Veloso/Tecnoblog)
Note que ainda será possível usar o OneDrive para fazer backup de mídia em dispositivos Galaxy, desde que o usuário ative essa configuração no aplicativo do serviço. É o suporte direto ao OneDrive no app Galeria que deixará de existir, como a própria Microsoft explica.
Vem aí o Samsung Cloud Premium?
Provavelmente, sim. Os usuários Henrique Vitório e Igor Omena divulgaram no Threads imagens que mostram um tal de Samsung Cloud “Premium” com opções de armazenamento de até 2 TB, com preços já em reais:
50 GB: R$ 5,90 por mês
200 GB: R$ 19,90 por mês
2 TB: R$ 66,90 por mês
Além de fotos e vídeos, o novo serviço também deverá permitir armazenamento de documentos, músicas e dados de aplicativos.
Porém, o novo Samsung Cloud ainda não é oficial. A novidade foi descoberta no app do serviço por Omena com a execução de um procedimento de exploração que envolve as ferramentas Shizuku e Root Activity Launcher.
Preços da Samsung Cloud Premium (imagem: Igor Omena/Threads)
Os supostos planos do Samsung Cloud são vantajosos?
Sim, mas não em todos os cenários. Observe a seguinte tabela comparativa (os preços não consideram descontos ou promoções):
50 GB (mês)
200 GB (mês)
2 TB (mês)
Google One
R$ 4,50 (30 GB)
R$ 14,99
R$ 49,90
iCloud+
R$ 5,90
R$ 19,90
R$ 66,90
Samsung Cloud
R$ 5,90
R$ 19,90
R$ 66,90
Note que os planos do Samsung Cloud têm os mesmos preços dos pacotes oferecidos pela Apple no iCloud+.
Com relação ao Google, é importante esclarecer que não existe opção de 50 GB, mas de 30 GB (Lite). Além disso, o plano convencional de 200 GB não é oferecido para todos os usuários. Existe um plano de 200 GB que custa R$ 24,99 mensais, mas que corresponde ao Google AI Plus, com recursos de inteligência artificial. Aliás, o plano de 2 TB também faz parte do Google AI Plus.
Quando o Samsung Cloud Premium será lançado?
Ainda não há essa informação, até porque o serviço não confirmado pela Samsung até o momento. O Tecnoblog pediu informações à companhia. O texto será atualizado se obtivermos retorno.
Roteadores domésticos atuam como gateways (Imagem: Lucas Braga/Tecnoblog)
Gateway é um recurso de tecnologia que faz a intermediação e a comunicação entre sistemas com protocolos diferentes, traduzindo dados para permitir que os dispositivos se conectem e transmitam informações com segurança.
Esse recurso serve para integrar redes de computadores e até intermediar transações bancárias em lojas online, com atuação prática que pode variar de acordo com o tipo de gateway.
Em redes domésticas, por exemplo, o roteador normalmente atua como gateway entre os dispositivos da casa e a internet.
A seguir, conheça o funcionamento dessa tecnologia, os tipos e qual a utilidade de um gateway no dia a dia.
Gateway é um recurso usado na tecnologia para intermediar dois ou mais pontos com sistemas de comunicação diferentes, se tornando o elo entre dispositivos distintos durante a transferência de dados e informações.
A ferramenta é usada para traduzir os protocolos usados nesses dispositivos para uma linguagem compatível. Isso permite que sistemas desenvolvidos com tecnologias diferentes consigam trocar informações corretamente.
O que significa “gateway”?
A palavra “gateway” significa portão de entrada em tradução para o português. A ferramenta de intermediação funciona como uma ponte de transferência de dados, no contexto da tecnologia da informação.
Servidores também podem ser usados como gateway (Imagem: Divulgação/Google)
Para que serve o gateway?
Um gateway serve para viabilizar a comunicação entre dispositivos com protocolos incompatíveis. A ferramenta é responsável por traduzir esses protocolos para uma linguagem padrão, de forma que os aparelhos possam se conectar e transmitir informações entre si.
Em uma rede de computadores, por exemplo, o gateway recebe dados de um dispositivo e os encaminha para outra rede usando protocolos compatíveis. Em redes domésticas, esse papel geralmente é desempenhado pelo roteador Wi-Fi.
Essa “ponte” também é capaz de traduzir protocolos de diferentes dispositivos, como em serviços de pagamento. Nesse caso, o gateway pode validar transações bancárias, conectando serviços de pagamento, cartões de crédito e as instituições bancárias.
Outro uso bastante comum é em dispositivos IoT. Um gateway é o responsável por conectar dispositivos inteligentes que utilizam diferentes protocolos de comunicação, como lâmpadas, tomadas e sensores, de forma que o usuário possa conectá-los a um aplicativo central, por exemplo.
Como funciona um gateway
O funcionamento de um gateway varia de acordo com o tipo e a finalidade de uso. Em uma rede, ao tentar acessar um endereço web, essa comunicação passa pelo gateway, que atua como uma porta de entrada.
Ele identifica as requisições, analisa os pacotes de dados recebidos e inicia a etapa de validação para que o acesso seja realizado. Caso haja algum problema de segurança, como tráfego suspeito ou acesso não autorizado, a conexão pode ser interrompida antes da conclusão.
Um gateway de rede também pode aplicar técnicas de controle de tráfego, permitindo distribuir melhor a largura de banda entre diferentes aparelhos conectados à mesma rede Wi-Fi, sem comprometer o desempenho.
Em alguns casos, ele também atua no direcionamento das informações, escolhendo rotas mais adequadas para determinada conexão.
O modem e o roteador trabalham juntos para conectar dispositivos à internet (Imagem: Lupa Charleaux/Tecnoblog)
O funcionamento de um gateway é um pouco diferente em serviços financeiros, mas segue o mesmo conceito. A tecnologia recebe os dados de uma compra e realiza a criptografia das informações de um cartão de crédito, por exemplo.
O sistema identifica a bandeira do cartão e encaminha a transação para uma credenciadora, responsável pelo processamento de pagamentos com cartões. O gateway também aplica recursos de segurança, como criptografia e análise antifraude, para proteger os dados financeiros durante a transação.
A partir daí, o gateway recebe a resposta sobre a aprovação ou recusa do pagamento e informa o lojista sobre o resultado, centralizando a comunicação entre cliente, vendedor e instituição financeira.
Quais são os principais tipos de gateway?
Existem diferentes tipos de gateway, cada um voltado para uma necessidade de conexão e comunicação entre dispositivos:
Gateway de rede: tipo de gateway usado para oferecer a infraestrutura de conexão entre redes locais (LANs) e redes de longo alcance (WANs). A ferramenta é fundamental para o funcionamento de dispositivos na web, sendo executada por um roteador, por exemplo;
Gateway de API: tipo de gateway necessário para intermediar e gerenciar conexões a APIs de um sistema. Esse recurso permite a transferência de dados sem a necessidade de conexão direta a diferentes APIs, aumentando a segurança, o desempenho e melhorando a experiência de uso. Esse modelo é bastante usado em arquiteturas de microsserviços e plataformas em nuvem;
Gateway de pagamentos: tipo de software usado para conectar sistemas de pagamentos e transmitir informações financeiras entre lojas online, sistemas financeiros e instituições de pagamento;
Gateway de Internet das Coisas (IoT): sistema usado para conectar dispositivos inteligentes a redes ou servidores. Esses aparelhos IoT podem atuar com frequências e protocolos que os servidores em nuvem não reconhecem diretamente, necessitando da atuação de um gateway para a compatibilidade e funcionamento. Protocolos como Zigbee e Z-Wave frequentemente dependem desse tipo de gateway;
Gateway de VoIP: tipo de gateway responsável por converter sinais de voz da telefonia convencional em pacotes de dados digitais. Dessa forma, é possível fazer e receber chamadas telefônicas virtuais em dispositivos analógicos.
Quais são exemplos de uso do gateway?
Os gateways são peças fundamentais em diferentes setores da sociedade:
E-commerce: lojas online utilizam gateways de pagamento para solicitar e enviar dados bancários para as instituições bancárias de maneira criptografada. É fundamental para serviços como cartão de crédito e Pix, que necessitam da comprovação de pagamento antes do envio de um produto. Serviços como Mercado Pago e PayPal utilizam gateways para validar pagamentos online;
Redes de computadores: uso de gateway de rede para conectar todos os computadores de uma empresa que estão em rede local à internet, por exemplo. Em uma casa, o roteador geralmente atua como gateway para celulares, notebooks, smart TVs e videogames;
Automação residencial: uso de um gateway como centralizador de dispositivos inteligentes de uma casa, já que funcionam sob protocolos diferentes e necessitam de um intermediário para a automação. Os aparelhos IoT se conectam ao gateway, que envia as informações aos servidores web.
Qual é a diferença entre gateway de rede e de pagamento?
Um gateway de rede atua como um componente na infraestrutura da tecnologia, lidando com as conexões de redes de computadores com arquiteturas e protocolos distintos. Essa ferramenta permite que dispositivos conectados em uma rede local (LAN) possam se conectar à internet (rede WAN), por exemplo.
Já um gateway de pagamento é um recurso de software (API) que faz a intermediação de informações bancárias. Esse sistema faz a criptografia e envia dados de usuários às instituições financeiras para comprovar o pagamento durante a compra de um produto. É fundamental para a oferta de serviços com pagamento via cartão de crédito e Pix.
Qual é a diferença entre gateway e gateway padrão?
O gateway é uma ferramenta que conecta pontos de uma rede, atuando como um intermediário de comunicação e transferência de informações entre dispositivos com diferentes protocolos e arquiteturas. É o conceito geral da tecnologia.
Já o gateway padrão é um tipo de configuração de uma rede que determina qual o ponto de saída para o tráfego de dados.
Esse parâmetro é colocado nas configurações de todo dispositivo que pode se conectar à internet, como PCs, celulares, smart TVs e videogames. Dessa forma, se o aparelho não souber para onde enviar as informações, basta seguir os dados do gateway padrão.
Plataformas terão que remover conteúdos ilegais mesmo sem decisão judicial (foto: dole777/Unsplash)Resumo
O presidente Luiz Inácio Lula da Silva assinou dois decretos que aumentam a responsabilidade das plataformas de redes sociais.
O primeiro decreto altera a regulamentação do Marco Civil da Internet, tornando as empresas responsáveis por remover conteúdos após notificação de ilícitos.
O segundo decreto protege mulheres e meninas na internet, exigindo que as plataformas tenham um canal específico para denúncias.
O presidente Luiz Inácio Lula da Silva (PT) assinou dois decretos com novas regras para a atuação das redes sociais no Brasil. Um deles diz respeito à regulamentação do Marco Civil da Internet, dando seguimento a uma decisão tomada em 2025 pelo Supremo Tribunal Federal (STF).
Já o outro decreto traz medidas para proteção de mulheres e meninas na web, principalmente no que diz respeito a imagens de nudez, sejam reais ou geradas por inteligência artificial.
O que muda no Marco Civil da Internet?
O novo decreto altera a regulamentação do Marco Civil da Internet, que estava vigente desde 2016, para contemplar um novo entendimento.
Planalto reforçou entendimento do STF sobre o Marco Civil (foto: Roberto Stuckert Filho/Presidência da República)
Com a nova decisão da corte, as empresas passaram a ter a responsabilidade de adotar uma postura proativa para remover conteúdos ligados a terrorismo, instigação à automutilação ou ao suicídio, atos antidemocráticos, discriminação, crimes contra a mulher, crimes sexuais contra crianças e adolescentes e tráfico de pessoas.
Esses conteúdos devem ser removidos após a notificação de ilícitos, sem necessidade de ordem judicial. Os usuários devem ser informados e ter a possibilidade de contestar essas decisões.
O novo decreto transforma essa decisão do STF em uma regulamentação dentro do Marco Civil da Internet. O texto prevê que as medidas sejam aplicadas considerando o contexto das publicações, a liberdade religiosa e de crença e a finalidade informativa, educativa, de crítica, sátira ou paródia.
A nova regulamentação também define que a fiscalização será feita pela Agência Nacional de Proteção de Dados (ANPD). Vale lembrar que esse órgão foi criado originalmente para aplicar a Lei Geral de Proteção de Dados (LGPD), mas já tinha recebido a incumbência de supervisionar as medidas do ECA Digital.
O texto do decreto não para por aí. Ele prevê também que as empresas atuem para coibir fraudes digitais e anúncios enganosos. Para isso, além de moderar posts desse tipo, as companhias devem guardar dados de quem produziu esse tipo de conteúdo para facilitar processos futuros.
Em todos os casos, as big techs só serão punidas quando houver falha sistêmica — isto é, quando ficar comprovado que as empresas não tomaram medidas em larga escala para evitar esses problemas. Ainda não se sabe quais serão as penalidades.
Quais são as medidas para proteger mulheres?
Um segundo decreto foi assinado e tem como objetivo proteger mulheres e meninas contra violência na internet, principalmente no que diz respeito a conteúdos envolvendo nudez e a ataques coordenados.
As plataformas de conteúdo deverão ter um canal específico para denúncias envolvendo nudez, sejam imagens reais ou geradas por IA. Essas publicações devem ser removidas em até duas horas após a notificação.
O canal também deve indicar o 180, número telefônico da central de atendimento voltada a denúncias desse tipo.
As empresas também ficam proibidas de disponibilizar ferramentas de IA que criam imagens falsas de nudez, como os aplicativos que “retiram” roupas de mulheres usando IA. O texto ainda estipula que os algoritmos das redes sociais deverão ser programados para reduzir o alcance de ataques coordenados contra mulheres.
Google Maps permite visualizar mapeamentos antigos de determinadas regiões (Imagem: Igor Shimabukuro/Tecnoblog)
O registro histórico do Google Maps reúne mapeamentos de regiões feitos em diferentes datas. Com ele, você pode ver como era uma região em tempos passados, acompanhando as mudanças até as capturas mais recentes.
Você pode ver imagens antigas no Google Maps pelo celular ao acessar o Street View, tocar no widget com data, e escolher o ano desejado. Pelo PC, basta clicar em “Confira mais datas” e selecionar mapeamentos mais antigos.
Vale mencionar que nem todas as localidades incluem registros históricos: se o Google Maps mapeou o local somente uma vez, você só vai conseguir visualizar imagens do Street View daquele ano.
A seguir, saiba como ver fotos antigas no Google Maps pelo smartphone (Android ou iOS) ou PC.
Como ver fotos antigas no Google Maps pelo celular
1. Abra o Google Maps e pesquise o endereço desejado
Abra o aplicativo do Google Maps em seu celular (Android ou iOS). Em seguida, use o campo de busca (localizado no topo da tela) para pesquisar o endereço desejado e toque em cima da opção.
Pesquisando um endereço no Google Maps pelo celular (Imagem: Igor Shimabukuro/Tecnoblog)
2. Entre no modo Street View e toque no widget com data
Toque na foto reduzida do local para entrar no Google Street View. Feito isso, aperte no widget com data (localizado no canto superior esquerdo) para visualizar o Google Maps em anos anteriores.
Dica: se o widget não abrir nenhuma outra janela, experimente movimentar-se no Google Street View e aperte a janela novamente.
Procurando por datas mais antigas no Street View do Google Maps (Imagem: Igor Shimabukuro/Tecnoblog)
3. Selecione a data desejada mapeada pelo Google Maps
Navegue pela seção estilo carrossel para ver imagens antigas do Google Maps. Por fim, toque no ano desejado para ver como era o local na data escolhida.
Navegando no Street View do Google Maps em datas mais antigas (Imagem: Igor Shimabukuro/Tecnoblog)
Como ver imagens antigas no Google Maps pelo PC
1. Entre no site do Google Maps e busque pelo endereço
Abra o navegador de sua preferência e acesse a página google.com/maps. Feito isso, pesquise pelo endereço desejado usando o campo de busca.
Pesquisando um endereço no Google Maps pelo PC (Imagem: Igor Shimabukuro/Tecnoblog)
2. Vá na miniatura de paisagem para entrar no Street View
Clique na miniatura da paisagem do endereço para entrar no modo Street View.
Abrindo o Street View do Google Maps pelo PC (Imagem: Igor Shimabukuro/Tecnoblog)
3. Escolha “Confira mais datas” para ver datas antigas
Clique na opção “Confira mais datas” para mudar a data do Google Maps da região. Caso não encontre a opção, se movimente no modo Street View até que o recurso apareça.
Conferindo datas mais antigas do Google Street View (Imagem: Igor Shimabukuro/Tecnoblog)
4. Escolha outras datas em que o local foi mapeado
Navegue pela seção para ver ruas antigas no Google Maps. Você então poderá escolher datas antigas em que o Google mapeou o local.
Escolhendo outras datas no Google Street View (Imagem: Igor Shimabukuro/Tecnoblog)
Por que algumas cidades não possuem imagens antigas no Google Maps?
Se o Google Maps mapeou uma região específica apenas uma vez, a opção para ver datas mais antigas não estará disponível, devido à falta de registros históricos. Nesses casos, não será possível usar o Street View do Google para buscar por imagens antigas.
Também há casos em que o Google mapeou o local mais de uma vez, mas precisou excluir registros mais antigos por motivos técnicos ou por questões ligadas à privacidade de pessoas ou estabelecimentos que foram capturadas.
De quanto em quanto tempo o Google Maps atualiza as imagens?
Não existe um prazo determinado para o Google Maps atualizar suas imagens. O serviço do Google costuma fazer novos mapeamentos entre um a três anos em várias regiões do mundo, mas esse intervalo pode variar de acordo com a demanda, viabilidade e cobertura operacional.
Samsung Browser para Windows (imagem: Emerson Alecrim/Tecnoblog)Resumo
Samsung Browser foi lançado globalmente para Windows 10 e 11, com sincronização de dados entre dispositivos Galaxy;
navegador oferece bloqueador de anúncios nativo, exportação de dados de outros navegadores e integração com Samsung Pass;
recursos de IA, como integração com Perplexity, estão disponíveis apenas na Coreia do Sul e nos EUA.
O Samsung Browser (outrora chamado de Samsung Internet) foi lançado oficialmente para Windows. A novidade chega ao PC não só para disputar espaço com navegadores como Chrome e Edge, mas também para seguir a tendência de oferecer experiências com inteligência artificial.
Agora, o navegador foi lançado em escala global e pode ser usado por qualquer pessoa, gratuitamente. A novidade é compatível com o Windows 11 e com o Windows 10.
O que o Samsung Browser para PCs oferece?
Começa pela interface, que tem um visual limpo e posiciona as abas na barra de título do navegador, melhorando o aproveitamento de espaço da tela. O Samsung Browser também exibe, por padrão, uma barra lateral de acesso rápido, à direita, que pode ser ocultada.
Em termos funcionais, o navegador pergunta, já durante a instalação, se o usuário quer ativar o bloqueador de anúncios nativo. Na sequência, o usuário tem a opção de exportar dados de outro navegador previamente instalado no computador, como os já mencionados Chrome e Edge.
A barra lateral do Samsung Browser pode ser personalizada (imagem: Emerson Alecrim/Tecnoblog)
E, sim, para quem tem um celular ou tablet Galaxy, ou usa o navegador da Samsung em algum aparelho Android, é possível sincronizar os dados de navegação entre esse dispositivo e o PC. Basta fazer login com uma conta Samsung (Samsung Account). Nesse sentido, é possível até continuar acessando, no desktop, uma página que estava aberta no smartphone e vice-versa.
A integração entre dispositivos é complementada com o Samsung Pass, que permite ao usuário fazer login em sites ou serviços web com preenchimento automático de credenciais de acesso.
Sobre os recursos de inteligência artificial, o principal atrativo está na integração do Samsung Browser com os recursos do Perplexity. Com isso, o usuário pode fazer perguntas relacionadas ao conteúdo de uma página aberta, por exemplo.
Também é possível recorrer à IA para tarefas mais específicas, como montar um roteiro de viagens com base em informações de páginas abertas ou visitadas anteriormente, criar resumos de textos longos, organizar abas conforme o tema, entre várias outras possibilidades.
A Samsung dá exemplos de prompts que podem ser usados no navegador:
“resuma esta página em três tópicos”
“quais são os principais requisitos para esta vaga de emprego?”
“resuma esta conversa por e-mail e elabore uma resposta”
“crie um resumo executivo deste relatório financeiro”
“resuma este vídeo do YouTube”
Agora, pegue a toalha, pois aí vem o balde de água fria: no momento, os recursos de IA do Samsung Browser estão disponíveis somente na Coreia do Sul e nos Estados Unidos. Há planos, mas não datas para essa integração ser liberada em outros países.
Ah, para não restar dúvidas: o Samsung Browser é baseado no Chromium.
Samsung Browser pode ser sincronizado com outros dispositivos (imagem: Emerson Alecrim/Tecnoblog)
Plataforma Small Web, da Kagi, reúne sites autorais (imagem: divulgação)Resumo
O projeto Small Web da Kagi destaca páginas autorais e independentes, fugindo de algoritmos e IA.
A iniciativa agora inclui apps para iPhone e Android e extensões de navegador.
A Kagi mantém o projeto aberto a contribuições no GitHub.
O avanço da inteligência artificial tem transformado a forma como conteúdos são produzidos e distribuídos na internet. Em resposta a esse cenário, a Kagi decidiu reforçar uma proposta alternativa: destacar páginas independentes, criadas por pessoas, dentro do que chama de Small Web.
A iniciativa começou em 2023, mas agora ganha novos formatos, incluindo apps para celular e extensões de navegador. A Kagi, vale lembrar, é uma startup de tecnologia dona de um buscador próprio, focado em privacidade.
Com o projeto Small Web, a ideia é facilitar o acesso a conteúdos menos comerciais, como blogs pessoais, webcomics e projetos autorais — tipos de site que marcaram os primórdios da internet, mas que hoje competem com plataformas dominadas por grandes empresas e conteúdos automatizados.
O que é o Small Web?
Na definição da Kagi, a Small Web reúne páginas criadas por indivíduos, com foco em produção original e não comercial. O projeto organiza mais de 30 mil sites, permitindo que usuários descubram conteúdos fora dos algoritmos tradicionais.
Uma das principais ferramentas é um sistema de navegação aleatória, que exibe um site por vez e permite avançar para outro com um clique, em um modelo semelhante ao do StumbleUpon. A proposta é incentivar a exploração de conteúdos que dificilmente apareceriam em buscas convencionais.
Agora, a plataforma foi expandida para extensões de navegador e apps para iPhone e Android. A Kagi também adicionou novas categorias de conteúdo, como vídeos, blogs, quadrinhos ou repositórios de código. Os aplicativos oferecem histórico de navegação, lista de favoritos e modo de leitura sem distrações.
Web autoral ou nostalgia?
Categorias da Small Web, iniciativa da Kagi para valorizar a internet autoral (imagem: divulgação)
A tentativa de valorizar a chamada web independente surge em um momento em que conteúdos automatizados ganham espaço. Ainda assim, a abordagem da Kagi não passa sem críticas.
Em discussões no Hacker News, usuários apontam limitações no projeto. Um dos pontos levantados é o critério de seleção: apenas sites com feeds RSS ativos e atualizados são incluídos, o que exclui páginas experimentais ou projetos pontuais.
Outro questionamento envolve a curadoria. Há relatos de sites listados que levantam dúvidas sobre a real autoria humana, o que contraria a proposta central da iniciativa.
Ainda assim, para a Kagi, a Small Web também funciona como um diferencial estratégico em sua tentativa de competir com buscadores tradicionais. O projeto segue aberto a contribuições por meio da página oficial da iniciativa no GitHub.
Projeto foge dos algoritmos e da IA para destacar páginas autorais na internet. Iniciativa agora inclui apps para iPhone e Android e extensões de navegador.
Plataforma Small Web, da Kagi, reúne sites autorais e permite descoberta por categorias (imagem: divulgação/Kagi)
Saiba como funciona a estrutura de conceitual de rede desenvolvida pela ISO (imagem: Reprodução/ExpressVPN)
O modelo OSI organiza a comunicação entre sistemas usando sete camadas distintas e independentes. Desenvolvida pela ISO, essa arquitetura de rede permite que sistemas diferentes interajam de forma padronizada, do hardware ao software.
As camadas são: aplicação, apresentação, sessão, transporte, rede, enlace de dados e física, cada uma com funções específicas para garantir o fluxo de dados. Essa estrutura modular simplifica o desenvolvimento de protocolos e torna o diagnóstico de problemas na rede muito mais ágil e eficiente.
A seguir, entenda o conceito do modelo OSI e as funções de cada uma das sete camadas. Também saiba os pontos fortes e fracos da estrutura conceitual de redes.
O modelo OSI é uma estrutura conceitual de sete camadas que padroniza a comunicação entre sistemas heterogêneos, garantindo a interoperabilidade de rede. Desenvolvido pela ISO (Organização Internacional de Padronização), ele facilita a criação de protocolos e resolução de falhas ao isolar funções específicas, do hardware ao software.
O que significa OSI?
OSI é a sigla para Open System Interconnection (Interconexão de Sistemas Abertos, em português). O termo foi criado pela ISO para padronizar a comunicação de rede e resolver a incompatibilidade entre sistemas proprietários na década de 1970.
A origem remonta ao projeto de Hubert Zimmermann em 1978, resultando na norma ISO 7498 de 1984. Basicamente, ela visa garantir a interoperabilidade universal e o intercâmbio de dados em camadas.
O modelo OSI traz as bases teóricas para o funcionamento de uma rede interconectada (imagem: Reprodução/Shardeum)
Qual é a função do modelo OSI?
O modelo OSI funciona como uma estrutura conceitual que divide o processo de rede em sete camadas para padronizar a comunicação global. Ele permite a interoperabilidade entre diferentes tecnologias e facilita diagnósticos ao isolar falhas em níveis específicos do sistema.
Por meio do encapsulamento, o modelo de referência organiza a trajetória dos dados, garantindo que cada etapa tenha funções e protocolos bem definidos. Essa modularidade promove a inovação tecnológica independente, permitindo atualizações em uma camada sem impactar o funcionamento das demais.
Quais são as camadas do modelo OSI?
O modelo OSI organiza a comunicação de rede em sete camadas: aplicação, apresentação, sessão, transporte, rede, enlace de dados e física. Essa estrutura na ordem invertida, do 7 ao 1, padroniza como os dados são encapsulados e transmitidos desde a interface do usuário até os bits no meio físico.
Veja a função de cada uma das sete camadas do modelo OSI:
7. Camada de aplicação
A camada de Aplicação é o sétimo nível do modelo OSI, servindo de interface entre o software do usuário e a infraestrutura de rede. Ele não representa o aplicativo em si, mas fornece os protocolos necessários para que programas iniciem a comunicação externa.
Sua função é identificar parceiros de comunicação e sincronizar a transferência de dados, garantindo a disponibilidade de recursos necessários. Por meio de protocolos como HTTP e SMTP, ela traduz as solicitações do usuário em processos de rede compreensíveis pelo sistema.
6. Camada de apresentação
Sexto nível do modelo OSI, a camada de Apresentação atua como tradutor, convertendo dados entre formatos de aplicação e sintaxes de rede universais. Ela garante a interoperabilidade ao padronizar a condição das informações, tornando-as compreensíveis para diferentes hardwares e sistemas operacionais.
Sua função é o tratamento dos dados por meio da criptografia para segurança, compressão para otimizar a largura de banda e a formação de arquivos. Localizada entre as camadas de Aplicação e Sessão, ela assegura que a mensagem enviada seja perfeitamente interpretada pelo destinatário.
Na camada de Apresentação, linguagens como o HTML estruturam os dados para que eles sejam visualizados em diferentes hardwares e sistemas operacionais (imagem: Reprodução/FreePik)
5. Camada de sessão
A camada de Sessão, ou camada 5, é responsável por estabelecer, coordenar e encerrar os diálogos entre aplicações em diferentes dispositivos. Ela atua como um tradutor de sessões, garantindo que a comunicação permaneça ativa e organizada durante toda a troca de informações.
Suas funções incluem o controle de diálogo (simplex, half-duplex ou full-duplex) e a inserção de pontos de sincronização para recuperação de falhas. Isso permite retomar transmissões interrompidas sem reiniciar o processo do zero, gerenciando protocolos fundamentais como o SIP e o NetBIOS.
4. Camada de transporte
A camada de Transporte, a quarta do modelo OSI, gerencia a comunicação de ponta a ponta, segmentando dados em unidades menores e controlando o fluxo para evitar gargalos. Ela usa protocolos como o TCP, focado em integridade e retransmissão, ou o UDP, priorizando a baixa latência e velocidade.
Atuando como ponte lógica, ela emprega o endereçamento por portas para direcionar o tráfego a processos específicos e garantir a remontagem correta das mensagens. Essa camada isola as aplicações superiores das complexidades da rede física, assegurando que os dados cheguem organizados e sem erros.
Protocolos como TCP atuam na camada de transporte, segmentando os dados e realizando o endereçamento das informações (Imagem: jenniki/Vecteezy)
3. Camada de rede
A camada de Rede, o terceiro nível do modelo OSI, gerencia o endereçamento lógico e o roteamento de pacotes, usando o protocolo IP para conectar diferentes redes. Ela determina o melhor caminho para os dados por meio de roteadores, garantindo que a informação saia da origem e alcance o destino correto.
Além de selecionar rotas otimizadas, esta camada fragmenta dados para compatibilidade entre redes e usa o ICMP para reportar erros e diagnósticos. Ela é fundamental para a comunicação global, permitindo que dispositivos em segmentos físicos distintos troquem informações de maneira eficiente.
2. Camada de enlace de dados
Segundo nível do modelo OSI, a camada de Enlace garante a transferência confiável de dados em um link físico, organizando pacotes em quadros (frames) para tráfego em redes locais. Ela usa o endereçamento MAC para identificação de hardware e implementa o controle de fluxo para evitar o congestionamento do receptor.
Sua função abrange a detecção de erros via somas de verificação e a gestão de acesso por meio das subcamadas MAC e LLC. Ao interligar os níveis Físico e de Rede, ela assegura a integridade da comunicação e a coordenação precisa entre dispositivos adjacentes.
1. Camada física
A Camada Física é o nível primário do modelo OSI, responsável pela transmissão de bits brutos por meios de conexão. No setor de Telecom, por exemplo, ela converte dados digitais em sinais elétricos, ópticos ou eletromagnéticos para o transporte físico.
Sua função é padronizar interfaces de hardware, conectores e especificações elétricas, operando sem o tratamento lógico de erros. Esta base garante que o fluxo de energia represente fielmente a informação para as camadas superiores.
A Camada Física é reponsável por padronizar interfaces, como conectores (imagem: Vitor Pádua/Tecnoblog)
Quais são as vantagens do modelo OSI?
Estes são os pontos fortes do modelo de referência OSI:
Modularidade e independência: permite que desenvolvedores modifiquem ou atualizem protocolos em uma camada específica sem impactar o funcionamento das demais camadas do sistema;
Facilidade na resolução de problemas: agiliza o diagnóstico de falhas ao isolar problemas em níveis específicos, permitindo identificar rapidamente se o erro é de hardware, roteamento ou software;
Interoperabilidade global: padroniza a comunicação entre dispositivos de diferentes fabricantes, garantindo que equipamentos de marcas distintas trabalhem juntos em uma mesma rede;
Padronização didática: serve como uma linguagem universal e teórica que orienta o ensino de redes e a criação de novas tecnologias de forma estruturada e lógica;
Escalabilidade e flexibilidade: oferece suporte a diversos tipos de serviços e protocolos, adaptando-se facilmente a mudanças tecnológicas sem a necessidade de reestruturar toda a rede.
Quais são as desvantagens do modelo OSI?
Estes são os pontos fracos da estrutura conceitual do modelo OSI:
Complexidade: a divisão em sete camadas exige processamento excessivo de cabeçalhos e encapsulamento, tornando as implementações mais lentas e pesadas;
Camadas subutilizadas: as camadas de Sessão e Apresentação possuem funções pouco expressivas na prática, sendo frequentemente ignoradas ou absorvidas por outras camadas;
Funções duplicadas: mecanismos de controle de erros e fluxo repetem-se em diferentes níveis, como Enlace e Transporte, gerando gasto desnecessário de recursos;
Interdependência rígida: a estrutura sequencial impede o processamento paralelo e dificulta ajustes em uma camada sem impactar o funcionamento das camadas adjacentes;
Incompatibilidade temporal: foi finalizado após o TCP/IP já estar consolidado no mercado, o que restringiu sua aplicação ao campo teórico e educacional como um modelo de referência.
O modelo TCP/IP se tornou a principal alternativa para o modelo OSI, sendo essencial para o funcionamento da Internet (Imagem: Vitor Pádua/Tecnoblog)
Existem alternativas ao modelo OSI?
Sim, embora o modelo OSI seja a referência teórica padrão, a evolução tecnológica consolidou outras opções de arquitetura de rede mais alinhadas às necessidades de desempenho e escalabilidade atuais:
TCP/IP: é a arquitetura de rede dominante na prática, que simplifica as sete camadas OSI em quatro níveis focados na conectividade real da internet;
Modelo híbrido: une a clareza didática das camadas físicas do OSI com a eficiência do TCP/IP, servindo como a arquitetura de rede padrão em ambientes acadêmicos modernos;
Modelo de camadas recursivas (RINA): opção baseada na repetição de uma única camada programável, eliminando a redundância e os gargalos de segurança do modelo tradicional;
Redes definidas por software (SDN): abstrai o controle do hardware, criando uma arquitetura centralizada onde o software gerencia o tráfego de forma dinâmica, independente de camadas rígidas;
Service Mesh (Malha de Serviços): foca na comunicação entre microsserviços em nuvem, estabelecendo uma arquitetura lógica que gerencia segurança e tráfego sem depender da infraestrutura física.
Qual é a diferença entre modelo OSI e protocolo TCP/IP?
O modelo OSI é uma referência teórica de sete camadas, desenvolvida para padronizar e organizar as funções de comunicação em rede modularmente. Ele serve como base para o ensino acadêmico, detalhando etapas específicas que não são necessariamente seguidas de forma rígida em arquiteturas atuais.
O TCP/IP é uma arquitetura prática de quatro camadas que consolida funções de rede para otimizar a transmissão real de dados em ambientes digitais. Diferente do OSI, este modelo é o padrão tecnológico que efetivamente sustenta a infraestrutura global da Internet moderna e a comunicação entre dispositivos.
O FTP é um protocolo que permite o compartilhamento de arquivos entre dispositivo-servidor em rede local ou na web.
A tecnologia foi desenvolvida em 1971 e foi fundamental para o desenvolvimento da internet que conhecemos, visto que possibilitou a criação de sites e a transferência de informações de forma prática.
A seguir, entenda como funciona o Protocolo, sua origem e quais são as principais aplicações da tecnologia.
FTP é uma tecnologia que permite transferir arquivos em rede (Imagem: Vitor Pádua/Tecnoblog)
FTP é um protocolo de rede que define regras para transferência de arquivos via internet ou em rede local. O Protocolo de Transferência de Arquivos (FTP) permite enviar e baixar arquivos entre cliente-servidor, sendo útil no gerenciamento de servidores ou de backups em sites da internet, por exemplo.
Além disso, esse protocolo é útil também na transferência de arquivos grandes entre usuários ou sistemas, visto que garante maior estabilidade e não impõe limites de tamanho.
O que significa FTP?
FTP significa “File Transfer Protocol”, ou Protocolo de Transferência de Arquivos, em tradução para o português.
Qual é a origem do FTP?
O FTP teve origem em 1971, pelo estudante de engenharia elétrica do MIT (Instituto de Tecnologia de Massachusetts), Abhay Bhushan. O Protocolo foi criado ainda na ARPANET para permitir a transferência de arquivos de forma mais prática, na época, entre universidades e institutos de pesquisa.
O primeiro FTP operava sobre o NCP (Network Control Program), que era o protocolo de comunicação para redes de computadores da época, tendo maior foco em arquivos do que em rede.
Posteriormente, Jon Postel e Joyce K. Reynolds desenvolveram ainda mais a tecnologia, passando a utilizar TCP/IP como base da comunicação do FTP.
Essa transição aumentou a confiabilidade na transmissão de arquivos, implementou verificação de erros, além de separar a arquitetura em duas conexões distintas: porta 21 para o controle das informações e porta 20 para a transferência dos arquivos.
Abhay Bhushan criador do FTP (Imagem: Hagop’s Photography )
Como o FTP funciona?
O funcionamento do FTP é feito a partir da conexão entre cliente e servidor. O FTP usa um servidor como responsável por hospedar os arquivos. O cliente é o usuário que fará o acesso. A conexão é sempre autenticada com nome de usuário e senha, enquanto o servidor é geralmente acessado por um endereço de IP.
A partir daí, o cliente envia comandos ao servidor para movimentar arquivos. Caso use o modo ativo, quando um arquivo for transferido, o servidor abre uma conexão de volta para o dispositivo que fez a solicitação. Já no modo passivo, o cliente pede para o servidor abrir uma porta antes de fazer a transferência dessas informações.
Qual porta o FTP utiliza?
O FTP usa a porta 21 como padrão para a autenticação e controle de informações, como o envio de comandos ou a navegação entre pastas. A porta 20 do Protocolo é usada no modo ativo, sendo por onde o arquivo é transferido, de fato. Já no modo passivo as portas são dinâmicas, ou seja, mudam a cada uso.
Quais são os modos de operação do FTP?
O FTP opera em modo ativo e modo passivo. Conheça as peculiaridades de cada modo abaixo:
Modo ativo: o servidor abre uma conexão quando faz a solicitação para a transferência de arquivos a partir da porta 20. O cliente recebe a solicitação e inicia a conexão entre cliente-servidor. O modo ativo está sujeito a bloqueios de firewalls por questões de segurança, já que a conexão vem de fora para dentro do dispositivo do usuário;
Modo passivo: o cliente abre uma conexão e solicita a abertura de portas do servidor antes de iniciar a transferência dos arquivos. O servidor abre uma porta aleatória para receber a conexão, permitindo que o cliente se conecte para fazer a operação. Pelo modo passivo, é mais dificil que firewalls façam o bloqueio, visto que as conexões são iniciadas pelo cliente e não pelo servidor.
Quais são as aplicações do FTP?
O FTP tem diversas aplicações na internet. Conheça as principais.
Transferência de arquivos: o FTP permite transferir arquivos entre servidores e dispositivos, principalmente arquivos pesados;
Sistemas de segurança: câmeras de segurança usam a conexão FTP para enviar fotos e vídeos de forma automática para os servidores;
Backups: sistemas de automatização de backups usam a conexão FTP para enviar arquivos de forma ágil e prática, armazenando arquivos importantes automaticamente em servidores;
Atualização de dispositivos: equipamentos industriais, roteadores e outros dispositivos de conexão também podem usar o Protocolo de Transferência de Arquivos para enviar atualizações de firmware automaticamente;
Publicação de sites: desenvolvedores de websites utilizam a conexão FTP para enviar códigos de programação, bancos de dados e arquivos de mídia de forma ágil e automatizada;
Câmeras de vigilância são exemplos de uso do FTP (imagem: reprodução/Freepik/onlyyouqj)
Quais são as vantagens do FTP?
Apesar dos problemas de segurança, o FTP tem algumas vantagens em comparação com outros protocolos de transferência de arquivos:
Transferência de grandes volumes de dados: o FTP é um protocolo capaz de transferir arquivos pesados, além da possibilidade de enviar vários arquivos de uma vez;
Baixo processamento: o FTP exige pouco processamento para enviar e receber arquivos, diferente de outros protocolos, como SFTP;
Alta compatibilidade: o FTP é um dos protocolos mais universais existentes, devido ao seu tempo de uso. Dispositivos legados ou sistemas operacionais antigos podem ter melhor desempenho.
Quais são as desvantagens do FTP?
O FTP tem uma série de desvantagens que fazem seu uso ser desencorajado:
Falta de verificação de integridade: o FTP não é capaz de verificar a integridade dos arquivos transferidos. Ou seja, a conexão não reconhece e não garante que os arquivos enviados cheguem como deveria;
Baixa segurança: o FTP é um protocolo de baixa segurança, já que os dados enviados podem ser interceptados pela falta de criptografia. Dessa forma, senhas de acesso podem ser visualizadas por quem tiver acesso à rede;
Problemas de gerenciamento: o FTP pode ser um protocolo lento no envio de diversos arquivos simultaneamente, visto que a conexão necessita abrir e fechar portas individualmente para conclusão da operação.
É seguro usar FTP para transferir arquivos?
Não. O FTP não conta com uma série de padrões de segurança suportados pelos navegadores de internet modernos, embora seja possível implementar o protocolo SSL (FTPS) para prover conexões mais seguras.
Dessa forma, prioriza-se o uso de SFTP que executa sobre o protocolo Secure Shell (SSH).
Quais são os riscos do FTP?
O File Transfer Protocol oferece os seguintes riscos para quem o utiliza:
Vazamento de informações: como o FTP não possui nenhuma camada de segurança, qualquer dispositivo que esteja no caminho entre os arquivos que estão sendo transferidos podem interceptar as informações;
Injeção de malwares: o FTP não possui mecanismos para verificar a integridade dos arquivos transferidos. Dessa forma, um ataque Man-in-the-Middle (MITM) pode interceptar dados, modificar informações e inserir códigos maliciosos;
Roubo de identidade: para transferir arquivos via FTP é necessário digitar uma senha, que não é criptografada. Um invasor é capaz de conseguir acessar a rede e roubar as informações de acesso digitadas pelo usuário;
Descumprimento da LGPD: usar a conexão FTP para transferir arquivos de terceiros pode descumprir a Lei Geral de Proteção de Dados. O artigo 46 da Lei exige: “Os agentes de tratamento devem adotar medidas de segurança, técnicas e administrativas aptas a proteger os dados pessoais de acessos não autorizados e de situações acidentais ou ilícitas de destruição, perda, alteração, comunicação ou difusão”;
Bounce Attack: o Bounce Attack em conexões FTP acontece quando um invasor usa um servidor vulnerável como intermediário para enviar dados para outro dispositivo.
Qual é a diferença entre FTP, FTPS e SFTP?
FTP significa File Transfer Protocol, ou seja, é um protocolo de transferência de arquivos usado para enviar e receber informações entre cliente-servidor.
Já FTPS é o mesmo protocolo, tendo uma camada de segurança adicional para proteger o sigilo e a integridade dos arquivos. No entanto, pode ser um pouco mais complexo de ser configurado, em comparação com o FTP comum.
O SFTP também é um protocolo de transferência de arquivos, mas baseado em SSH como canal de comunicação. Esse tipo de protocolo é amplamente usado em sistemas que exigem uma segurança ainda maior, apesar de ter um maior custo computacional.
Qual é a diferença entre FTP e TCP/IP?
O FTP é um protocolo de transferência de arquivos que usa o TCP/IP como base da comunicação para mover arquivos entre cliente e servidor.
Exemplo de um cabo de rede usado para conexão (imagem: Emerson Alecrim/Tecnoblog)
Uma rede de computador é uma tecnologia que permite o compartilhamento de informações entre usuários. É a partir dessas redes que dados são transmitidos entre cliente-servidor ou empresas armazenam informações que podem ser acessadas por funcionários, por exemplo.
Podemos dividir redes de computadores por tipos e categorias. Existem redes de alcance geográfico, outras que têm funcionalidades diferentes e até mesmo separá-las por arquitetura de desenvolvimento.
A internet é a principal rede WAN usada no mundo, por exemplo. A seguir, conheça detalhes sobre cada tipo de computer network e veja exemplos do dia a dia.
Redes de computadores são infraestruturas que possibilitam a troca de informações e conexão entre dispositivos variados, como celulares e servidores, por exemplo.
Utilizam meios físicos ou sem fio para a transferência de dados a partir de uma padronização de rede. As redes de computadores são usadas no dia a dia, desde infraestruturas pessoais até a conexão entre filiais de grandes empresas e cidades.
Quais são os tipos de redes de computadores?
As redes de computadores podem ser classificadas em três categorias: por alcance geográfico, por topologia ou arquitetura e por natureza ou funcionalidade. Cada tipo de rede de computador tem uma finalidade específica na sociedade.
Redes de alcance geográfico são classificadas de acordo com a distância física de cobertura. Topologia e arquitetura diz respeito à estrutura de organização da rede, já a divisão por funcionalidade classifica redes de computadores por propósito de uso.
Conexão WAN e LAN, exemplos de rede de alcance geográfio (imagem: Emerson Alecrim/Tecnoblog)
Alcance geográfico
As redes de computadores de alcance geográfico são aquelas que operam em diferentes distâncias, de acordo com a necessidade. Existem redes pessoais, locais, de longa distância e até usadas em grandes metrópoles. A internet que conhecemos é um exemplo de rede de longa distância, conectando diversos países de todo o mundo.
Topologia ou arquitetura
As redes de computadores também podem ser separadas por arquitetura, definindo a hierarquia e como os serviços são prestados. Podemos definir a interação cliente-servidor e P2P como redes de computadores desta categoria.
Natureza ou funcionalidade
Pode-se também dividir as redes de computadores por natureza ou funcionalidade. Redes intranet, extranet e internet são alguns dos exemplos de categorização. Também podemos incluir as VPNs e as SANs, usadas para armazenamento de grandes volumes de dados.
Quais são as redes de computadores baseadas em alcance geográfico?
As redes WAN, LAN, PAN, MAN e CAN são exemplos de redes de computadores de alcance geográfico. Cada um dos tipos é baseado no tamanho da operação, sendo algumas mais pessoais e locais, e outras mais amplas com alcance intercontinental. Conheça as peculiaridades de cada rede abaixo.
Wide Area Network (WAN)
A rede de longa distância (WAN), do inglês Wide Area Network, é uma tecnologia que conecta computadores em uma grande área de abrangência, como cidades, estados ou países. Esse tipo de rede faz a conexão de diversas redes locais (LAN), permitindo o compartilhamento de informações e dados entre dispositivos conectados.
As redes de longa distância surgiram em 1965, conectando computadores em dois estados dos Estados Unidos da América.
Com o passar do tempo, o crescimento das redes WAN se tornou fundamental para o compartilhamento de informações entre empresas de diferentes localidades, e usuários domésticos com computadores pessoais. Exemplos de rede WAN: internet, redes corporativas, caixas eletrônicos.
Local Area Network (LAN)
A rede de área local (LAN), do inglês Local Area Network, é uma tecnologia que conecta dispositivos em uma pequena área, como uma casa, apartamento ou edifício, por meio de fios. O funcionamento das redes LAN é feito por meio de roteadores ou switches, conectando computadores em uma mesma rede.
As primeiras redes de área local (LAN) foram desenvolvidas no final da década de 1970 para atender a necessidade de universidades e laboratórios de pesquisa. A tecnologia se popularizou e passou a ser utilizada no ramo empresarial e doméstico, para a troca de arquivos ou informações entre dispositivos de uma mesma localidade.
Personal Area Network (PAN)
A rede de área pessoal (PAN), do inglês Personal Area Network, é uma rede que permite conectar dispositivos que estiverem próximos um do outro, podendo ser com fio ou sem fio.
Diferente das redes de área local, as redes PAN não se conectam diretamente à internet. Porém, dispostivos dentro de uma rede PAN podem se conectar com redes LAN ou WLAN. Exemplos de rede PAN: Bluetooth, USB e Thunderbolt.
Metropolitan Area Network (MAN)
A rede de área metropolitana (MAN), do inglês Metropolitan Area Network, é uma tecnologia utilizada em grandes centros, como metrópoles, porém com área de abrangência menor do que as redes de longa distância (WAN).
O funcionamento das redes MAN é feito por diversas redes LAN conectadas, muitas vezes por cabos de fibra óptica. As redes MAN podem ser utilizadas para conectar escritórios de empresas em bairros ou cidades próximas, por provedores de internet local, além de centros universitários.
Campus Area Network (CAN)
A rede de área de campus (CAN), do inglês, Campus Area Network, é a infraestrutura que conecta uma série de redes locais (LAN) em uma área específica, como os campi universitários, industrias, corporações e até mesmo bases militares.
Esse tipo de rede usa conexão própria, possuindo todos os equipamentos necessários para funcionamento, sem depender de provedores externos.
Quais são as redes de computadores baseadas em topologia ou arquitetura?
Redes de característica cliente-servidor e P2P (Peer-to-peer) são exemplos de infraestruturas baseadas em arquitetura. Entenda as características de cada rede a seguir.
P2P
A rede P2P (peer-to-peer) é uma rede de computador na qual não existe uma hierarquia, visto que todos os dispositivos conectados são considerados pares, mantendo as mesmas responsabilidades e funcionalidades.
Cada computador é, ao mesmo tempo, cliente e servidor, aumentando a resistência a falhas, por exemplo. Tecnologias como torrent e blockchain, no uso de criptomoedas, são exemplos de redes P2P.
Cliente-servidor
Cliente-servidor é o modelo mais comum de rede de computador. Esse tipo de rede separa as responsabilidades, sendo o servidor o responsável por fornecer informações, serviços e aplicações.
Já o cliente é o dispositivo usado pelo usuário, como smartphones, tablets e PCs, que solicita as informações do servidor. Grande parte do que vemos na internet usa este modelo, seja no uso de redes sociais ou streaming de vídeo, por exemplo.
Quais são as redes de computadores baseadas em natureza ou funcionalidade?
Também é possível dividir as redes de computadores por funcionalidade, sendo algumas públicas, outras privadas e até mesmo usadas no armazenamento de informações como uma Storage Area Network (SAN), por exemplo.
Virtual Private Network (VPN)
Uma rede privada virtual (VPN), do inglês Virtual Private Network, é uma tecnologia de conexão que permite aos usuários acessarem redes privadas e compartilharem dados pela internet de forma segura.
Um dos principais propósitos das VPNs é permitir que colaboradores e dispositivos de uma empresa acessem a rede interna da sede de qualquer lugar do mundo. Isso é feito por meio da internet, sem a necessidade de uma conexão física dedicada entre os pontos de acesso.
Já no uso doméstico, a VPN costuma ser usada para acessar a internet por meio de uma rede diferente da usada normalmente. Esse tipo de conexão é útil para se conectar a servidores de VPN localizados em outros países, por exemplo.
Aplicativo de VPN para celular (Imagem: Divulgação/Surfshark)
Rede pública
Uma rede de computador pública é aquela na qual qualquer usuário pode se conectar, desde que esteja sem senha ou funcione por meio de cadastro prévio. As redes públicas são consideradas menos seguras do que as redes privadas, já que qualquer usuário pode ter acesso.
É comum que supermercados, shoppings e aeroportos ofereçam redes públicas para clientes. Alguns estabelecimentos, porém, exigem que o usuário faça o cadastro com dados pessoais para ter acesso à conexão.
Rede privada
Uma rede privada exige senha para ter acesso à conexão com a internet. Esse tipo de rede de computador é mais segura que as redes públicas, visto que é possível ter controle sobre quem acessa as informações, além do uso de protocolos adicionais de segurança. Wi-Fi doméstico, redes corporativas e VPNs são alguns exemplos de redes privadas.
Storage Area Network (SAN)
A rede de área de armazenamento, do inglês Storage Area Network, é uma tecnologia que permite armazenar dados em rede, conectando servidores, software e serviços de uma organização. Dessa forma, é possível ter um espaço dedicado a uma grande quantidade de dados, aprimorando o gerenciamento dessas informações.
O uso da rede SAN é comum em bancos de dados, sistemas empresariais como SAP e ERP, além de empresas de e-commerce.
Qual é a diferença entre as redes WAN, MAN e LAN?
A rede WAN é capaz de conectar diversas pessoas ao redor do mundo através da internet. Esse tipo de conexão é a que abrange uma maior área de conexão entre todas as redes existentes, sendo feita a partir de diversas redes LAN ou WLAN conectadas.
Uma rede LAN permite conectar apenas dispositivos que estejam sob uma mesma rede, seja com fio ou sem fio, como computadores, tablets ou smartphones.
Já uma rede MAN permite a conexão de aparelhos que estejam em uma área do tamanho de uma metrópole, como bairros e cidades.
Enquanto a rede WAN conecta pessoas em todo o mundo e a rede LAN conecta dispositivos sob uma mesma rede, a rede MAN é usada por empresas que possuem filiais próximas e provedores locais de internet, por exemplo.
Qual é a diferença entre rede pública e rede privada?
Rede pública é um tipo de rede de computador que pode ser acessada por qualquer usuário, sem a exigência de uma senha. Pela falta de necessidade de credenciais, sua segurança é menor em comparação com as redes privadas.
Já uma rede privada é aquela na qual o administrador consegue controlar quem tem acesso. Redes corporativas, domésticas ou servidores são exemplos de redes privadas, visto que exigem senha para ter acesso às informações.
Google Play Store começa a alertar sobre apps que drenam a bateria (imagem: reprodução/Google)Resumo
Google Play Store passou a exibir alertas sobre consumo excessivo de bateria por aplicativos;
aviso aparece se o app acumular duas horas ou mais de bloqueios de ativação em 24 horas ou superar limite em 5% das sessões durante os últimos 28 dias;
iniciativa visa alertar usuários e incentivar desenvolvedores a otimizar consumo de energia pelos aplicativos.
Não estranhe se você abrir a página de um aplicativo na Google Play Store e se deparar com um aviso de fundo vermelho informando que aquele app demanda muita bateria. Neste mês de março de 2026, a loja de aplicativos para Android passou a exibir esse tipo de alerta oficialmente, ainda que de modo gradual.
“Este aplicativo pode usar mais bateria do que o esperado”
Na Google Play Store, o alerta aparece na parte superior, logo abaixo dos selos informativos do aplicativo. O aviso diz o seguinte (em tradução livre):
Este aplicativo pode usar mais bateria do que o esperado devido a uma atividade elevada em segundo plano.
É neste ponto que a tal métrica vital do Android fica mais compreensível. Ela é baseada em um parâmetro que mede o excesso de “bloqueios parciais de ativação”, que impedem o celular ou tablet de entrar em modo de descanso mesmo quando a tela está bloqueada ou apagada.
Aviso da Google Play Store sobre app que demanda muita bateria (imagem: reprodução/Google)
Obviamente, essas circunstâncias elevam o consumo de energia pelo dispositivo. Diante disso, o app poderá ser sinalizado na Play Store se acumular duas horas ou mais de bloqueios de ativação em um período de 24 horas dentro de uma única sessão do usuário, ou se o limite for superado em 5% das sessões nos últimos 28 dias.
Além de exibir um alerta sobre demanda excessiva de bateria, a Google Play Store poderá diminuir os destaques ou as recomendações do aplicativo problemático.
Na prática, a iniciativa tem dois objetivos: o primeiro é alertar o usuário sobre apps que podem “drenar” a bateria de seu dispositivo móvel, obviamente; o segundo é incentivar os desenvolvedores a otimizarem seus aplicativos no aspecto do consumo de energia. Instruções iniciais para isso estão no blog para desenvolvedores do Android.
Operação Provedor Legal prendeu seis pessoas (imagem: reprodução/Anatel)Resumo
Anatel e forças policiais realizaram a Operação Provedor Legal em todo o país, visando provedores clandestinos de internet.
Do total, 52% dos provedores inspecionados eram ilegais, resultando em 15 empresas autuadas e seis pessoas presas.
As autoridades apreenderam R$ 200 mil em infraestrutura irregular, incluindo mais de 500 metros de cabos furtados.
A Anatel, em conjunto com as polícias Federal, Civil e Militar, deflagrou nesta quinta-feira (05/03) a Operação Provedor Legal. De âmbito nacional, a iniciativa mira empresas que comercializam banda larga fixa de forma clandestina.
Seis representantes de provedores piratas foram presos em flagrante e levados à sede da Polícia Federal. Eles responderão criminalmente pelo delito de desenvolvimento clandestino de atividades de telecomunicações, previsto no artigo 183 da Lei Geral de Telecomunicações.
A ação busca desarticular provedores clandestinos que prejudicam tanto a infraestrutura nacional quanto a concorrência no mercado de telecomunicações. O balanço oficial da agência mostra a dimensão do problema: mais da metade dos alvos operava fora da legalidade.
Segundo os fiscais, 52% dos provedores inspecionados eram clandestinos. Como resultado do pente-fino, 15 empresas foram autuadas por prestarem serviços de internet sem outorga (a licença exigida por lei) e por utilizarem roteadores e antenas sem homologação da Anatel.
O que foi apreendido na operação?
Mais da metade dos alvos visitados pelos agentes operava de forma clandestina (imagem: reprodução/Anatel)
Durante as buscas, as autoridades confiscaram cerca de R$ 200 mil em infraestrutura instalada em estações irregulares. O detalhe que chamou a atenção dos fiscais foi a origem de parte do material: foram recolhidos mais de 500 metros de cabos furtados de operadoras legalizadas.
Dos 48% restantes, segundo os dados do governo federal, 41% operavam integralmente dentro da lei, sem qualquer irregularidade. Outros 3% utilizavam equipamentos sem certificação, enquanto 4% das inspeções terminaram com laudos inconclusivos — casos que agora passarão por uma análise técnica e documental mais aprofundada da agência.
Proteção da infraestrutura e concorrência
A ofensiva foi coordenada pela Superintendência de Fiscalização (SFI) da Anatel e integra um plano maior de combate à concorrência desleal. Para o conselheiro da agência, Edson Holanda, a operação nacional é um marco necessário para dar estabilidade ao mercado.
Ele ressalta que a atuação pirata vai muito além de uma simples infração administrativa, sendo um ataque direto à segurança jurídica. “Empresas que investem em outorgas, equipamentos homologados e conformidade fiscal não podem ser prejudicadas por quem opera à margem da lei”, declarou.
A superintendente da SFI, Gesiléa Teles, explicou que as auditorias em campo são rigorosas. As equipes verificam desde as licenças de funcionamento e declarações de assinantes até a legalidade dos contratos de compartilhamento de postes e a origem de todo o maquinário.
Segundo Teles, esta rodada de fiscalizações é apenas o pontapé inicial. Novas fases da operação já estão programadas para manter a pressão contra a pirataria.
Find Hub (Localizador do Google) facilitará localização de malas perdidas (imagem: reprodução/Google)Resumo
Google lançou uma função no Localizador do Google (Find Hub) que permite compartilhar localização de malas perdidas com companhias aéreas;
Mais de dez companhias aéreas, incluindo Lufthansa e Turkish Airlines, já aderiram à novidade;
links de rastreamento expiram em sete dias ou quando a bagagem é recuperada.
Se para muitas pessoas o medo de viajar reside na possibilidade de um acidente aéreo, para tantas outras, o temor gira em torno de ter a sua bagagem perdida. Esse problema é tão comum que o Google anunciou uma função que permitirá que você compartilhe a localização da sua mala com a companhia aérea.
A novidade faz parte do Find Hub, no Brasil, chamado de Localizador do Google. O serviço permite que você rastreie o seu celular ou tablet em caso de perda, por exemplo. Se não for possível recuperar o dispositivo, você pode então bloqueá-lo remotamente ou, se for o caso, dar um comando para apagar os dados armazenados nele.
Também é possível usar o Localizador do Google para rastrear outros dispositivos, incluindo etiquetas localizadoras, como a Galaxy SmartTag e a Moto Tag.
É aqui que o novo recurso entra em cena: se você tiver colocado uma etiqueta localizadora compatível com o Localizador do Google em sua bagagem, poderá gerar um link de rastreamento em caso de perda e enviá-lo à companhia aérea.
Para tanto, bastará selecionar a etiqueta correspondente no Localizador do Google, tocar na opção de compartilhar localização e obter o seu respectivo link. O endereço poderá, então, ser compartilhado no aplicativo ou site da companhia aérea. O objetivo é permitir que a empresa recupere a bagagem mais facilmente.
Mas é claro que, para isso, é preciso que a companhia aérea participe da iniciativa.
Compartilhamento de link de bagagem no Localizador do Google (imagem: reprodução/Google)
Quais são as companhias aéreas participantes?
De acordo com Google, mais de dez companhias aéreas já aderiram à novidade, o que significa que o site ou o aplicativo de cada uma delas já permite a inserção de links de rastreamento. Entre elas estão:
AJet
Air India
China Airlines
Lufthansa Group (Lufthansa, Austrian Airlines, Brussels Airlines e Swiss International Airlines)
Saudia Airlines
Scandinavian Airlines
Turkish Airlines
É um número pequeno ainda, mas a expectativa é a de que a quantidade de companhias participantes aumente progressivamente. O Google também planeja levar o recurso aos serviços de rastreamento de bagagens WorldTracer e NetTracer, e já mantém negociações para a tecnologia ser implementada em malas da Samsonite.
Vale destacar que os links compartilhados expiram automaticamente em sete dias ou assim que a bagagem perdida for recuperada. Também é possível desativar o rastreamento manualmente, a qualquer momento.
Arquivo digital passa por fases da internet (imagem: reprodução/Opera)Resumo
Opera lançou um arquivo digital interativo para celebrar 30 anos do navegador, permitindo explorar marcos da cultura digital;
Usuários podem participar do concurso cultural no site Web Rewind, submetendo textos e mídias para concorrer a uma viagem ao CERN;
O arquivo inclui sons de modems, vídeos curtos e layouts antigos de redes sociais, destacando a evolução da internet.
A Opera lançou um arquivo digital interativo como parte das celebrações do aniversário de 30 anos de seu navegador, celebrado neste ano de 2026. A ferramenta, desenhada para funcionar como uma linha do tempo navegável das últimas três décadas da cultura digital, é destinado a preservar marcos visuais e culturais da internet.
A empresa foi fundada em 1995, na Noruega, e lançou seu navegador em 1996. Em 2016, a Opera foi adquirida por um consórcio chinês liderado pela Kunlun Tech, que continua detendo a maior parte de suas ações.
Para acessar o arquivo, os usuários devem acessar a página Web Rewind, desenvolvida pela empresa. Nela, é possível utilizar a barra de espaço nos computadores (ou manter a tela pressionada nos celulares e tablets) para avançar rapidamente pela linha do tempo, ou clicar em anos específicos. Todo o conteúdo está disponível em português.
O acervo interativo explora desde sons característicos da conexão por modems, o avanço dos vídeos curtos com plataformas como o falecido Vine e até o design das primeiras páginas personalizadas no MySpace. A viagem temporal avança ainda pelo nascimento da cultura de vídeos virais e pelos antigos layouts de redes sociais, desaguando na atual fase marcada pelos comandos (prompts) de inteligência artificial.
“Em três décadas, a web evoluiu de uma ferramenta científica de nicho para uma parte indispensável de todas as nossas vidas”, contextualizou Jan Standal, vice-presidente sênior da Opera, classificando a plataforma como um tributo à comunidade que moldou a internet.
Concurso cultural e viagem ao CERN
Além de explorar os registros já disponíveis, a iniciativa recolhe contribuições do público para integrar o acervo. A proposta é a de que usuários compartilhem momentos que definiram as próprias experiências online.
Para participar, os interessados devem acessar o site do Web Rewind e submeter um texto descritivo com um máximo de 500 caracteres, sendo permitido anexar fotos ou vídeos (com um limite de 10 MB). As inscrições permanecem abertas até o dia 27 de março deste ano.
Os autores das três melhores contribuições receberão, como prêmio, uma viagem à Suíça para visitar a sede do CERN (Organização Europeia para a Pesquisa Nuclear). Além de atual lar do Grande Colisor de Hádrons, a instituição é o local onde o cientista britânico Tim Berners-Lee desenvolveu a base estrutural da World Wide Web, no início da década de 1990. A viagem dos vencedores está prevista para ocorrer antes de 30 de junho de 2026.
Internet Archive tem mais de 1 trilhão de páginas arquivadas (foto: Jason Scott/Flickr)
Portais e páginas na internet podem sair no ar por vários motivos, desde falhas técnicas a mudanças de endereço ou remoções deliberadas feitas por seus responsáveis. Para preservar esse conteúdo, serviços como o Internet Archive mantêm cópias arquivadas que permitem consultar versões antigas de sites. Isso se dá pelo Wayback Machine.
Agora, Mark Graham, diretor do Wayback Machine, tenta reverter um aumento nos bloqueios impostos ao serviço por grandes plataformas e veículos de mídia.
Em um manifesto publicado nesta terça-feira (17/02), o executivo afirmou que impedir o Internet Archive de salvar páginas da web compromete o registro público e pode causar danos históricos. O posicionamento responde a medidas adotadas nos últimos meses por publicações como o New York Times e pela plataforma Reddit.
O cerco ao arquivo digital foi motivado pelo temor de que empresas de inteligência artificial estejam utilizando a biblioteca sem fins lucrativos para facilitar a raspagem de dados e o treinamento de grandes modelos de linguagem.
Avanço de bloqueios contra o arquivo
NYT e outros jornais bloquearam robô do Internet Archive (Imagem: Joe ShlabotnikSeguir/Flickr)
Um levantamento publicado em janeiro pelo Nieman Lab, de Harvard, constatou que veículos de peso estão reavaliando a relação com o Internet Archive. O NYT, por exemplo, adicionou o robô do arquivo as restrições. A justificativa é que o Wayback Machine fornece acesso irrestrito e não autorizado aos conteúdos por parte de empresas de IA.
O veículo é um dos maiores críticos ao uso de material jornalístico para treinamento da tecnologia sem que haja acordos financeiros.
O laboratório menciona também o The Guardian, que filtrou os artigos da interface do Wayback Machine e excluiu o site das APIs do arquivo.
Ao todo, até a publicação da pesquisa, o Nieman Lab havia identificado 241 sites de notícias de nove países que haviam bloqueado pelo menos um robô do Internet Archive, apesar de maioria pertencer ao grupo USA Today, dono do jornal homônimo.
O que diz o executivo?
Wayback Machine permite revisitar páginas antigas, como o vicentenário Tecnoblog (imagem: Felipe Faustino/Tecnoblog)
Para Graham, as preocupações das organizações de mídia são compreensíveis, mas não têm fundamento sobre o Wayback Machine. Segundo ele, a ferramenta “não tem a intenção de ser uma porta dos fundos para raspagem comercial em larga escala”, e afirma que a organização trabalha para “evitar tais abusos”.
Ele explica, também, que a plataforma é construída para leitores humanos e utiliza mecanismos de filtragem, monitoramento e limite de taxa de acesso para combater atividades abusivas de bots. Para o diretor, o bloqueio do trabalho de preservação prejudica a capacidade informacional da sociedade.
“Jornalistas perdem ferramentas de prestação de contas. Pesquisadores perdem evidências. A web se torna mais frágil e fragmentada, e a história se torna mais fácil de reescrever”
Mark Graham, em manifesto contra o bloqueio do Wayback Machine
A mobilização do Internet Archive ocorre anos após reportagens apontarem que a plataforma esteve entre milhões de sites utilizados para raspagem de dados por empresas como Google e Meta. Em maio de 2023, a organização chegou a enfrentar instabilidade após uma sobrecarga provocada por tentativas automatizadas de extração de conteúdo. Na ocasião, os administradores da biblioteca bloquearam os acessos.
Samsung Internet deve expandir recursos integrados de IA (imagem: divulgação)Resumo
O navegador Samsung Internet pode integrar mais funções de IA com o lançamento da One UI 9.
Um dos novos recursos pode usar o histórico de navegação do usuário para oferecer resultados personalizados.
A interface One UI 9 é esperada para o meio do ano, junto com os novos dobráveis da marca.
A próxima grande atualização da interface One Ui da Samsung ainda está longe, mas detalhes sobre ela já começam a pipocar. Entre eles, um código vazado indica que a empresa deve incluir mais integração com o Galaxy AI no Samsung Internet, o navegador proprietário da empresa.
Indícios encontrados em um firmware de teste da One UI 9 revelam o desenvolvimento de um recurso chamado Ask AI (algo como “Pergunte à IA”, em tradução livre). Segundo o portal Android Authority, que analisou o código do software vazado, a ferramenta deve permitir aos usuários interagir diretamente com o conteúdo de páginas da web por meio de perguntas e respostas.
Atualmente, o assistente de navegação da Samsung consegue resumir e traduzir páginas. As novas linhas de código sugerem a mudança: “O assistente de navegação usa IA para responder perguntas sobre páginas da web e outros tópicos, resumir e traduzir textos”.
Segundo a apuração, a ferramenta será capaz de suportar perguntas de acompanhamento, permitindo uma conversa contínua sobre o assunto pesquisado.
Função poderá usar dados de navegação
Um diferencial seria a integração com os dados do usuário. O código indica que a Samsung poderá utilizar o histórico de navegação e atividades passadas para oferecer resultados personalizados. Uma das mensagens do sistema diz: “Quando você faz perguntas, a Samsung processa o conteúdo da página e, para perguntas, o seu histórico de navegação”.
Em relação ao armazenamento dessas interações, o vazamento sugere que o usuário terá controle sobre a retenção dos dados.
Embora o firmware de teste mostrasse apenas a opção “Somente sessão” (na qual a atividade pode ser retida por até três dias), linhas de código indicam que haverá um menu para escolher por quanto tempo manter o histórico do “Ask AI”, aplicando a decisão a todos os dispositivos conectados.
Quando a One UI 9 chega?
One UI 8 foi a última grande atualização da interface da Samsung (imagem: Thássius Veloso/Tecnoblog)
A One UI 9 é esperada como uma atualização de meio de ciclo e deve ser lançada junto com os novos dobráveis da marca no meio do ano. A próxima atualização, que deve acompanhar os novos Galaxy S26, é a One UI 8.5.
Como é comum em análises de APK e firmwares de teste, a presença do código não garante que a funcionalidade chegará à versão final do produto da forma como foi descoberta.
Internet Archive tem mais de 1 trilhão de páginas arquivadas (foto: Jason Scott/Flickr)Resumo
O Internet Archive e a Automattic criaram o plugin Link Fixer para corrigir links quebrados em páginas antigas.
O Link Fixer é gratuito e de código aberto, escaneia links, arquiva páginas na Wayback Machine e atualiza links para versões arquivadas.
Um estudo de 2024 da Pew Research indica que 38% dos links de 2013 não funcionam mais, destacando a importância da iniciativa.
A organização sem fins lucrativos Internet Archive e a empresa Automattic, responsável pelo WordPress, anunciaram a criação do plugin Link Fixer, que terá como objetivo evitar que links de páginas antigas levem o leitor a endereços quebrados ou fora do ar.
Do lado do Internet Archive, a iniciativa faz parte do projeto Wayback Machine, que tem arquivos de mais de 1 trilhão de páginas. O software será integrado ao serviço de sites e blogs.
Como o plugin vai funcionar?
O plugin Link Fixer é gratuito e de código aberto. Quando instalado pelo dono de um site, vai escanear os links publicados. Com isso, ele checa se as páginas ainda estão no ar e se elas têm cópias na Wayback Machine — caso não tenham, a solução fará um snapshot e o enviará ao serviço.
A ferramenta não vai apenas arquivar conteúdos — ela também consertará ligações para outras páginas. Caso note que uma página linkada está offline, o plugin entra em cena e atualiza o caminho para uma versão arquivada. O contrário também pode ocorrer: se o endereço original voltar a funcionar, o redirecionamento é desfeito.
Sede do Internet Archive fica em San Francisco (EUA) (foto: Beatrice Murch/Flickr)
De acordo com a página do Link Fixer, o plugin só precisa ser configurado uma vez; depois disso, ele roda em segundo plano. Caso um site tenha milhares de links, pode demorar algumas semanas até concluir os trabalhos.
Links quebrados são um problema na web
Se você já navegou por notícias de décadas atrás, blogs esquecidos e outros tipos de conteúdo antigo, sabe como é frustrante encontrar uma indicação para uma página interessante, mas não conseguir acessá-la.
Segundo um estudo de 2024 da Pew Research, 38% dos links que existiam em 2013 não estavam mais funcionando. Isso vale para diferentes tipos de conteúdo, como sites, reportagens, páginas governamentais, artigos da Wikipédia e publicações em redes sociais.
“Nós acreditamos que a web deve ser um recurso durável e confiável para todos. Ao longo do tempo, no entanto, os links quebram. Páginas são movidas, domínios não são renovados, sites saem do ar e conteúdo valioso desaparece”, explica a Automattic em seu comunicado.
Aplicativo do ChatGPT para iPhone com mensagem de erro (imagem: Emerson Alecrim/Tecnoblog)Resumo
Usuários do ChatGPT se deparam com mensagem de erro ao usar a ferramenta nesta terça-feira (03/02);
OpenAI reconhece o problema em sua página de status e já trabalha em solução;
Falha no ChatGPT afeta usuários no mundo todo.
Usuários do ChatGPT enfrentam dificuldades para usar a ferramenta na tarde desta terça-feira (03/02). A versão web do serviço e os seus respectivos aplicativos abrem normalmente. Mas, quando o usuário faz uma pergunta ou digita instruções (prompts), se depara com uma mensagem de erro.
A mensagem de erro tem os seguintes dizeres: “Hmm…something seems to have gone wrong“, que podem ser traduzidos como “Hum… parece que alguma coisa está errada”.
A mensagem de erro é acompanha de um botão “Repetir”, que tem a função de reenviar a pergunta ou o prompt que fez o alerta ser exibido. No entanto, quando o botão é pressionado, o erro volta a se aparecer.
Não por acaso, na página de status da OpenAI, que reporta a existência de problemas nos serviços da organização, há um aviso de que o ChatGPT está exibindo mensagens de erro para um número elevado de usuários.
Mensagem de erro na versão web do ChatGPT (imagem: Emerson Alecrim/Tecnoblog)
Não é só com você, portanto. O problema afeta usuários do serviço no mundo todo, inclusive aqueles que usam versões pagas do ChatGPT.
Além disso, há falhas em APIs da OpenAI relacionadas ao ChatGPT. Isso significa que serviços de terceiros que utilizam recursos do ChatGPT também enfrentam problemas.
Curiosamente, testes feito pelo Tecnoblog com as versões web e móveis do ChatGPT (apps) mostram a ferramenta dando respostas normalmente quando o usuário não está logado no serviço.
Qual a causa da falha no ChatGPT?
As razões da falha ainda não foram identificadas ou reveladas. Ainda em sua página de status, a OpenAI informa apenas que já está trabalhando em uma solução para o problema.
Os erros começaram a aparecer por volta das 18:00 de hoje (considerando o horário de Brasília).
Grande parte dos usuários começou a notar uma normalização ao redor das 18:30.
Equipamento foi desenvolvido na Universidade da Califórnia (ilustração: Vitor Pádua/Tecnoblog)Resumo
Pesquisadores da Universidade da Califórnia em Irvine criaram um transceptor sem fio que atinge 120 Gb/s, 24 vezes mais rápido que o 5G mmWave.
Tecnologia utiliza chip de silício de 22 nanômetros, reduzindo consumo de energia para 230 miliwatts e facilitando produção em massa.
No entanto, a principal limitação é o alcance de sinal, que é muito menor que o 5G mmWave.
Pesquisadores da Universidade da Califórnia em Irvine (EUA) desenvolveram um dispositivo de transmissão sem fio capaz de transmitir dados a 120 gigabits por segundo (Gb/s), que equivale a cerca de 15 gigabytes por segundo (GB/s). A velocidade é 24 vezes superior à do 5G mmWave e se aproxima das conexões de fibra óptica usadas em data centers, que geralmente operam a 100 Gb/s.
Para chegar a esse número, vale lembrar que um byte equivale a oito bits. Essa velocidade permitiria baixar cerca de três filmes em qualidade 4K (dependendo do nível de compressão dos arquivos) em um segundo, ou baixar um jogo pesado de 130 GB, como Black Myth: Wukong, em menos de nove segundos.
O equipamento desenvolvido pelos pesquisadores trabalha na faixa de 140 GHz e supera em larga margem as tecnologias sem fio disponíveis no mercado.
O Wi-Fi 7 atinge teoricamente até 30 Gb/s, enquanto o 5G mmWave chega a 5 Gb/s. A título de comparação, o 5G brasileiro, o mais rápido da América Latina, atinge velocidade média de 430,8 Mb/s. O novo transceptor opera a 15 GB/s, cerca de 277 vezes mais rápido que a melhor rede comercial do país.
A equipe liderada pelo pesquisador Zisong Wang substituiu os conversores digitais-analógicos (DAC) tradicionais por três sub-transmissores sincronizados, o que reduz drasticamente o consumo de energia.
O diferencial está no processamento analógico. O transceptor realiza operações complexas no domínio analógico, ao invés do digital, o que permite que o chip consuma apenas 230 miliwatts. Um DAC convencional capaz de processar 120 Gb/s demandaria vários watts de potência.
Segundo o diretor do Laboratório de Circuitos Integrados de Comunicação em Nanoescala da UC Irvine, Payam Heydari, se fossem usados métodos tradicionais, a bateria de dispositivos móveis de próxima geração duraria minutos.
Tecnologia demonstrou ser mais veloz que o 5G (ilustração: Vitor Pádua/Tecnoblog)
O chip é fabricado em silício com processo de 22 nanômetros, usando tecnologia de silício sobre isolante totalmente depletado. Esse processo é mais simples que os nós de 2 nanômetros ou 18 A usados por empresas como TSMC e Samsung, o que facilita a produção em massa e reduz custos.
Além disso, os pesquisadores destacam que a tecnologia pode substituir quilômetros de cabos em data centers, reduzindo custos de instalação e operação em ambientes com servidores.
Quais são as limitações da tecnologia?
A principal restrição está no alcance do sinal. O 5G mmWave atual, que opera a até 71 GHz, já tem alcance limitado a cerca de 300 metros. Como o novo transceptor opera em frequências ainda mais altas (140 GHz), o raio de cobertura tende a ser menor.
Wang comentou ao Tom’s Hardwareque a Comissão Federal de Comunicações dos Estados Unidos e os órgãos responsáveis pelos padrões 6G estão analisando o espectro de 100 GHz como a nova fronteira para comunicações sem fio.
No entanto, para adoção em larga escala, será necessário desenvolver métodos de extensão de alcance e gerenciamento de interferências, além de integrar o sistema às redes já existentes. Ou seja: sem inovações que melhorem o alcance do sinal, as cidades ficariam repletas de estações base de alta velocidade, tornando inviável.
Entenda como o Google se tornou uma das principais big tech do planeta (imagem: Vitor Pádua / Tecnoblog)
O Google é uma gigante da tecnologia fundada por Larry Page e Sergey Brin em 1998, na Califórnia. Atualmente, a companhia atua como a principal subsidiária do conglomerado Alphabet Inc., liderando a inovação digital.
A empresa surgiu para organizar as informações da web, tornando-as mais acessíveis por meio de um algoritmo eficaz. Essa missão nasceu de um projeto acadêmico focado em classificar a relevância das páginas da rede mundial.
Além do mecanismo de busca, o portfólio de produtos do Google inclui o Android, o YouTube, o Google Maps e a inteligência artificial Gemini. Essas soluções transformaram a forma como as pessoas consomem conteúdo e interagem com o ambiente digital moderno.
A seguir, conheça mais detalhes sobre a história do Google e o real significado do seu nome. Também descubra os principais serviços e produtos do portfólio da big tech de Mountain View.
Google é uma multinacional americana de tecnologia, fundada em 1998, que visa organizar o grande volume de informações da web para torná-la acessível. Embora seja conhecida por seu motor de busca, a empresa atua nos setores de publicidade digital, computação em nuvem, inteligência artificial e o ecossistema mobile Android.
O que significa “Google”?
O nome “Google” surgiu de uma grafia propositalmente incorreta do termo matemático “googol”. A palavra representa o numeral 1 seguido de cem zeros ou 10 elevado à potência de 100, ilustrando a capacidade de processamento de quantidade astronômica de dados.
Adotado em 1997, o nome simboliza a missão da empresa de organizar o volume massivo de informações disponíveis na web. Assim, ele reflete a ambição dos fundadores em estruturar e tornar universalmente acessível uma escala quase infinita de conteúdos digitais.
Para que serve o Google?
O Google atua como o principal organizador de informações globais, permitindo que usuários encontrem conteúdos, localizações e soluções de forma instantânea. Por meio de algoritmos avançados, a plataforma simplifica a navegação digital e otimiza a produtividade no cotidiano.
Sua infraestrutura integra serviços essenciais como Android, Workspace, YouTube e ferramentas de IA para conectar pessoas e facilitar a comunicação. Dessa forma, a empresa provê um ecossistema completo que transforma dados complexos em recursos acessíveis e úteis.
Além da busca, o Google oferece uma série de produtos e serviços digitais que melhoram o cotidiano dos usuários (imagem: Thássius Veloso/Tecnoblog)
Qual é a história do Google?
A história do Google começou em 1996 na Universidade de Stanford, onde Larry Page e Sergey Brin desenvolveram o algoritmo PageRank e o buscador experimental BackRub. O objetivo era organizar a web por meio do algoritmo que media a relevância entre páginas da grande rede.
O domínio google.com foi registrado em 1997 e, no ano seguinte, a empresa oficializou o motor de busca e estabeleceu-se em uma garagem em Menlo Park, na Califórnia, com aportes iniciais. No ano de 2000, o lançamento do AdWords revolucionou o modelo de negócios ao monetizar as buscas.
A abertura de capital (IPO) em 2004 arrecadou US$ 1,67 bilhão, financiando expansões como o Gmail e as aquisições estratégicas do YouTube e do Android nos anos seguintes. Em 2008, o lançamento do navegador Chrome consolidou a dominância da marca no ecossistema digital.
A criação da Alphabet Inc. em 2015 reorganizou a estrutura corporativa, permitindo que a agora subsidiária Google focasse em hardware e serviços de internet. Sob a gestão de Sundar Pichai, a empresa priorizou o desenvolvimento de tecnologias de nuvem.
Atualmente, a big tech foca na inteligência artificial generativa com o modelo Gemini e sua integração total ao buscador. Assim, a marca continua expandindo seu ecossistema por meio de inovações em IA, publicidade digital e computação em nuvem.
Larry Page e Sergey Brin na garagem onde foi fundado o Google (imagem: Vitor Pádua/Tecnoblog)
Quem criou o Google?
Larry Page e Sergey Brin são os fundadores do Google. A dupla se conheceu durante o doutorado da Universidade de Stanford, quando desenvolveram o algoritmo PageRank e iniciaram o projeto do buscador experimental BackRub.
Quando o Google foi criado?
O Google foi fundado oficialmente em 4 de setembro de 1998. Nesta data, Larry Page e Sergey Brin oficializaram o motor de busca desenvolvido durante o doutorado em Stanford e iniciaram as operações em uma garagem em Menlo Park, Califórnia (EUA).
Sundar Pichai é CEO do Google e da Alphabet Inc. desde 2015 (imagem: divulgação)
Quem é o CEO do Google?
O atual CEO do Google e da Alphabet Inc. é Sundar Pichai, que lidera ambas as companhias desde a reestruturação corporativa iniciada em 2015. Sob sua gestão, a empresa se tornou uma “AI-first”, priorizando inovações em inteligência artificial, computação em nuvem e infraestrutura digital global.
Onde fica a sede do Google?
A sede global do Google, conhecida como Googleplex, está localizada em Mountain View, Califórnia (EUA). O complexo no Vale do Silício abriga o comando central da Alphabet Inc. e simboliza a inovação tecnológica da empresa.
No Brasil, as operações principais concentram-se em São Paulo, divididas entre o escritório administrativo e o Google for Startups Campus. Complementando a infraestrutura, Belo Horizonte sedia um centro de engenharia estratégica para a América Latina.
O Googleplex fica localizado em Mountain View, Califórnia (imagem: The Pancake of Heaven/Wikimedia Commons)
Quais são os produtos do Google?
O Google tem um amplo portfólio que integra software, hardware e inteligência artificial para organizar a informação global. Conheça os principais produtos e serviços divididos por categorias:
Busca e informação
Google Busca: principal motor de pesquisa do mundo, usando algoritmos avançados para entregar resultados precisos em texto, imagens e notícias;
Google Maps e Earth: serviços de geolocalização e navegação por satélite que oferecem rotas em tempo real, Street View e mapeamento detalhado;
Google Lens: ferramenta de reconhecimento visual que usa IA para traduzir textos, identificar objetos e pesquisar produtos por meio da câmera do smartphone.
Produtividade e colaboração
Gmail e Agenda: serviços líderes de e-mail e gestão de tempo, integrados para automatizar convites, lembretes e comunicações corporativas ou pessoais;
Google Drive: plataforma de armazenamento em nuvem que centraliza arquivos e permite a sincronização em tempo real entre diferentes dispositivos;
Google Documentos, Planilhas e Apresentações:ferramentas de produtividade online que permitem a criação e edição simultânea de arquivos sem a necessidade de instalação local.
O buscador do Google segue como um dos principais produtos da big tech (imagem: Thássius Veloso/Tecnoblog)
Comunicação e entretenimento
YouTube: maior plataforma de vídeos e streaming do mundo, abrangendo desde conteúdos educativos e musicais até transmissões ao vivo e o YouTube Kids;
Google Meet e Chat: soluções corporativas de videoconferência em alta definição e mensagens instantâneas voltadas para o trabalho em equipe;
Google Fotos: galeria inteligente que usa IA para organizar, buscar rostos e otimizar o armazenamento de imagens e vídeos na nuvem.
Sistemas operacionais e hardware
Android e WearOS: sistemas operacionais para dispositivos móveis e smartwatches, servindo como base para o ecossistema global de aplicativos;
Chrome e ChromeOS: navegador web de alto desempenho e sistema operacional leve focado em agilidade, segurança e integração total com a nuvem;
Linha Pixel e Nest: smartphones de alto desempenho e dispositivos para casas inteligentes, como alto-falantes integrados com o Google Assistente.
IA e serviços empresariais
Google Gemini: modelo de inteligência artificial generativa multimodal que auxilia em tarefas criativas, escrita de códigos e análise de dados complexos;
Google Cloud: infraestrutura empresarial que oferece computação escalável, análise de dados e ferramentas de desenvolvimento para empresas;
Google Play: loja oficial de distribuição digital para aplicativos, jogos e conteúdo de mídia voltados para o ecossistema Android.
O Gemini vem sendo integrado a diversos produtos do Google, incluindo o buscador e o sistema operacional Android (imagem: Vitor Pádua/Tecnoblog)
Qual é a diferença entre Google e Alphabet?
O Google é a principal subsidiária da Alphabet Inc., focada em produtos digitais e serviços de internet, como Busca, YouTube, Android e publicidade digital. Representa o motor financeiro da holding, operando os negócios mais consolidados e lucrativos que fundamentaram a empresa original.
A Alphabet Inc. é a empresa-mãe que controla o Google e um portfólio de empresas experimentais conhecidas como “Other Bets”, como a Waymo e a Verily. Sua estrutura foi criada para separar o núcleo de internet de projetos de alto risco, garantindo maior transparência e foco em inovação.
Wikipédia completa 25 anos (imagem: Kristina Alexanderson/Flickr)Resumo
Wikipédia comemora 25 anos com atividades interativas, incluindo uma cápsula do tempo digital e uma série documental.
A Wikimedia Foundation anunciou acordos com Microsoft, Google, Meta, Amazon e Perplexity para o uso sustentável do conteúdo.
O site é um dos mais acessados do mundo, com 1,5 bilhão de dispositivos únicos mensalmente e mais de 65 milhões de artigos em 300 idiomas.
Antes das respostas automáticas de chatbots de inteligência artificial, quase toda pesquisa passava por um lugar em comum: a Wikipédia, que comemora, nesta quinta-feira (15/01), seus 25 anos. Para marcar a data, a Wikimedia Foundation, organização sem fins lucrativos que mantém o projeto, lançou uma campanha global que celebra os humanos por trás do conteúdo da plataforma.
A celebração inclui o lançamento de uma cápsula do tempo digital, com áudios de Jimmy Wales, fundador do site. Em comemoração, a fundação também anunciou novos acordos com big techs, como Microsoft, Google, Meta, Amazon e Perplexity, para garantir que o uso do conteúdo seja sustentável e reverta em apoio à missão da enciclopédia.
Atividades digitais comemorativas
Wikipédia lança ativações digitais em aniversário (imagem: reprodução/Wikimedia)
Cápsula do tempo digital: reúne momentos-chave da história da plataforma, incluindo áudios de Jimmy Wales relembrando a instalação dos primeiros servidores e outras curiosidades.
Série documental: histórias incluem desde “Hurricane Hank”, que documenta furacões há duas décadas, até Netha, uma médica indiana que combateu desinformação médica durante a pandemia de Covid-19.
Para as comemorações, a fundação adotou um mascote apelidado de “Baby Globe”. O personagem foi inspirado em um esboço feito pelo brasileiro Jonathan Ferreira, colaborador da plataforma.
Esboço do Baby Globe origem a um bichinho de pelúcia de edição limitada (imagem: reprodução/Diff/Wikimedia)
“Eu queria apenas desenhar algo para estampar camisetas em um encontro de wikipedistas”, contou Jonathan em entrevista à fundação Wikimedia. O mascote aparece em materiais comemorativos e recursos visuais temporários dentro da Wikipédia.
Sobrevivendo à era da IA
Aos 25 anos, a Wikipédia vive um momento diferente do que já foi antes. Enquanto se mantém como um bastião do conhecimento humano, ela se tornou, ironicamente, o “combustível” para treinar as IAs.
Dentro da plataforma, tenta equilibrar esse novo universo: só em 2025, iniciou e suspendeu, pouco depois, resumos de IA nos textos. Em agosto, passou a permitir, sem maiores discussões, a exclusão de artigos gerados por IA publicados sem revisão humana.
Editores denunciaram posts gerados por IA (imagem: Felipe Faustino/Tecnoblog)
Como a Wikipédia surgiu?
Lançada em 15 de janeiro de 2001 por Jimmy Wales e Larry Sanger, a Wikipédia surgiu inicialmente como um projeto complementar à Nupedia, uma enciclopédia online que exigia revisão rigorosa de especialistas e tinha um processo de publicação lento. Em maio daquele ano, o site recebia a versão em português.
Desde então, o projeto cresceu em escala e relevância — especialmente para quem estudou entre as décadas de 2000 e 2010. Foi, para mim e muitos outros, o principal site para pesquisa (ainda que o uso sempre tenha sido desencorajado pelos professores) e, também, um lugar para passar horas lendo sobre qualquer coisa, abrir infinitos hiperlinks e nem sempre terminá-los.
Mesmo com a ascensão das redes sociais e a migração do consumo de informação para outros modelos, como a IA, a Wikipédia ainda se mantém entre os dez sites mais acessados do mundo. O site é o único desse grupo operado por uma organização sem fins lucrativos, mantida por uma comunidade global de voluntários com políticas próprias de verificabilidade.
“A Wikipédia demonstra 25 anos da humanidade em seu melhor”, afirmou Jimmy Wales, fundador da plataforma, em comunicado oficial. Segundo a fundação, a Wikipédia reúne mais de 65 milhões de artigos em mais de 300 idiomas e é acessada mensalmente por cerca de 1,5 bilhão de dispositivos únicos.
TikTok foi o app mais baixado em 2025 (foto: André Fogaça/Tecnoblog)Resumo
TikTok foi o app mais baixado na América Latina em 2025.
ChatGPT e Gemini, apps de IA, se destacaram com crescimentos de 156% e 318%, respectivamente.
Mercado Livre e Mercado Pago são os únicos aplicativos latino-americanos no top 20.
O ano novo chegou e, com ele, a lista dos aplicativos mais baixados na América Latina em 2025. Desta vez, a novidade foi a ascensão dos apps de inteligência artificial: em comparação ao ano anterior, o ChatGPT saltou da 16ª para a terceira posição, enquanto o Gemini subiu da 126ª para a sexta colocação.
A principal rede social de vídeos curtos, o TikTok, manteve a liderança. Os dados foram levantados pelo Mobile Time junto à AppMagic, somando resultados da App Store e Google Play em nove países: Argentina, Brasil, Chile, Colômbia, Equador, México, Peru, República Dominicana e Uruguai.
Confira o ranking da América Latina
TikTok — 156 milhões de downloads
Temu — 128 milhões
ChatGPT — 123 milhões
Instagram — 83 milhões
Roblox — 72 milhões
Gemini — 67 milhões
Facebook — 64 milhões
WhatsApp — 62 milhões
Mercado Livre — 62 milhões
CapCut — 61 milhões
ReelShort — 60 milhões
DramaBox — 59 milhões
Seekee — 55 milhões
Shein — 55 milhões
Block Blast! — 51 milhões
Spotify — 47 milhões
Threads — 47 milhões
Telegram — 45 milhões
Free Fire — 45 milhões
Mercado Pago — 40 milhões
IA generativa no topo
ChatGPT foi o app de IA mais baixado em 2025 (ilustração: Vitor Pádua/Tecnoblog)
O aumento de downloads do ChatGPT foi de 156% em comparação com 2024, passando de 48 milhões para 123 milhões. O crescimento do Gemini foi ainda maior, indo de 16 milhões para 67 milhões.
É fato que, em 2025, ferramentas de IA cresceram em popularidade. Mas o ranking também revela que, na nossa região, segue alta a busca por apps de mensagens, marketplaces e jogos. O Instagram, que ocupava a terceira posição em 2024, caiu para a quarta colocação.
Apenas dois apps latino-americanos no top 20
Mercado Livre e o Mercado Pago são os únicos representantes da região entre os 20 mais baixados. O marketplace da Argentina aparece na 9ª posição, enquanto seu aplicativo de pagamentos ocupa a 20ª colocação.
Fora do top 20, os próximos apps de origem latino-americana são o Nubank e o Gov.br, na 23ª e 28ª posições, respectivamente.
Tim Berners-Lee foi o criador da World Wide Web (WWW), além de outras tecnologias fundamentais para o desenvolvimento da internet que conhecemos.
O físico nasceu em Londres e atuou na Organização Europeia para a Pesquisa Nuclear (CERN) nos anos 80, época na qual desenvolveu o primeiro servidor e página web baseada em texto.
Tecnologias como o HTTP, HTML, URL, além da fundação do W3C são algumas contribuições de Tim Berners-Lee para a sociedade. A seguir, conheça mais detalhes sobre a história do cientista da computação conhecido como “pai da web”.
Tim Berners-Lee é um físico e cientista da computação britânico conhecido como o “pai da web”, devido à criação da World Wide Web (WWW) e outras tecnologias (HTTP, HTML e URL).
Berners-Lee trabalhou no CERN (Organização Europeia para a Pesquisa Nuclear), além de ser professor no MIT. Em 1989, o cientista criou um sistema de gerenciamento de informações para que outros cientistas pudessem acessar documentos e informações do laboratório.
Posteriormente, desenvolveu o primeiro servidor, primeiro navegador e o primeiro site da web: https://info.cern.ch/
Tela do primeiro site criado na Web, usado no CERN (Imagem: Reprodução)
O físico britânico garantiu que a internet fosse gratuita e aberta a todos, deixando de patentear sua invenção. Além disso, fundou o W3C (World Wide Web Consortium) que garante toda a padronização da web que conhecemos.
Tim Berners-Lee foi condecorado com o título de “Sir” pela Rainha Elizabeth II em 2004, além de vencer o prêmio Turing em 2016, considerado o Prêmio Nobel da Computação. O físico lidera o projeto Solid, que busca permitir que os usuários voltem a ter controle total dos dados que estão nas mãos das big techs.
Onde Tim Berners-Lee nasceu?
Tim Berners-Lee nasceu em Londres, na Inglaterra, no dia 8 de junho de 1955. O britânico é filho de Conway Berners-Lee e Mary Lee Woods, também cientistas da computação.
Qual é a formação de Tim Berners-Lee?
Tim Berners-Lee formou-se em física pelo The Queen’s College, em Oxford, de 1973 a 1976. Na infância, o britânico estudou na escola primária Sheen Mount e na Emanuel School em Londres, de 1969 a 1973. Tim atuou como cientista da computação, além de ser docente no MIT.
The Queen’s College (Imagem: John Cairns)
Quais foram as criações de Tim Berners-Lee?
Conhecido como o “pai da internet”, Tim Berners-Lee contribuiu para o surgimento da web com as seguintes criações:
World Wide Web (WWW): Tim Berners-Lee criou a World Wide Web em 1989, enquanto trabalhava no CERN. A ideia do físico era criar um sistema de gerenciamento e compartilhamento de informações entre os cientistas do laboratório de partículas;
HTML (HyperText Markup Language): O HTML foi criado por Tim Berners-Lee em 1991 para resolver problemas de comunicação entre os cientistas do CERN. No entanto, foi adotado como padrão em páginas web com a popularização da internet;
HTTP (Hypertext Transfer Protocol): Tim Berners-Lee inventou o HTTP também na década de 90, com o objetivo de automatizar o compartilhamento de informações entre os cientistas da Organização Europeia para a Pesquisa Nuclear (CERN);
URL/URI: URL e URI foram criados por Tim Berners-Lee no início da década de 90 para que a web funcionasse. Dessa forma, o esquema de endereçamento baseado em links foi desenvolvido para que cada página tivesse um endereço único.
Primeiro navegador web: O WorldWideWeb foi o primeiro navegador web desenvolvido — renomeado para Nexus, posteriormente. Tim Berners-Lee programou o software em um computador NeXT. Tim também desenvolveu funcionalidades de edição para que qualquer pessoa pudesse editar uma página web.
Primeiro servidor: Tim Berners-Lee desenvolveu o primeiro servidor, o CERN httpd. Sua criação foi necessária para que os documentos do laboratório de partículas pudessem ser acessados por qualquer computador conectado. Antes, os arquivos ficavam isolados em computadores específicos;
W3C (World Wide Web Consortium): O W3C é uma organização internacional de padronização da rede, fundada por Tim Berners-Lee em outubro de 1994. O consórcio estabelece padrões técnicos fundamentais para diferentes navegadores e dispositivos, assegurando que o conteúdo digital seja interpretado de forma consistente em qualquer plataforma.
Por que Tim Berners-Lee criou a World Wide Web (WWW)?
A World Wide Web (WWW) foi criada para atender a uma demanda do CERN, o maior laboratório de física de partículas do mundo. Na época, era necessário o compartilhamento de informações e documentos entre cientistas do laboratório, de universidades e outros institutos ao redor do mundo.
Dessa forma, Tim Berners-Lee criou uma rede descentralizada de hipertexto para que os cientistas pudessem acessar os dados globalmente. A invenção do físico britânico criou todo um ecossistema digital, quebrando barreiras geográficas e permitindo a criação da web como conhecemos.
Gmail deixa de importar mensagens de outros e-mails via POP3 (ilustração: Vitor Pádua/Tecnoblog)Resumo
Gmail deixou de suportar importação de e-mails de terceiros via POP3 em janeiro de 2026;
Google não emitiu nota oficial sobre o assunto, mas atualizou uma página de suporte para comunicar a decisão;
Fragilidade de segurança do POP3 é uma causa provável para a mudança.
2026 começou com uma mudança silenciosa no Gmail. Neste mês de janeiro, o serviço deixou de suportar a importação de mensagens de outros provedores de e-mail via protocolo POP3. Quem usa esse recurso para concentrar suas contas de e-mail no Gmail terá que recorrer a outros mecanismos para esse fim.
Não houve nenhuma nota pública sobre a decisão. O aviso sobre a mudança aparece nesta página de ajuda do Gmail, que afirma que os seguintes recursos perderão suporte (considerando janeiro de 2026 como data inicial):
Gmailify: com esse recurso, você pode usar recursos especiais, como proteção contra spam ou organização da caixa de entrada, na sua conta de e-mail de terceiros;
Verificar e-mail de outras contas: não será mais possível buscar e-mails de contas de terceiros para sua conta do Gmail com o POP.
O POP3 consiste na terceira versão de um protocolo criado na década de 1980 que permite que o usuário baixe mensagens de um serviço de e-mail usando clientes como Mozilla Thunderbird e Microsoft Outlook.
Lançado em 2004, o Gmail suportava o POP3 desde os seus primórdios justamente para permitir que o usuário acessasse, por ali, mensagens em outras contas de e-mail.
A importação via POP3 ainda funciona para muitos usuários, mas o recurso deverá ser inteiramente removido do Gmail até o fim deste mês.
Configuração de POP3 no Gmail (imagem: Emerson Alecrim/Tecnoblog)
Por que o Gmail deixou de suportar o POP3?
O Google não explicou o motivo. Contudo, o Register levanta a possibilidade de a decisão ter como base o fato de o POP3 exigir o envio de senha em texto puro, sem criptografia, para funcionar. Para os padrões atuais, isso corresponde a uma importante fragilidade de segurança.
Isso não significa que o Gmail deixou de permitir integração com outros serviços de e-mail. Ainda é possível fazer isso usando o aplicativo do Gmail para Android, iPhone ou iPad, por exemplo, a partir de uma conexão IMAP, um protocolo mais seguro do que o POP3.
O problema é que o suporte a IMAP no Gmail é limitado. Quem tiver problemas com isso deverá recorrer a medidas alternativas, como criar um encaminhamento automático de mensagens em outras contas para o Gmail ou, no fim das contas, adotar um cliente de e-mail, como os já mencionados Thunderbird e Outlook.
Saiba a importância do W3C para a internet (image: Reprodução/Identity)
O World Wide Web Consortium (W3C) é um consórcio internacional que desenvolve padrões técnicos para garantir o crescimento organizado da rede mundial. Sua missão é promover a interoperabilidade e o acesso universal em diferentes navegadores e dispositivos.
A organização foi fundada por Tim Berners-Lee em 1994, o próprio inventor da web, no instituto MIT nos Estados Unidos. Ele criou o grupo para estabelecer diretrizes abertas que mantivessem a internet gratuita e acessível a todos.
Na prática, o W3C cria normas fundamentais, como HTML e CSS, que funcionam como uma linguagem comum. Essas regras evitam o caos técnico e permitem que todos os sites funcionem corretamente em qualquer navegador.
A seguir, saiba mais sobre o W3C e como funciona detalhadamente o consórcio. Também descubra os padrões abertos aprovados pela organização e os principais membros.
O World Wide Web Consortium (W3C) é uma organização internacional de padronização da rede, responsável por criar normas técnicas como HTML e CSS. Seu objetivo é garantir a interoperabilidade e o acesso universal, assegurando que a web evolua de forma aberta, segura e consistente para todos os dispositivos.
Para que serve o World Wide Web Consortium?
O W3C estabelece padrões técnicos fundamentais que garantem a interoperabilidade global entre diferentes navegadores e dispositivos. Ele padroniza a arquitetura da rede, assegurando que o conteúdo digital seja interpretado de forma consistente em qualquer plataforma.
Ao promover diretrizes de acessibilidade e segurança, o consórcio viabiliza uma internet inclusiva, resiliente e tecnicamente unificada para todos os usuários. Esse esforço contínuo previne a fragmentação da rede e fomenta a inovação por meio de protocolos abertos e universais.
Os padrões do código HTML foram estabelecidos pelo W3C (imagem: Branko Stancevic/Unsplash)
Quem fundou o World Wide Web Consortium?
O físico britânico Tim Berners-Lee fundou o W3C em outubro de 1994, anos após inventar a rede mundial no CERN em 1989. Ele estabeleceu a sede inicial da organização no MIT visando criar protocolos abertos para a evolução da rede.
A iniciativa contou com o apoio da DARPA e da Comissão Europeia para garantir a interoperabilidade técnica global. Dessa maneira, o consórcio foca na criação de recomendações livres de royalties que padronizam o funcionamento de toda a internet.
Onde fica a sede do World Wide Web Consortium?
A sede principal do W3C está situada no Laboratório de Ciência da Computação e Inteligência Artificial (CSAIL) do MIT, nos Estados Unidos. Além da base norte-americana, o consórcio opera de forma global e descentralizada por meio de outras instituições anfitriãs.
No Brasil, o escritório regional do W3C atua desde 2008 no Núcleo de Informação e Coordenação do Ponto Br (NIC.br), em São Paulo. A primeira base do consórcio na América Latina contribui com a fomentação da web aberta e para garantir a participação brasileira no desenvolvimento de tecnologias globais.
O físico britânico Tim Berners-Lee é criador da Web e fundador do W3C (imagem: Reprodução/CERN)
Como funciona o W3C?
O W3C atua como o “livro de regras” da internet, estabelecendo normas técnicas que garantem a exibição uniforme de conteúdos em qualquer navegador. Essa padronização é essencial para evitar o caos técnico e se torna fundamental para preservar a história da web.
Liderado por Tim Berners-Lee, o consórcio reúne mais de 350 organizações que colaboram em grupos de arquitetura técnica e comitês consultivos. Essas entidades debatem propostas para assegurar que novas tecnologias sejam interoperáveis, seguras e abertas a todos os usuários.
O desenvolvimento segue um fluxo rigoroso, participando de rascunhos iniciais até alcançar fases de testes práticos e revisões técnicas. Especialistas de diversas áreas validam a estabilidade das ferramentas, garantindo que o código funcione com eficiência em diferentes dispositivos.
Ao final, o projeto é publicado como uma Recomendação W3C, tornando-se o padrão oficial adotado pela indústria global de tecnologia. Esse coletivo permite que a rede evolua de maneira organizada, mantendo a internet como um ecossistema integrado e funcional.
O W3C assegura que as novas tecnologias da web serão interoperáveis (imagem: Vitor Pádua/Tecnoblog)
Quais são os padrões abertos do W3C?
Os padrões W3C são especificações técnicas desenvolvidas colaborativamente para garantir a interoperabilidade, acessibilidade e evolução da web. Estas são as principais categorias e seus respectivos padrões:
Marcação e estrutura:
HTML: define a estrutura e o conteúdo das páginas web, usando elementos semânticos que otimizam a acessibilidade e o SEO;
XHTML: consiste em uma versão mais rigorosa do HTML baseada em XML, exigindo uma sintaxe precisa para validação.
Estilo e layout:
CSS: controla a apresentação visual, gerenciando layouts responsivos, animações e o design de interfaces por meio de modelos como Flexbox e Grid;
SVG: formato baseado em XML para gráficos vetoriais escaláveis, garantindo que imagens e animações mantenham a qualidade em qualquer resolução.
Semântica e dados:
XML e relacionados (XPath, XSLT, Schema): servem como base para o intercâmbio de dados estruturados, permitindo a transformação e validação rigorosa de informações;
RDF, SPARQL e OWL: tecnologias da web semântica que viabilizam dados conectados e consultas complexas por meio de metadados;
JSON-LD: formato leve para serialização de dados vinculados em JSON, facilitando a interpretação de conceitos por máquinas e motores de busca.
Acessibilidade e multimídia:
WCAG: conjunto de diretrizes que tornam o conteúdo web perceptível, operável, compreensível e robusto para pessoas com deficiência;
WAI-ARIA: atributos que aprimoram a acessibilidade de conteúdos dinâmicos, fornecendo informações críticas para tecnologias assistivas como leitores de tela;
WebRTC e WebVTT: padrões que possibilitam comunicação em tempo real e a inclusão de legendas temporizadas em conteúdos de vídeo e áudio.
Tecnologias emergentes:
WebAssembly (Wasm): formato binário que permite a execução de código de alto desempenho no navegador, operando junto ao JavaScript;
EPUB: padrão aberto para publicações digitais, otimizado para a leitura de e-books em diversos dispositivos e tamanhos de tela;
ActivityPub: protocolo de rede social descentralizado que permite a interação entre diferentes servidores e plataformas de forma federada.
Código CSS é um dos padrões abertos do W3C (Imagem: Reprodução/Unsplash)
Quais são os principais membros do W3C?
O World Wide Web Consortium é composto por mais de 350 organizações que colaboram para definir os padrões técnicos da internet. As principais categorias de membros são:
Líderes da indústria de tecnologia (Google, Apple, Microsoft): gigantes do setor que desenvolvem navegadores e plataformas, focando na padronização de linguagens essenciais como HTML, CSS e JavaScript;
Defensores da web aberta (Mozilla, Meta): organizações voltadas ao aprimoramento de tecnologias de código aberto, com ênfase em acessibilidade e especificações focadas em privacidade;
Líderes em cloud e dados (Amazon, IBM): empresa que direcionam esforços para integração de inteligência artificial, serviços em nuvem e padrões de web semântica;
Fundações e órgãos de padronização (World Wide Web Foundation, ICANN): entidades sem fins lucrativos que promovem a abertura da rede e colaboram na arquitetura de protocolos e nomes de domínio;
Escritórios regionais (W3C Brasil/NIC.br): representações locais, como a brasileira, que atuam na disseminação e no avanço dos padrões web em regiões geográficas específicas;
Instituições acadêmicas (MIT, Keio, Beihang): universidades que atuam como sedes administrativas do consórcio, oferecendo suporte de pesquisa e infraestrutura para o desenvolvimento técnico;
Governos e comissões internacionais (Comissão Europeia): órgãos governamentais que financiam iniciativas e orientam políticas digitais sobre temas críticos, como a privacidade de dados.
As principais big techs participam dos grupos de arquitetetura e comitês consultivos do W3C (imagem: Vitor Pádua/Tecnoblog)
Quais são as vantagens do W3C?
Estes são os pontos positivos da atuação do W3C:
Interoperabilidade universal: garante que sites funcionem de forma idêntica em diversos navegadores e dispositivos, eliminando fragmentações técnicas. Facilita a comunicação entre sistemas distintos ao estabelecer linguagens padronizadas como HTML e CSS;
Acessibilidade e inclusão: democratiza o acesso digital por meio das diretrizes WCAG, permitindo que pessoas com deficiência naveguem com autonomia. Fomenta o alcance global ao padronizar o suporte para leitores de tela e tecnologias assistivas;
Segurança e privacidade: fortalece a proteção de dados em transações online ao normatizar protocolos de criptografia e autenticação. Aumenta a confiança do ecossistema digital ao mitigar vulnerabilidades comuns e ataques cibernéticos;
Longevidade e inovação: assegura que conteúdos antigos permaneçam acessíveis no futuro, evitando obsolescência tecnológica precoce. Promove a inovação constante ao coordenar a colaboração entre big techs e a comunidade aberta;
Otimização de SEO e custos: melhora o posicionamento em motores de busca devido à estrutura de código limpa e sem erros sintáticos. Reduz gastos de desenvolvimento e manutenção ao usar padrões gratuitos, escaláveis e livres de royalties.
Quais são as desvantagens do W3C?
Estes são os pontos fracos do W3C:
Processo de padronização lento: a busca rigorosa por consenso entre centenas de membros atrasa a publicação de especificações, dificultando a resposta imediata às demandas urgentes da indústria;
Falta de sincroniza com o mercado: o ciclo de atualização é frequentemente mais lento que a evolução das tecnologias emergentes, motivando empresas a criarem soluções proprietárias ou grupos paralelos;
Alta complexidade técnica e de implementação: a densidade dos padrões exige desenvolvedores altamente qualificados e maior tempo de estudo, elevando os custos e o esforço inicial de desenvolvimento.
Ausência de poder de fiscalização: o W3C atua apenas como órgão recomendador, sem mecanismos para punir ou obrigar fornecedores a seguirem fielmente as diretrizes estabelecidas;
Fragmentação causada por interesses comerciais: gigantes da tecnologia muitas vezes priorizam agendas próprias, implementando variações de padrões que comprometem a interoperabilidade global proposta pelo consórcio.
Qual é a diferença entre W3C e WHATWG?
O World Wide Web Consortium (W3C) é um consórcio internacional liderado por empresas e acadêmicos que busca consenso global para criar padrões técnicos estáveis. Seu foco é garantir que a web permaneça interoperável, inclusiva e com diretrizes formais de longo prazo.
O Web Hypertext Application Technology Working Group (WHATWG) é uma comunidade formada pelos principais fabricantes de navegadores – Apple, Google, Microsoft e Mozilla – que desenvolve o HTML de forma ágil. Eles usam o conceito de “Padrão Vivo” (Living Standard), onde as especificações são atualizadas continuamente para refletir o que realmente funciona nos navegadores modernos.
Por anos, houve uma divisão entre as duas organizações, o que gerava confusão sobre qual modelo HTML os desenvolvedores precisavam seguir. Desde 2019, um acordo definiu que o WHATWG domina o desenvolvimento do HTML, enquanto o W3C foca na aprovação desses padrões e em outras áreas específicas.
Gmail prepara recurso para alterar o endereço @gmail.com (ilustração: Vitor Pádua/Tecnoblog)Resumo
O Gmail agora permite alterar o endereço de e-mail ou criar um alias com @gmail.com sem apagar o original.
O recurso está em fase de testes, inicialmente disponível em hindi, sugerindo testes na Índia.
O endereço antigo continua funcionando como alias, permitindo que mensagens cheguem à mesma caixa de entrada.
O Google começou a liberar um recurso aguardado há anos pelos usuários do Gmail: a possibilidade de alterar o endereço de email ou criar um novo alias (ou seja, um redirecionamento) sem precisar abandonar a conta original. A novidade apareceu em um documento de suporte da empresa e indica uma mudança relevante na forma como o serviço lida com identidades.
Até agora, o Gmail permitia apenas o uso de variações internas, mas não autorizava a troca efetiva do endereço principal. Com a nova função, o usuário ganha mais flexibilidade para reorganizar sua caixa de entrada, corrigir nomes antigos ou adotar um e-mail mais adequado ao uso profissional ou pessoal.
O que muda no Gmail?
Segundo o documento de suporte, o endereço de email associado à conta do Google é o principal identificador usado para acessar serviços como Gmail, Drive, YouTube e outros. “Esse endereço ajuda você e outras pessoas a identificar sua conta”.
Na sequência, o texto detalha a principal novidade: “Se quiser, você pode alterar o endereço de e-mail da sua Conta do Google que termina em gmail.com para um novo endereço de e-mail que também termine em gmail.com”. Isso significa que o usuário poderá definir um novo endereço principal, sem precisar criar uma conta do zero.
Outro ponto importante é que o endereço antigo não deixa de funcionar. Ele passa a atuar como um alias, permitindo que mensagens enviadas para qualquer uma das duas opções cheguem à mesma caixa de entrada. Na prática, o usuário pode manter dois endereços @gmail.com ativos simultaneamente.
A documentação ainda aponta que haverá um período de trava logo após criar um novo endereço no Gmail.
Usuário do Gmail poderá definir um novo endereço principal, sem precisar criar uma conta do zero (Imagem: Ana Marques/Tecnoblog)
Quem já pode usar o recurso?
O Google ainda não fez um anúncio oficial. No entanto, a existência do documento indica que o recurso já está em fase de liberação gradual. Por enquanto, o material foi encontrado apenas em hindi, o que sugere que os testes iniciais estejam concentrados na Índia antes de uma expansão global.
Usuários que já tiverem acesso encontrarão a opção dentro das configurações da conta do Google, com um link direto para a página de suporte que explica o processo. Não há, até o momento, um cronograma público para a liberação geral.
Serviços concorrentes, como Outlook e Proton Mail, permitem há anos a criação e a troca de aliases de forma mais ampla.
Saiba quais são os serviços de tecnologia que fazem parte do seu dia a dia (imagem: Vitor Pádua/Tecnoblog)
Serviços de tecnologia são ferramentas digitais intuitivas, como aplicativos e plataformas, criadas para facilitar a vida pessoal. Eles focam na experiência do usuário, priorizando a conveniência e a simplicidade em diversas tarefas do cotidiano.
Essas soluções facilitam o acesso a entretenimento e comunicação, além de garantir agilidade e segurança na rotina. Elas promovem o bem-estar ao transformar a interação humana em experiências integradas e orientadas por dados.
As categorias de serviços de tecnologia incluem streaming (Netflix), mobilidade (Uber) e comunicação (WhatsApp), além de nuvem (Google Drive) e inteligência artificial (ChatGPT). Cada grupo oferece recursos práticos que tornam as atividades diárias de consumo e navegação muito mais acessíveis.
A seguir, entenda o conceito de serviços de tecnologia, para que servem essas soluções e categorias em detalhes.
O que são serviços de tecnologia?
Serviços de tecnologia são soluções digitais, como apps e plataformas, voltadas para facilitar o cotidiano pessoal em áreas como entretenimento e comunicação. Diferente de ferramentas corporativas, eles priorizam a facilidade de uso e a conveniência por serem intuitivos e focados na experiência do usuário comum.
Para que servem as soluções em tecnologia?
As soluções tecnológicas otimizam processos ao integrar ferramentas digitais que agilizam a comunicação, o consumo e o acesso à informação. Elas conectam pessoas a serviços essenciais com rapidez, transformando tarefas complexas em ações simples e automatizadas do cotidiano.
Ao desenvolver essas inovações, as empresas de tecnologia garantem maior segurança e personalização. Esses recursos também promovem eficiência operacional e bem-estar, proporcionando experiências mais inteligentes e orientadas por dados para o usuário.
Os serviços de tecnologia estão divididos entre apps, plataformas e outras ferramentas que agilizam a comunicação e o acesso à informação (imagem: Vitor Pádua/Tecnoblog)
Quais são as principais categorias de serviços de tecnologia?
Os serviços de tecnologia costumam ser divididos em cinco categorias principais: streaming, mobilidade, comunicação, nuvem e inteligência artificial. Conheça os tipos de plataformas, aplicativos e softwares que pertencem a cada grupo.
1. Serviços de streaming
Serviços de streaming são plataformas online que transmitem áudio e vídeo em tempo real pela internet, eliminando a necessidade de baixar arquivos. Eles permitem o acesso imediato a conteúdos, como filmes, música e jogos, em diversos dispositivos com uma conexão ativa.
Esses ecossistemas oferecem catálogos sob demanda e transmissões ao vivo, adaptando a resolução da imagem conforme a estabilidade do sinal. Ademais, eles democratizam o entretenimento por meio de assinaturas e algoritmos que personalizam a experiência.
Streaming de músicas: reproduz músicas, podcasts e audiobooks sob demanda via internet, permitindo o consumo instantâneo de vastas bibliotecas sem ocupar o armazenamento local;
Streaming de vídeos (VOD): oferece filmes, séries e documentários em catálogos digitais, utilizando tecnologias de compressão para garantir alta definição e reprodução contínua;
Streaming de jogos (Cloud Gaming): executa jogos complexos em servidores remotos e transmite apenas a imagem para o usuário, permitindo jogar títulos pesados em dispositivos simples;
Transmissão ao vivo (Live streaming): foca na transmissão de eventos em tempo real, como competições de eSports, shows ou webinars, permitindo interação imediata entre o público e o criador;
Streaming de TV (IPTV): disponibiliza canais de televisão convencionais e grades de programação ao vivo através do protocolo de internet, substituindo cabos e antenas físicas;
Streaming educacional: proporciona acesso a cursos, aulas interativas e repositórios de conhecimento acadêmico, facilitando o aprendizado remoto com recursos de vídeo e áudio.
Netflix e Disney+ são exemplos de streaming de vídeo (imagem: Emerson Alecrim/Tecnoblog)
2. Serviços de mobilidade
Serviços de mobilidade são plataformas digitais que conectam usuários a diferentes modos de transportes e logística sob demanda em uma única interface funcional. Elas integram reservas, pagamentos e rastreamento em um único ecossistema para facilitar o deslocamento urbano e logístico.
Baseadas no modelo Mobility as a Service (MaaS), essas soluções priorizam o acesso em vez da posse, unindo transporte público e privado de forma multimodal. O objetivo é oferecer alternativas sustentáveis e flexíveis que reduzam o tráfego e melhorem a experiência de deslocamento coletivo.
Serviços de entrega: intermediam a entrega de refeições, compras de mercado e encomendas diversas, usando redes de entregadores para conectar estabelecimentos comerciais ao consumidor final com rapidez;
Serviços de transporte: conectam passageiros a motoristas particulares via aplicativos, oferecendo rotas otimizadas, preços dinâmicos e conveniência no deslocamento de porta a porta;
Serviços de navegação: utilizam GPS e dados em tempo real para fornecer rotas, alertas de congestionamento e estimativas de chegada, auxiliando tanto motoristas particulares quanto o transporte público;
Apps de transporte público inteligente: integram dados de ônibus, trens e metrôs em plataformas digitais, permitindo que usuários monitorem horários, lotação e, em alguns casos, paguem passagens de forma digital e unificada;
Apps de carona compartilhada (carpooling): facilitam a divisão de viagens entre pessoas que percorrem trajetos similares, reduzindo o número de veículos nas ruas, os custos de deslocamento e a emissão de poluentes.
Uber e 99 são populares aplicativos de transporte de passageiros e de entrega (imagem: Vitor Pádua/Tecnoblog)
3. Serviços de comunicação
Serviços de comunicação são plataformas e redes digitais que permitem a troca de informação por meio de chamadas de voz, mensagens e videoconferências. Eles facilitam a interação pessoal e empresarial, permitindo que os dados circulem de forma instantânea ou assíncrona globalmente.
Essas ferramentas funcionam por meio da internet ou redes de telecomunicações, suportando diversos formatos de mídia com alta escalabilidade. Embora ofereçam conectividade imediata, esses sistemas exigem medidas rigorosas de segurança para proteger a integridade dos dados transmitidos.
WhatsApp é um dos principais exemplos de serviços de comunicação (ilustração: Vitor Pádua/Tecnoblog)
4. Serviços de nuvem
Serviços de nuvem são plataformas baseadas na internet que oferecem armazenamento, sincronização e backup sob demanda. Eles permitem acessar arquivos e aplicativos sem depender de hardware físico pessoal.
Essas soluções também utilizam modelos de negócios (SaaS), oferecendo softwares prontos mediante assinaturas. O sistema automatiza processos para consumidores, facilitando o gerenciamento de fotos e documentos digitais.
Os programas do Office da Microsoft são um exemplo de serviço de nuvem no modelo SaaS (imagem: divulgação/Microsoft)
5. Serviços de inteligência artificial
Serviços de inteligência artificial são aplicativos e plataformas, como assistentes virtuais, chatbots e sistemas de recomendação, que facilitam tarefas cotidianas. Elas aprimoram atividades como buscas por voz, edição de imagens e sugestões de compras personalizadas para usuários comuns.
Utilizando aprendizado de máquina, essas ferramentas processam linguagem natural e reconhecimento de imagem para oferecer assistência intuitiva e em tempo real. Priorizam interfaces amigáveis e privacidade, estando presentes em dispositivos inteligentes por meio de assinaturas ou versões gratuitas.
ChatGPT é um dos principais serviços de inteligência artificial (imagem: Lupa Charleaux/Tecnoblog)
Qual é a diferença entre serviços de tecnologia de consumo e serviços de TI?
Serviços de tecnologia de consumo são plataformas e aplicativos voltados ao usuário final para entretenimento e conveniência pessoal, como streaming e navegação. Eles priorizam interfaces intuitivas e o acesso direto para facilitar o cotidiano do indivíduo.
Serviços de tecnologia da informação (TI) são soluções corporativas que gerenciam a infraestrutura de negócios, abrangendo desde segurança de redes até suporte de software. Eles focam em otimizar operações, garantir conformidade e minimizar interrupções para empresas e organizações.
Novo site do Simet aposta em mais ferramentas educativas (imagem: reprodução/NIC.br)Resumo
O Núcleo de Informação e Coordenação do Ponto BR (NIC.br) lançou uma nova versão do teste de velocidade de internet Simet, originalmente lançado em 2011. O novo medidor vai além dos números de download e upload, explicando ao usuário se a conexão é suficiente para tarefas como trabalho e entretenimento.
O NIC.br é o braço executivo do Comitê Gestor da Internet no Brasil (CGI.br), uma entidade sem fins lucrativos que coordena e integra as iniciativas de serviços de internet no país. É o mesmo órgão responsável, por exemplo, pelo registro de domínios terminados em “.br” e pelos Pontos de Troca de Tráfego (IX.br) que garantem a infraestrutura da rede nacional.
App avalia internet para uso diário
Ao contrário dos velocímetros tradicionais, que destacam apenas as taxas de download e upload, o novo Simet foca na “tradução” desses dados para o cotidiano.
O sistema cruza as métricas técnicas (como latência, jitter e perda de pacotes) com os requisitos reais de diferentes aplicações. Após o levantamento, o sistema informa se a rede está adequada para trabalho remoto, educação a distância (EAD), jogos online ou streaming de vídeo.
Simet demonstra se velocidade é útil para diversas atividades (imagem: Felipe Faustino/Tecnoblog)
Histórico e disponibilidade
Além do diagnóstico instantâneo, a ferramenta permite que o usuário acompanhe a evolução da qualidade da sua conexão ao longo do tempo. É possível salvar os resultados e comparar o desempenho em diferentes locais, como “casa”, “trabalho” ou “faculdade”, criando um registro histórico que pode ajudar na identificação de problemas.
Por ser uma ferramenta mantida por uma entidade setorial, o Simet promete isenção comercial nos resultados e não exibe publicidade. Além disso, os dados anonimizados coletados pelos testes ajudam o próprio NIC.br a mapear a qualidade da infraestrutura de telecomunicações em diferentes regiões do país, servindo de base para estudos e políticas públicas.
A atualização também ampliou o suporte do medidor. A ferramenta está disponível para navegador web e em apps nativos para dispositivos móveis (iPhone/iOS e Android) e computadores (Windows, macOS e Linux).
Amazon fez investimento bilionário em logística no Brasil (ilustração: Vitor Pádua/Tecnoblog)Resumo
A Amazon oferece entrega no mesmo dia com horário agendado em São Paulo e Rio de Janeiro, com janelas de três a seis horas.
Assinantes Prime têm frete grátis em compras acima de R$ 19, exceto para supermercado e livros, em que o mínimo é R$ 79; não assinantes pagam R$ 10,90.
A Amazon investiu R$ 13,6 bilhões no Brasil em 2024 para expandir sua rede logística com 250 centros, permitindo entregas precisas.
A Amazon anunciou, nesta segunda-feira (15/12), que produtos de mais de 30 categorias terão a opção de entrega no mesmo dia, com indicação do horário de chegada. Essa nova modalidade de entrega está disponível nas capitais de São Paulo e Rio de Janeiro.
Para assinantes Prime, o frete é grátis em compras a partir de R$ 19, exceto para itens de supermercado e livros — nesse caso, o mínimo necessário para não pagar a entrega é R$ 79. Abaixo desse valor, a taxa é de R$ 8,90. Para quem não é assinante Prime, o frete é sempre cobrado e custa R$ 10,90.
Como funciona a entrega com horário agendado da Amazon?
A empresa explica que esses horários são sempre indicados no formato de janelas de três a seis horas. “Ao acessar a loja, o consumidor visualiza as próximas janelas disponíveis e seleciona aquela que melhor se encaixa na sua rotina”, afirmou um porta-voz da empresa ao Tecnoblog.
Isso significa que o cliente sabe que o produto deve chegar no fim da manhã ou à tarde, por exemplo. Em alguns itens no site da varejista, já é possível visualizar o horário para entrega. Ao pedir um pacote de papel sulfite no fim da tarde, por exemplo, aparece a opção de entrega no dia seguinte, entre 10h e 13h.
Para quem não assina o Prime, o frete da entrega com hora marcada é R$ 10,90 (imagem: Giovanni Santa Rosa/Tecnoblog)
Vale notar que essa modalidade não cobre toda a cidade. Eu moro na Zona Norte de São Paulo e a entrega com horário agendado não aparece quando seleciono minha casa como destino, mas fica disponível quando altero o endereço para a Avenida Paulista.
Amazon confia em logística para cumprir promessa
A Amazon diz que essa precisão só foi possível por meio de investimentos significativos na malha logística, que conta com 250 centros logísticos no Brasil, sendo mais de 100 deles abertos ao longo de 2025. Segundo a companhia, mais de R$ 13,6 bilhões foram investidos no país somente em 2024.
“Trabalhamos com altos padrões operacionais para garantir que cada entrega seja cumprida dentro do prazo prometido”, afirma a companhia. “Você sabe quando vai receber, pode planejar seu dia em torno disso, e pode contar que vamos cumprir nossa promessa.”
A varejista já contava com entrega no mesmo dia sem horário marcado no Rio e em São Paulo. Esse modelo também está presente em Fortaleza, Recife e Belo Horizonte; ele deve ser expandido para mais cidades em 2026.
Pane afeta Spotify e iFood (foto: Thássius Veloso/Tecnoblog)
O serviço de streaming Spotify e a plataforma de delivery iFood passaram por problemas e ficaram indisponíveis nesta segunda-feira (15/12). Nos dois casos, as queixas de usuários começaram pouco depois das 11h, segundo os gráficos da plataforma DownDetector, que monitora falhas em serviços da web. Por volta das 12h, ambos começaram a ser reestabelecidos.
Falhas aconteceram quase ao mesmo tempo (imagem: Ana Marques/Tecnoblog)
A falha do Spotify foi global — usuários do Brasil e do exterior reclamaram nas redes sociais que o streaming ficou inacessível pelos apps e pelo navegador.
Nope not just you its down. I just checked down detector and it looks like everyone is unable to get on
Ainda não se sabe se há relação entre os incidentes, mas como eles começaram praticamente na mesma hora, existe a possibilidade de ser uma falha na infraestrutura usada pelas empresas.
O Tecnoblog entrou em contato com a assessoria de imprensa das duas companhias. O Spotify nos disse às 12h59 que a situação foi resolvida. Já o iFood declarou às 13h01 que o “problema pontual e de curta duração” foi solucionado.
Antena Ultra da Amazon Leo permite velocidades de até 1 Gb/s de download (imagem: divulgação/Amazon)Resumo
A Amazon Leo lançou a antena Ultra, oferecendo velocidades de download de até 1 Gb/s e upload de 400 Mb/s, com integração direta à nuvem para eliminar latência.
A antena Ultra é projetada para resistir a condições climáticas extremas, usando chips personalizados e algoritmos de processamento de sinal para minimizar a latência em operações críticas.
Testes com clientes selecionados, como JetBlue, Hunt Energy e Connected Farms, ocorrerão antes do lançamento comercial em 2026, com suporte técnico 24/7 e ferramentas de gerenciamento para clientes.
A divisão de satélites da Amazon, agora chamada de Amazon Leo (antigo Project Kuiper), apresentou nesta segunda-feira (24) a nova antena Ultra, capaz de oferecer velocidades de download de até 1 Gb/s e upload de 400 Mb/s. O dispositivo é voltado para empresas e setor público. Os testes com clientes selecionados serão feitos antes do lançamento comercial, em 2026.
Com mais de 150 satélites em órbita, a rede do Amazon Leo é pensada para conectar negócios em regiões remotas, como empresas de energia, transporte e agricultura. A antena foi projetada para resistir a temperaturas extremas e ventos fortes. Para tanto, foram retiradas partes móveis, o que facilita instalação e manutenção.
Excited to share new @Amazonleo Ultra is fastest satellite internet antenna ever built, delivering simultaneous download speeds up to 1 Gbps and upload speeds up to 400 Mbps, all powered by custom Leo silicon.
A antena Ultra usa chips personalizados e algoritmos de processamento de sinal para minimizar a latência, o que é especialmente importante para videoconferências e monitoramento de operações em tempo real.
De acordo com a Amazon, o equipamento promete velocidades de 1 Gb/s para download e 400 Mb/s para upload graças à tecnologia full-duplex, que permite transmissão e recepção simultâneas de dados. Isso é considerado importante para operações que exigem resposta imediata, como controle de equipamentos ou transmissão de imagens.
Chip da antena Ultra (imagem: divulgação/Amazon Leo)
Seus chips customizados desenvolvidos pela empresa utilizam algoritmos proprietários de processamento de sinal que prometem reduzir latência a níveis comparáveis a redes terrestres, mesmo em lugares com obstáculos climáticos como nuvens densas e chuvas.
Parcerias para validação técnica
A companhia aérea JetBlue está entre os primeiros clientes. Ela testará a antena Ultra para oferecer Wi-Fi gratuito em voos. Já a Hunt Energy, que tem operações de energia em regiões isoladas, utilizará a rede para monitorar equipamentos.
Amazon revela nova antena (imagem: divulgação)
Por sua vez, a Connected Farms, especializada em tecnologia agrícola, validará o uso de sensores dependentes de conexão com a internet em plantações remotas, onde a latência reduzida permitirá controle preciso de irrigação e colheita. Esses testes ajudarão a adaptar funcionalidades específicas para cada setor antes do lançamento em larga escala.
Próximo lançamento
O próximo lançamento de satélites está agendado para 15 de dezembro, em parceria com a ULA. Enquanto isso, a Amazon envia antenas das linhas Ultra e Pro para as empresas do programa de preview.
A companhia não divulgou preços, mas destacou o suporte técnico 24/7 e ferramentas de gerenciamento para clientes corporativos.
Rede da Cloudflare ao redor do mundo (imagem: divulgação)Resumo
A Cloudflare enfrentou um apagão de cinco horas devido a uma atualização incorreta no sistema anti-bot, afetando plataformas como ChatGPT e X.
O CEO Matthew Prince assumiu a responsabilidade e anunciou medidas técnicas, incluindo validação rigorosa de arquivos e botões de emergência globais.
A falha começou com uma consulta mal configurada no ClickHouse, causando duplicação de dados e erros HTTP 5xx.
A Cloudflare enfrentou sua pior interrupção desde 2019 na terça-feira (18/11), deixando fora do ar plataformas globais como ChatGPT, X e até o site do Tecnoblog por cerca de cinco horas. A falha foi causada por uma atualização incorreta no sistema anti-bot, que gerou sobrecarga em servidores críticos após duplicação acidental de dados de configuração.
Num comunicado oficial, seu CEO assumiu a responsabilidade pelo incidente, inicialmente confundido com um ataque DDoS, e anunciou quatro medidas técnicas para evitar novas quedas. Entre elas, estão mecanismos de desligamento emergencial e revisão rigorosa de arquivos internos, parte de esforços para fortalecer a infraestrutura da empresa.
Problema começou em sistema anti-bot
O CEO Matthew Prince explicou que a falha ocorreu durante atualização de segurança no ClickHouse, sistema de análise de dados usado internamente. Uma consulta mal configurada passou a listar colunas duplicadas após mudança de permissões. Isso fez o arquivo de configuração pesar duas vezes seu tamanho normal.
Clientes que não usavam a função anti-bot permaneceram online.
Gráfico do volume de erros HTTP 5xx na rede da Cloudflare em 18/11 (imagem: divulgação)
O sistema de proxy central entrou em colapso ao carregar o arquivo corrompido, gerando erros HTTP 5xx. Serviços como Workers KV e Cloudflare Access também foram afetados indiretamente. Inicialmente, a equipe suspeitou que fosse um ataque DDoS de grande escala.
Falha afetou serviços globais por horas
A partir das 8h28, cerca de 20% dos sites que usam a rede da Cloudflare começaram a apresentar falhas. Até a página que dá o status da operação da Cloudflare ficou offline, indicando falsamente suspeitas de ataque. A equipe identificou o real problema às 11h24.
“Dada a importância da Cloudflare no ecossistema da internet, qualquer interrupção em qualquer um dos nossos sistemas é inaceitável. O fato de ter havido um período em que nossa rede não conseguiu rotear tráfego é profundamente doloroso para cada membro da nossa equipe. Sabemos que falhamos com vocês hoje.”
– Matthew Prince, CEO da Cloudflare
A recuperação exigiu a substituição manual do arquivo defeituoso e a reinicialização dos servidores. O tráfego normalizou gradualmente até as 14h06.
“Em nome de toda a equipe da Cloudflare, gostaria de pedir desculpas pelos transtornos que causamos à Internet hoje.”
– Matheus Prince, CEO da Cloudflare
Empresa lista medidas para o futuro
A Cloudflare detalhou quatro medidas técnicas para evitar a repetição do problema. Em resumo, são elas:
Validação rigorosa de arquivos internos: Tratar configurações geradas pela própria Cloudflare como se fossem dados externos, com verificações automáticas de tamanho e formato antes de serem aplicados;
Botões de emergência globais: Criar mecanismos para desligar rapidamente funções problemáticas em toda a rede, como “freios de emergência” digitais;
Controle de relatórios de erro: Limitar automaticamente o volume de logs e registros detalhados de falhas (core dumps) para evitar que congestionem servidores durante crises;
Testes de cenários extremos: Simular falhas em módulos essenciais (como o proxy que roteia tráfego) para identificar gargalos e adicionar redundâncias, garantindo que um erro não derrube todo o sistema.
A companhia também reconheceu atrasos na recuperação de seu próprio dashboard interno durante a crise, prometendo melhorar a escalabilidade de sistemas críticos para equipes de resposta rápida. As medidas começam a ser implementadas imediatamente, com prioridade para os botões de emergência e a validação de arquivos.
Problema afeta sites em todo o mundo (imagem: divulgação)
O Cloudflare passa por problemas técnicos nesta terça-feira (18/11). Devido ao erro, ChatGPT, X e vários sites — incluindo o Tecnoblog — ficaram instáveis ou totalmente indisponíveis. Até agora, não houve uma explicação oficial sobre o que aconteceu.
A página de status do Cloudflare traz uma mensagem com o título “Rede Global da Cloudflare passa por problemas”. As 11h42, a questão foi dada como resolvida. Às 14h47, a empresa publicou o seguinte comunicado:
Os serviços da Cloudflare estão atualmente operando normalmente. Não estamos mais observando erros elevados ou latência em toda a rede.
Nossas equipes de engenharia continuam a monitorar de perto a plataforma e a realizar uma investigação mais profunda sobre a interrupção anterior, mas nenhuma mudança de configuração está sendo feita neste momento.
Neste ponto, é considerado seguro reativar quaisquer serviços da Cloudflare que foram temporariamente desativados durante o incidente. Forneceremos uma atualização final assim que nossa investigação estiver concluída.
O que aconteceu com o Cloudflare?
Oficialmente, a Cloudflare fala em investigação, mas o CTO da empresa, Dane Knecht, já deu alguns detalhes sobre o caso em sua conta do X.
“Resumindo, um bug latente em um serviço que sustenta nossa capacidade de mitigação de bots começou a apresentar falhas após uma alteração de configuração de rotina que fizemos”, explicou o executivo. “Isso causou uma degradação generalizada em nossa rede e outros serviços. Não foi um ataque.”
Knecht admitiu o erro e pediu desculpas pela falha. “A confiança que nossos clientes depositam em nós é o que mais valorizamos e faremos o que for preciso para reconquistá-la”, prometeu.
Erro no Cloudflare comprometeu grande parte da internet
A plataforma fornece proteção contra ataques DDoS e outras formas de tráfego inesperado. Ao tentar acessar um site protegido pela Cloudflare, o usuário recebia uma mensagem de erro 500, que indica falha no servidor. O aviso deixava claro que o problema é relacionado ao serviço.
A Cloudflare admitiu o problema às 8h48 (horário de Brasília):
A Cloudflare está ciente e investiga um problema que afeta vários clientes: erros generalizados de 500, O Painel do Cloudflare e a API também estão falhando. Estamos trabalhando para entender o impacto total e mitigar esse problema. Mais atualizações a seguir em breve.
O Tecnoblog foi uma das “vítimas” e ficou fora do ar ao longo da manhã desta terça-feira (18/11).
Tecnoblog também foi afetado por problema técnico no Cloudflare (imagem: Giovanni Santa Rosa/Tecnoblog)
No DownDetector, que monitora problemas técnicos em diversos serviços online, houve picos de relatos envolvendo o Cloudflare, o X, a AWS e a OpenAI.
Ironicamente, o próprio DownDetector caiu por algumas horas, já que exige uma verificação de segurança para ser acessado, e quem fornece esse sistema é a Cloudflare.
Diversos serviços ficaram fora do ar (imagem: Giovanni Santa Rosa/Tecnoblog)
Atualizado às 15h10 com as explicações da Cloudflare
Saiba o conceito de web e sua importância para a comunicação moderna (imagem: Vitor Pádua/Tecnoblog)
A World Wide Web (WWW), ou apenas web, é um sistema de documentos e outros recursos interconectados, acessados por meio da internet. Originalmente, ela foi criada em 1989 para facilitar o compartilhamento de informações entre cientistas.
Atualmente, a principal função da web é ser uma rede global de informações, tornando os dados massivos da internet navegáveis. Isso permite que usuários acessem, visualizem e compartilhem conteúdo, como páginas, imagens, vídeos e outras mídias.
Em essência, a internet é a infraestrutura de rede que conecta dispositivos globalmente, enquanto a web é o serviço de informações construído sobre ela. Assim, a WWW é o que a maioria das pessoas associa e usa como “a internet”
A seguir, conheça o conceito de web, para que ela serve e suas principais características. Também saiba a linha do tempo da evolução da World Wide Web.
A World Wide Web (WWW), ou simplesmente a web, é uma coleção de documentos e outros recursos interligados por hiperlinks, acessíveis globalmente por meio da internet. É o serviço que permite aos usuários navegar, acessar e interagir com essas informações usando um navegador web.
O que significa web?
O termo inglês “web”, além de significar “rede” ou “teia”, pode ser traduzido como um “sistema complexo de elementos interconectados”. Já a tradução de World Wide Web é simplesmente interpretada como “Rede Mundial de Computadores”.
Os navegadores são essenciais para acessar a web (imagem: Giovanni Santa Rosa/Tecnoblog)
Para que serve a web?
A web atua como um sistema de informações que permite acessar, compartilhar e interagir com conteúdo por meio da internet, usando interfaces intuitivas como sites e aplicativos. Sua função é disponibilizar e promover acesso a informações, dados e serviços, abrangendo desde notícias e entretenimento até serviços e interações sociais.
Apesar do propósito original de troca de informações entre cientistas, a web evoluiu para incluir funções cruciais como a comunicação em escala mundial. Ela é essencial para que empresas tenham presença digital e para que indivíduos compartilhem os próprios conteúdos globalmente.
Qual é a história da web?
A World Wide Web foi criada pelo cientista da computação Tim Berners-Lee em 1989, enquanto ele trabalhava no CERN, na Suíça. Sua proposta inicial visava um sistema de gerenciamento e compartilhamento de informações e documentos entre cientistas.
O trabalho ocorreu pouco depois do surgimento da internet e, em 1990, Berners-Lee desenvolveu as três tecnologias centrais: a linguagem HTML, o protocolo HTTP e o sistema de endereços URLs. No mesmo período, ele também criou o primeiro navegador chamado “WorldWideWeb”.
O primeiro website e servidor web da história, hospedado no CERN, entrou em funcionamento em 1991. Logo em seguida, em 1993, a organização tornou o software da World Wide Web de domínio público, permitindo seu uso sem royalties.
Essa decisão estratégica foi essencial para a rápida expansão do sistema, além de fomentar o amplo desenvolvimento e adoção. Uma ação que fez a web se tornar a plataforma global de informações e comunicação que conhecemos hoje.
Tim Berners-Lee, inventor da World Wide Web (imagem: Elon University/Flickr)
Qual é a linha do tempo da evolução da web?
A evolução da web é dividida em três eras principais:
Web 1.0: somente leitura (1989 – 2000)
1989 – 1991: Tim Berners-Lee inventou a World Wide Web no CERN, desenvolvendo o a linguagem HTML, o primeiro servidor e navegador, visando ser um “sistema de informação universalmente ligado”;
1993: o CERN disponibilizou a web em domínio público, e o navegador gráfico Mosaic foi lançado, facilitando o acesso ao serviço pelo público geral;
1994: é fundado o World Wide Web Consortium (W3C), liderado por Berners-Lee, com a missão de desenvolver padrões abertos para garantir o crescimento e interoperabilidade da web a longo prazo;
1995 – 1999: período de expansão e estabelecimento da era Web 1.0, focada em somente leitura com páginas estáticas e a ascensão dos pioneiros do e-commerces (Amazon, eBay).
Web 2.0: a web social e interativa (2000 – 2010)
2000 – 2010: década que marcou a ascensão de conteúdo gerado pelo usuário, mídias sociais (Facebook, YouTube), blogs e sites dinâmicos, tornando a web interativa e centralizada em grandes plataformas;
2004: o termo Web 2.0 foi popularizado, enfatizando a web como uma plataforma de participação e colaboração, impulsionadas por tecnologias como AJAX (Asynchronous JavaScript and XML) que criavam experiências e aplicações mais ricas e interativas;
2007: o lançamento do primeiro iPhone em 2007 inicia a revolução móvel, forçando os desenvolvedores a priorizarem o design responsivo para o acesso via dispositivos portáteis;
2010: a adoção generalizada da computação em nuvem (AWS, Azure) permitiu a escalabilidade e o armazenamento de grandes volumes de dados, essenciais para as plataformas sociais.
Web 3.0: a web inteligente e descentralizada (2010 – Presente)
2010: o foco mudou para a computação móvel e a adoção das características da Web3, buscando uma internet mais inteligente, aberta e descentralizada;
2015: a tecnologia blockchain e a ideia de descentralização ganharam força, servindo de base para criptomoedas, NFTs e aplicativos descentralizados (dApps);
2020: a integração de Inteligência Artificial (IA) e Machine Learning se intensificou, visando oferecer experiências mais preditiva e personalizadas aos usuários;
Futuro: a evolução continua com o desenvolvimento de metaversos e tecnologias de Realidade Virtual/Aumentada, visando experiências mais imersivas e interoperáveis.
Web3, ou Web 3.0, foca em um ambiente descentralizado baseado em blockchain (imagem: Vitor Pádua/Tecnoblog)
Como a web funciona?
A web opera por meio de um modelo cliente-servidor, onde o navegador (cliente) inicia a comunicação enviando uma solicitação de página. Em seguida, o servidor web processa esse pedido e devolve os dados da página requisitada de volta ao navegador para que ela possa ser exibida.
Este processo começa com o Domain Name System (DNS), que traduz o endereço do site legível por humanos (URL) para um endereço IP numérico. O navegador usa o protocolo HTTP para enviar a solicitação para o servidor, que foi localizado usando o endereço IP encontrado.
O servidor recebe a solicitação HTTP e localiza os arquivos necessários da página, como HTML, CSS e JavaScript, que estão armazenados em seus discos. Após a localização, o servidor empacota esses arquivos e os transmite de volta ao navegador como uma resposta HTTP estruturada.
Ao receber a resposta, o navegador interpreta o HTML para estruturar o conteúdo e aplicar o CSS para a apresentação visual (estilo e layout). Ele também executa o JavaScript para interatividade, finalizando a renderização de todos os dados para exibir a página completa e funcional na tela do dispositivo.
Quais são as características da web?
Estas são algumas das principais características e tecnologias da web:
Hipertextualidade: oferece a conexão entre diferentes documentos e recursos por meio do uso de hiperlinks, possibilitando a navegação online não-sequencial e interconectada entre páginas;
Interatividade: permite a participação ativa do usuário, possibilitando ações como deixar comentários, dar feedback e interagir em fóruns e plataformas sociais;
Conteúdo dinâmico: o conteúdo pode ser constantemente atualizado e alterado em tempo real, inclusive em resposta à interação do usuário, diferente de mídias estáticas;
Multimodalidade: inclui uma variedade de mídias além de texto, como imagens, áudio e vídeo, sendo estruturadas e exibidas nos navegadores por meio de código HTML e JavaScript;
Acessibilidade: os sites podem ser acessados em vários dispositivos, como desktop e celulares, tornando as informações amplamente disponíveis e suportando o conceito de cache de aplicativo para uso offline;
Descentralização de acesso: não possui um ponto de partida único, isso significa que uma URL é um endereço online que permite que qualquer página seja o ponto de entrada para a navegação;
Evolução dinâmica: está em constante mudança, com surgimento contínuo de novas tecnologias, conteúdos e usuários, impulsionando a expansão e aprimoramento da “evolução da web”;
Natureza distribuída: o conteúdo é armazenado em inúmeros servidores espalhados globalmente, definindo a web como um sistema descentralizado, em vez de um repositório centralizado de informações.
O uso de hiperlink para a navegação é uma das principais caractéristicas da web (imagem: Vitor Pádua/Tecnoblog)
Qual é a diferença entre web e internet?
A web é um sistema de informações que opera sobre a infraestrutura da internet, consistindo em uma coleção de documentos interligados e outros recursos. Ela é acessada por meio de navegadores usando o protocolo HTTP, permitindo que os usuários tenham acesso às informações e conteúdos disponíveis.
A internet é a rede global de computadores interconectados que forma a infraestrutura global para a comunicação digital. Ela consiste em servidores e outros hardwares que fornecem o ambiente essencial para que todos os dados circulem.
Qual é a diferença entre web e páginas da web?
A web é um sistema global de documentos interconectados e outros recursos, como textos, imagens e vídeos, acessados por meio da internet. É uma estrutura abrangente que permite a navegação online, o compartilhamento de informações e a comunicação mundialmente.
Uma página da web é um documento único ou arquivo digital específico que reside na estrutura da web e pode ser visualizado em um navegador. Ela contém o conteúdo real que o usuário interage, como texto e mídia, identificada por um endereço específico (URL).
Qual é a diferença entre web e aplicação web?
A web é um sistema global de documentos e informações interconectados acessados por meio da internet, servindo como uma biblioteca de conteúdo para visualização. Ela é a infraestrutura de informação que torna a internet utilizável para o público, permitindo a navegação via hiperlinks.
Saiba o que é hiperlink e como eles são essenciais para o uso da internet (imagem: Reprodução/iStock)
Os hiperlinks, ou somente links, são elementos interativos que estabelecem a conexão entre diferentes páginas ou recursos no ambiente da internet. Eles permitem a navegação fluida ao direcionar o usuário para um novo destino digital após uma interação.
O funcionamento dos links é baseado em uma URL de destino, o endereço específico para onde o usuário será levado. Quando acionados, esses elementos instruem o navegador a buscar e carregar o conteúdo referente àquele endereço na internet.
Existem três tipos principais de hiperlinks: links internos (conectam páginas dentro do mesmo site), externos (apontam para outros domínios) e backlinks (quando outros sites apontam para um determinado site). Eles são cruciais para a estrutura e o SEO de qualquer página da web.
A seguir, entenda o conceito de hiperlinks, para que eles servem e a sua importância na internet. Também descubra os diferentes tipos de links e quais os elementos de uma página que costumam ser hiperlinkados.
Um link é um elemento interativo de uma página web, como texto, imagem ou botão, que redireciona o usuário para outra página ou recurso ao ser acionado. Essencialmente, o hiperlink é o mecanismo que interliga as páginas, permitindo a navegação fluida e é a estrutura fundamental da internet.
O que significa “link”?
O termo “link” significa ligação, conexão ou vínculo em inglês, indicando uma referência a algo “além” ou “posterior”. No contexto de internet, ele representa uma conexão que permite a transição entre recursos digitais, como documentos ou páginas da web.
A origem do conceito reside no hipertexto, um sistema que organiza dados não-linear e possibilita a navegação entre diferentes documentos ou seções por meio de ligações diretas. Aqui, o prefixo “hiper” significa “além”, enfatizando que essas conexões superam o texto linear tradicional.
Por essa razão, o termo “link” é usado como um sinônimo derivado da abreviação de “hiperlink” para descrever essa ligação que permite ir de um recurso para outro com um clique ou toque. Ou seja, a hiperligação é a base para a navegação mais dinâmica e interativa na web.
Os links auxiliam na navegação e interação com as páginas de internet (imagem: Reprodução/Mozilla)
Para que servem os hiperlinks?
Os hiperlinks possibilitam conectar recursos na web, transformando a navegação em uma experiência intuitiva e interativa. Eles permitem que o usuário interaja com um elemento de texto ou imagem e seja levado a outro recurso, como uma página web, documento, arquivo de mídia ou um local específico na mesma página.
Sua função é estruturar a informação e deixar a navegação eficiente dentro e entre sites, facilitando o movimento do usuário entre seções e domínios. Os hiperlinks também são cruciais para citar fontes e fornecer referências adicionais sem sobrecarregar o texto principal, enriquecendo o conteúdo e criando credibilidade.
Como funcionam os hiperlinks?
Os hiperlinks são baseados em HTML (Hypertext Markup Language), a principal linguagem para a criação de páginas da web. Cada link incorpora um atributo chamado “href” (hyperlink reference), que indica um endereço de destino (URL) para onde o usuário será levado.
Este mecanismo é composto por dois componentes principais: a âncora de origem, o texto, imagem ou outro elemento interativo na tela; e a âncora de destino, a URL completa inserida no href para qual a navegação deve prosseguir.
Quando um usuário interage com a âncora de origem, o navegador web interpreta o código HTML, identifica o valor do atributo href e inicia a comunicação. Este processo dispara uma requisição de dados por meio do protocolo HTTP (Hypertext Transfer Protocol) para o servidor que hospeda o endereço de destino.
A resposta a requisição geralmente resulta no carregamento de um novo recurso exibido pelo navegador, como outra página web ou um arquivo. Se o href não tiver sido preenchido corretamente, o link será “quebrado” e o usuário será direcionado para uma página de erro em vez do conteúdo desejado.
Dessa forma, os hiperlinks permitem a navegação fluida e interligada, transformando documentos isolados em uma rede global de informações. Facilitando tanto a experiência dos usuários quanto de quem gerencia e deseja conectar as páginas na web.
Quando o usuário interage com um link, o navegador lê o atributo href e direciona para página indicada (imagem: Reprodução/Seobility)
Quais são os tipos de hiperlinks?
Existem três tipos principais de hiperlinks:
Links internos (Inbound links): direcionam o usuário para uma página, seção, formulário ou arquivo dentro do mesmo domínio ou website, facilitando a navegação e a hierarquia do conteúdo;
Links externos (Outbound links): direcionam o usuário da página atual para uma página ou recurso hospedado em um domínio completamente diferente, o que pode ser usado para citar fontes ou fornecer informações complementares;
Backlinks (Incoming links): são links que vêm de páginas de outros websites (domínios diferentes) e apontam de volta para uma página no próprio site, sendo cruciais para a autoridade e o SEO.
Quais elementos podem ser hiperlinkados?
Esses são alguns elementos que podem ser usados para criar webpage links e direcionar o usuário a outros recursos:
Texto: usa uma palavra, frase ou bloco de texto para criar um link que direciona o usuário a outro recurso, seção do mesmo domínio ou site externo;
E-mail: texto ou um imagem com link que inicia automaticamente a aplicação de e-mail padrão do usuário com o endereço de e-mail pré-preenchido, facilitando o contato direto;
Elementos de lista: itens em listas ordenadas ou não ordenadas podem ser linkados com um texto âncora, servindo como menus de navegação ou listas de conteúdo interativo;
Imagem: permite que uma figura, foto, logotipo ou ícone funcione como um link interativo, levando o usuário para uma nova página ou a um arquivo específico;
Botões: elementos visuais projetados para serem interativos, como “Saiba Mais” ou “Comprar Agora”, que atuam como links para iniciar ações ou levar a páginas de destino relevantes;
Áreas de mapa de imagem (image maps): permite que diferentes regiões de uma única imagem grande, como um mapa geográfico ou um diagrama, sejam links independentes com destinos distintos;
Elementos de bloco: blocos inteiros de conteúdo podem ser transformados em um link para tornar grandes áreas da interface interativos, melhorando a experiência do usuário em cartões de produto, por exemplo.
Textos âncoras são elementos que permitem que o usuário vá até um determinado local da mesma página (imagem: Reprodução/Mozilla)
Qual é a importância dos hiperlinks para a internet?
Os hiperlinks são o elemento fundamental que torna a internet uma rede interconectada e dinâmica, permitindo a navegação entre documentos e recursos. Eles definem o que é a World Wide Web, estruturando um amplo universo de dados.
Os links desempenham um papel vital na experiência de navegação dos usuários, pois facilitam o fluxo e o acesso rápido a informações, melhorando a usabilidade e a arquitetura do conteúdo. Eles são a tecnologia-chave por trás de toda a navegação e interação digital na web moderna.
A importância dos hiperlinks se estende ao SEO (Search Engine Optimization), onde os mecanismos de busca os utilizam para descobrir novas páginas e indexar o conteúdo. Eles também determinam a autoridade e a relevância de um site, estabelecendo a hierarquia e o valor do conteúdo.
Qual é a diferença entre link e URL?
Um link de internet é um elemento interativo incorporado em um documento digital, geralmente texto ou imagem, que o usuário pode interagir para navegar. Ele usa o endereço completo do URL para executar a função de redirecionar o usuário para o recurso de destino.
Um localizador uniforme de recursos (URL) é um endereço padronizado e estático que especifica a localização exata de um recurso na web, como uma página ou imagem. Ele é uma sequência de caracteres que permite que o navegador encontre e acesse o recurso solicitado pelo usuário.
Qual é a diferença entre link e página da web?
Um link é um elemento interativo em uma página, frequentemente texto, uma imagem ou um botão, que funciona como uma ferramenta de navegação. Sua função principal é redirecionar o usuário de um ponto de partida para outro recurso ou página da web distinta.
Página da web é um documento único que contém o conteúdo real, como texto, imagens e vídeos, exibido na janela do navegador. Ele serve como o destino que o usuário acessa após interagir com um link.
Redes sociais serão responsabilizadas pelo conteúdo (ilustração: Mariia Shalabaieva/Unsplash)Resumo
O STF decidiu que redes sociais e serviços online são responsáveis por conteúdos de ódio, alterando a interpretação do artigo 19 do Marco Civil da Internet.
As plataformas devem prevenir e coibir publicações discriminatórias, com mecanismos de monitoramento e resposta rápida a denúncias.
A decisão exige revisão das políticas de moderação das plataformas, alinhando-se a legislações como o Digital Services Act da União Europeia.
O Supremo Tribunal Federal (STF) publicou, nesta quarta-feira (05/11), a decisão do julgamento que muda a interpretação do artigo 19 do Marco Civil da Internet, de 2014. Por maioria, os ministros decidiram que plataformas como X, YouTube, TikTok e Instagram passam ser responsáveis pelo conteúdo veiculado na plataforma.
Dessa maneira, o Supremo entende agora que o dever de moderação das plataformas deve se estender a casos de discurso de ódio, especialmente os que atentem contra grupos protegidos pela Lei 7.716/1989, que criminaliza práticas de discriminação racial, religiosa ou de origem. A decisão foi formalizada nos acórdãos dos Recursos Extraordinários 1.037.396 e 1.057.258.
O que muda com a decisão?
STF obriga plataformas a coibir crimes de ódio (foto: Lupa Charleaux/Tecnoblog)
Com a nova interpretação, as plataformas terão obrigação de prevenir e coibir publicações que configurem crimes de discriminação, cabendo a elas manter mecanismos de monitoramento e resposta ágil às denúncias.
A mudança coloca o Brasil mais próximo de legislações como o Digital Services Act (DSA) da União Europeia, usado de exemplo de proteção de usuários e a responsabilização de grandes plataformas.
Plataformas deverão revisar políticas
Big techs vão no caminho contrário internamente (foto: dole777/Unsplash)
Com a publicação dos acórdãos, o entendimento passa a ter efeito vinculante, ou seja, deve orientar decisões de tribunais em todo o país. A decisão não revoga o Marco Civil, mas redefine a forma como seu artigo 19 é aplicado, criando uma exceção para casos de discurso de ódio e discriminação.
Para as plataformas, o novo cenário exige revisão das políticas internas de moderação e de resposta a denúncias, especialmente em relação a conteúdos racistas, homofóbicos, transfóbicos e antissemitas – reconhecidos pelo próprio STF, em decisões anteriores, como crimes de ódio equivalentes.
Entretanto, no caminho oposto, as próprias big techs têm adotado uma postura oposta internamente. A Meta, dona do Facebook, Instagram e Threads, reescreveu neste ano sua políticas de “conduta odiosa”, substituindo trechos que antes proibiam acusações e descrições desumanizantes contra minorias.
Já o X/Twitter promoveu cortes nas equipes de moderação e a reintegração de contas antes banidas por violar regras de ódio. As medidas foram adotadas após o ingresso de Elon Musk no negócio.
A Black Friday 2025 acontece no dia 28 de novembro, mas quem acompanha promoções sabe: os melhores descontos em celular, tablet, notebook e outros eletrônicos começam — e muitas vezes terminam — antes da data oficial.
Reunimos aqui as melhores ofertas e cupons da Black Friday no Magalu, Mercado Livre, Amazon e outras grandes lojas para você aproveitar agora mesmo.
Além disso, veja como se preparar para a Black Friday e a Black November, com dicas para economizar e evitar fraudes nas compras online.
Black Friday 2025: promoções, cupons de desconto e mais
Tudo o que você precisa saber sobre a Black Friday 2025
Quando é a Black Friday 2025?
Em 2025, a data oficial da Black Friday será o dia 28 de novembro, já que ela é sempre comemorada na última sexta-feira do mês. Mas nos últimos anos, lojas como Amazon e Mercado Livre têm adiantado suas ofertas para todo o mês de novembro, adotando a chamada Black November ou o Esquenta Black Friday.
Portanto, se você não pode passar a madrugada de quinta (dia 27) pra sexta (28) acordado, vale a pena já ficar de olho e aproveitar os descontos imperdíveis que aparecem ainda no decorrer do mês. Especialmente por aqueles produtos mais concorridos ou com condições de parcelamento especiais.
O que significa Black Friday?
A Black Friday é o maior evento anual para quem busca ofertas, cupons de desconto e outras promoções. Nos Estados Unidos, a data sucede o Dia de Ação de Graças (Thanksgiving Day), e marca o início da temporada de compras de final de ano – um costume que foi seguido no Brasil e em outros países.
Quais lojas participam da Black Friday?
Todas as principais lojas do varejo brasileiro participam da Black Friday. Sendo que algumas já estão até com páginas de destaque para os produtos participantes da campanha, como:
Como conseguir os melhores descontos na Black Friday?
Para aproveitar a Black Friday 2025 seja rápido porque os maiores descontos duram pouco. Participe dos canais do Achados no WhatsApp ou Telegram e receba ofertas de verdade selecionadas por uma curadoria que analisa desde o histórico de preços até os aspectos positivos e negativos de cada produto.
Black Friday: canal do Achados do TB traz as melhores ofertas (ilustração: Vitor Pádua/Tecnoblog)
Além disso, se planeje com antecedência. Se ainda não souber o que comprar na Black Friday, o Tecnoblog preparou diversos guias para te ajudar a escolher o celular, tablet ou notebook ideal para seu tipo de uso, e até acessórios como monitores, caixas de som e webcams.
Samsung Internet está chegando aos PCs Windows (imagem: divulgação)Resumo
Samsung Internet ganhou uma versão desktop para Windows, que está sendo lançada em beta nos Estados Unidos e na Coreia do Sul.
A versão web do famoso navegador mobile terá foco em recursos de IA do Galaxy AI e integração entre dispositivos.
O navegador oferecerá tradução e resumo de páginas, sincronização de favoritos, histórico e senhas, além de manter recursos de privacidade.
O popular navegador para dispositivos móveis da Samsung chegará aos computadores com Windows. A versão beta do browser está sendo lançada hoje (30/10) nos EUA e na Coreia do Sul, com expectativa de expansão para outras regiões. A nova versão foca em recursos de IA do pacote Galaxy AI e na sincronização de dados entre dispositivos.
A expansão coloca o Samsung Internet em competição direta com o Google Chrome, o Microsoft Edge e outras plataformas emergentes que também apostam em inteligência artificial, como o Dia e o Opera Neon, browser que nós testamos aqui no Tecnoblog.
Outras companhias propriamente de IA, como Perplexity e OpenAI, também lançaram navegadores: o Comet e o ChatGPT Atlas, respectivamente.
O que o Samsung Internet oferecerá no PC?
O principal diferencial da versão de desktop será a integração nativa com o Galaxy AI. Segundo a Samsung, o navegador inclui “capacidades iniciais” do pacote de IA, focadas no assistente de navegação.
A ferramenta permitirá, por exemplo, traduzir e resumir páginas da web com um clique, de forma similar ao que já existe nos celulares da marca.
Além da IA, o foco da Samsung é a continuidade entre dispositivos. O browser para PC terá sincronização de favoritos, histórico de navegação e senhas com o aplicativo no Android.
Navegador terá integração entre os dispositivos (imagem: divulgação)
O Samsung Internet também manterá recursos de privacidade do irmão móvel, como um painel de privacidade para visualizar rastreadores e bloquear pop-ups.
O site 9to5Google especula que o navegador seja baseado em Chromium, o que, se confirmado, deve garantir suporte a extensões populares, como bloqueadores de anúncios, um dos motivos da popularidade do app no Android.
Não é a primeira vez
O suporte nebuloso a essas funcionalidades foi um dos motivos para o fracasso da primeira tentativa da Samsung em trazer o navegador para desktops há dois anos — sim, isso ocorreu.
Segundo relatos, a versão — também baseada no Chromium — permitia sincronizar histórico, favoritos, abas abertas entre o PC e dispositivos Galaxy, mas muitas funcionalidades não estavam completas, como a sincronização de senhas.
iFood fica fora do ar (ilustração: Vitor Pádua/Tecnoblog)
Consumidores se queixam de que o iFood está fora do ar na noite desta segunda-feira (27). O problema começou por volta das 19h, segundo as reclamações registradas na plataforma DownDetector, de acompanhamento de serviços digitais.
Ainda não se sabe o motivo do problema, que afeta tanto iPhone quando smartphones com Android. Nos parece ser um bug mais limitado, já que outros consumidores conseguem usar normalmente o iFood.
Proposta da Anatel também visa intensificar o combate à informalidade (imagem: Vitor Pádua/Tecnoblog)Resumo
Anatel sugeriu a criação de um laboratório para combater provedores clandestinos de internet, em parceria com o Ministério da Justiça.
A iniciativa prevê uma solução de conformidade para regularizar pequenos provedores e coibir a venda de equipamentos não homologados.
Proposta surge em meio a mudanças regulatórias: provedores com até 5 mil acessos, antes isentos de registro, têm até 20 de outubro de 2025 para solicitar autorização.
A Agência Nacional de Telecomunicações (Anatel) sugeriu a criação de um laboratório para combater provedores de internet clandestinos e irregulares. A medida foi apresentada ontem (21/10) pelo conselheiro Edson Holanda, durante o evento NEO, em Salvador (BA), e seria uma colaboração com o Ministério da Justiça.
Holanda citou uma estratégia de duas frentes. Além da cooperação com o Ministério da Justiça, foi proposta uma “solução de conformidade via atacado”. Não há muitos detalhes, mas a medida poderia permitir a regularização de provedores informais por meio do uso da infraestrutura de grandes operadoras.
Dessa forma, seria possível distinguir o pequeno empreendedor que atua na informalidade, muitas vezes devido a barreiras burocráticas, daquele que opera em associação com atividades criminosas.
O conselheiro também mencionou a necessidade de ampliar o diálogo com o setor de comércio eletrônico (e-commerce). A medida poderia brecar a venda de equipamentos de telecomunicações não homologados, que servem de base para a operação de redes clandestinas e para a pirataria de conteúdo audiovisual.
Combate à pirataria esbarra na expansão do crime organizado
A sugestão de criar um laboratório conjunto com o Ministério da Justiça visa montar uma frente de inteligência dedicada a investigar e desarticular essas operações, que usam o serviço de internet como ferramenta de controle territorial e fonte de receita.
O diagnóstico da Anatel e de órgãos de segurança é que, em diversas regiões do país, a prestação do serviço deixou de ser uma atividade comercial informal para se tornar um monopólio controlado por facções. Segundo a Agência Brasil, somente no Rio de Janeiro, em julho deste ano, 80% das empresas de internet que atuam em comunidades da capital estão sob controle ou associadas a grupos criminosos.
A Anatel aborda a prática como concorrência desleal, já que os operadores clandestinos não pagam impostos nem cumprem obrigações trabalhistas, afetando diretamente cerca de 23 mil pequenos provedores regulares. Para o consumidor, o serviço irregular pode trazer instabilidade e ausência de respaldo legal, já que não há fiscalização nem possibilidade de recorrer à agência em caso de problemas.
Proposta surge após mudança regulatória
Iniciativa surge em meio à intensificação de fiscalização da Anatel (ilustração: Vitor Pádua/Tecnoblog)
A nova estratégia foi proposta em um momento de escalada das ações da Anatel contra a prestação irregular de serviços. Em junho de 2025, a agência aprovou a Resolução Interna nº 449, que estabeleceu um plano de combate à concorrência desleal.
A principal medida desse plano foi a suspensão da dispensa de outorga para empresas com até 5 mil acessos. Antes, esses pequenos provedores podiam operar somente com uma notificação da agência. Agora, são obrigados a solicitar uma autorização formal, nos mesmos moldes de empresas maiores.
O plano foi motivado por estudos da própria Anatel, que revelaram um alto nível de informalidade e omissão de dados. Segundo a agência, mais de 41% das empresas habilitadas não enviavam informações obrigatórias sobre números de acessos. Entre as empresas dispensadas da outorga, o índice de omissão era de mais de 55%.
Com a nova resolução, a Anatel fixou um prazo para que todos os provedores antes isentos de registro se regularizassem — período que se encerra no fim deste mês. De acordo com o portal Convergência Digital, quase 6 mil empresas ainda não haviam solicitado a outorga até 20 de outubro de 2025.
HTTP é o protocolo de comunicação usado para abrir sites da web (imagem: Igor Shimabukuro/Tecnoblog)
Uma página da web é um documento digital da internet, que exibe conteúdo como textos, mídia e links. Ela é uma unidade fundamental para a construção de um website completo, formado por um conjunto de documentos interligados.
Sua função principal é ser um ponto de contato e distribuição de informação ou serviços digitalmente. Uma página online permite que empresas e indivíduos se comuniquem, vendam produtos ou compartilhem conhecimento com o mundo.
O funcionamento das páginas de internet se baseia na interação entre o navegador do usuário e um servidor web. O navegador solicita o documento ao servidor que envia de volta, permitindo que a página seja renderizada e exibida na tela do usuário.
A seguir, entenda o conceito de uma página da web, suas funções e os diferentes tipos.
Uma página web é um documento digital único, acessado por meio de uma URL exclusiva e exibido em um navegador. Ela contém texto, imagens e multimídia, representando uma das unidades de informação que compõem um website na internet.
Para que serve uma página da web?
Uma página de internet tem o propósito fundamental de apresentar conteúdo e informações aos usuários, sendo visualizada por meio de um navegador. Ela atua como um bloco essencial para composição de qualquer website.
Seu uso abrange desde a divulgação de notícias e a venda de produtos, até a oferta de serviços e aplicações online sofisticadas. Por isso, é vital para a comunicação e o comércio digital.
Uma página da web apresenta conteúdo e informações ao usuário, fazendo parte de um website (imagem: Oberon Copeland/Unsplash)
Como uma página da web funciona?
O funcionamento de uma página web começa quando o usuário insere ou clica na URL de um site no navegador, que imediatamente envia uma requisição ao servidor. Essa solicitação é um pedido direto pelos arquivos essenciais necessários para carregar o documento desejado.
O servidor web processa o pedido, localiza os arquivos da página e os devolve ao navegador em pacotes de dados. Esses arquivos cruciais incluem o código HTML para a estrutura do conteúdo, CSS para o estilo visual e JavaScript para as interações dinâmicas.
Ao receber esses dados, o navegador inicia a renderização da página utilizando o HTML para definir o conteúdo e a hierarquia. Em seguida, ele aplica o CSS, que controla todos os aspectos da aparência visual, como layout, cores e tipografia.
Por fim, o navegador executa o JavaScript incluído para habilitar as funcionalidades dinâmicas e interatividade com o usuário. Após esse processamento completo e sequencial de todos os elementos, a página web final é exibida completamente na tela do usuário.
Quais são os tipos de páginas da web?
Existem quatro tipos principais de páginas da web:
Página estática: exibe um conteúdo fixo, pré-escrito, idêntico para todos os visitantes que acessam o endereço web. Exemplo: páginas institucionais simples, onde a informação muda raramente;
Página dinâmica: gera conteúdo em tempo real, extraindo informações de um banco de dados ou com base nas ações do usuário. Exemplo: páginas de resultados de pesquisa ou feeds de mídia social, cujo conteúdo é personalizado a cada visita;
Aplicações de página única (Single-Page Applications – SPAs): carregam todos os recursos necessários no primeiro acesso, atualizando o conteúdo dinamicamente sem recarregar a página inteira. Exemplo: Gmail, Google Maps e outras aplicações baseadas em navegador (web apps);
Sistema de gerenciamento de conteúdo (Content Management Systems – CSM): permite que usuários não-técnicos criem, modifiquem e gerenciem o conteúdo de uma página sem a necessidade de codificação avançada. Exemplo: WordPress, Joomla e Drupal, que facilitam a administração de blogs e sites corporativos.
Existem diferentes categorias de páginas da web (imagem: Webfactory Ltd/Unsplash)
O que é preciso para desenvolver uma página web?
O desenvolvimento de uma página web se baseia em três linguagens essenciais: o HTML define a estrutura e o conteúdo textual/multimídia, o CSS é responsável pela apresentação visual (estilos, cores e layout), e o JavaScript adiciona interatividade e dinamismo, criando a experiência do usuário.
O design responsivo é outro elemento importante, garantindo que o site se adapte e mantenha boa usabilidade em computadores, smartphones e tablets. Isso oferece uma navegação web intuitiva e fluida para os usuários.
Para a página estar acessível na internet é necessário ter um domínio (o endereço web único) e um serviço de hospedagem para armazenar todos os arquivos. Frequentemente, um sistema de gerenciamento de conteúdo (CMS) é usado para facilitar a atualização e manutenção do conteúdo.
As linguagens HTML e CSS são essenciais para a construção de uma página de internet (imagem: Branko Stancevic/Unsplash)
Qual é a diferença entre uma página web e um site?
Página web é um documento único acessível via internet, exibido em um navegador como um arquivo digital. Representa uma entidade de informação isolada, identificada por um URL específico, que pode conter texto, imagens, vídeos e outros elementos.
Site é uma coleção interconectada de diversas páginas web, todas organizadas sob um único nome de domínio. Funciona como a estrutura completa que organiza e permite a navegação web entre múltiplos pontos de informação, oferecendo uma experiência unificada ao usuário.
Qual é a diferença entre uma página web e um endereço web?
Uma página web é um documento digital acessível na internet, que serve como o conteúdo principal que o usuário visualiza e interage em seu navegador. Ela é composta por diferentes tipos de informações, como texto, imagens, vídeos e links.
Um endereço web, ou URL, é a localização exata e única utilizada para identificar e recuperar uma determinada página ou outro recurso na web. Ele age como o caminho padronizado que o navegador usa para saber onde buscar o documento.
Busca do Mercado Livre não funciona (Ilustração: Vitor Pádua/Tecnoblog)Resumo
A AWS enfrenta problemas operacionais em um data center na Virgínia, nos EUA.
A pane afeta serviços como Mercado Livre, Alexa, Mercado Pago e Prime Video.
A falha no sistema da AWS causou instabilidade em múltiplos serviços, incluindo dificuldades de acesso e funcionalidades limitadas.
A Amazon identificou problemas no DNS do DynamoDB e está trabalhando para resolver a interrupção.
O site de compras Mercado Livre, a assistente virtual Alexa, o jogo online Roblox e diversos outros serviços online estão fora do ar desde a manhã de hoje (20) devido a uma pane na AWS, a divisão de computação em nuvem da Amazon. As reclamações sobre essas e outras plataformas dispararam a partir das 5h40.
De acordo com o monitoramento oficial da própria AWS, foi identificado um problema operacional num data center localizado na Virgínia (identificado como US-EAST-1), nos Estados Unidos. Por causa disso, “múltiplos serviços” da gigante de computação em nuvem passam por uma “interrupção”.
App do Mercado Livre exibe mensagem de erro (imagem: Tecnoblog)
Mercado Livre, Mercado Pago, Alexa e Duolingo
O Mercado Livre está entre os nomes nacionais mais afetados. Ao longo do dia, os consumidores encontram dificuldades para acessar a loja virtual e fazer buscas de produtos. Em vez disso, aparece o aviso de que “tivemos um problema” e que “estamos trabalhando para resolvê-lo”.
O conglomerado do Mercado Livre reconheceu, durante a tarde, que tanto a loja quanto o serviço de pagamentos Mercado Pago sofreram uma instabilidade “provocada por uma falha generalizada e ampla no sistema da AWS.” Ainda de acordo com a empresa, as equipes estão “trabalhando rapidamente para restabelecer o sistema”.
Já a Alexa ficou muda: durante muitas horas, o cliente até poderia desejar bom dia ou perguntar a previsão do tempo, mas a assistente virtual da Amazon não respondia. As luzes indicam que a requisição estava sendo processada, mas o dispositivo não falava nada. O Tecnoblog fez testes com uma Echo Pop.
Echo Pop é a caixinha de som com Alexa (foto: Laura Canal/Tecnoblog)
Os usuários do Duolingo conseguiram fazer as lições, com áudios e tudo mais. No entanto, a parte do aplicativo dedicada às ligas não exibia nenhum ranking.
Resposta da Amazon
A Amazon inicialmente detectou um problema no DNS de acesso à API do DynamoDB, um banco de dados ofertado aos clientes da AWS. “Nós estamos trabalhando em múltiplos caminhos paralelos para acelerar a recuperação.” No entanto, posteriormente percebeu que outras estruturas do negócio de nuvem estavam instáveis.
Numa atualização publicada às 6h27, a empresa disse o seguinte:
“Estamos observando sinais significativos de recuperação. A maioria das solicitações já deve estar sendo atendida. Continuamos trabalhando em um acúmulo de solicitações em fila. Continuaremos fornecendo informações adicionais.”
A pane na AWS também impacta o serviço de streaming Prime Video, a plataforma de produtividade Canva e o aplicativo de bem-estar Wellhub (antigo Gympass), segundo queixas no site especializado em serviços digitais DownDetector.
Saiba a importância do URL para o dia a dia na internet (imagem: Lupa Charleaux/Tecnoblog)
URL (Uniform Resource Locator) é o endereço web completo de um recurso na internet, como um site, imagem ou arquivo. Ele é a informação padronizada que os usuários digitam na barra de endereços do navegador para acessar um destino online.
Sua principal utilidade é permitir a localização e o acesso a qualquer conteúdo digital. Ao usar o URL de um site, a pessoa fornece ao navegador o caminho exato para encontrar o servidor e o arquivo que deseja visualizar.
O funcionamento do URL é baseado em uma estrutura com protocolo (HTTP/HTTPS), o nome de domínio e o caminho do recurso no servidor. O navegador usa esses dados para se comunicar com o servidor e carregar o conteúdo solicitado.
A seguir, entenda o conceito de URL, para que serve no dia a dia e alguns exemplos que encontramos na internet.
A URL é o endereço web exclusivo que localiza qualquer recurso na internet, como uma página, uma imagem ou um arquivo. Ele funciona como um endereço postal que, por meio de componentes como protocolo, domínio e caminho, guia o navegador para a localização precisa do recurso desejado.
O que significa URL?
URL é a sigla para Uniform Resource Locator (Localizador Uniforme de Recursos, em português). O nome se refere ao mecanismo de endereço específico que identifica a localização de um recurso na internet, funcionando como o “CEP digital” para os navegadores poderem acessá-lo.
A URL atua como um endereço exclusivo para que os navegadores encontrem conteúdos na internet (imagem: Cottonbro/Pexels)
Para que serve um URL?
O URL atua como o endereço exclusivo que identifica qualquer recurso na internet, incluindo páginas da web, imagens e arquivos. Sua função primária é servir como um mapa digital que permite aos navegadores saberem exatamente em que lugar ir para buscar e carregar o conteúdo solicitado pelo usuário.
Ele garante que, ao digitar o endereço ou clicar em um link, o sistema estabeleça a conexão precisa com o servidor de destino. Assim, a URL é fundamental para a navegação ao viabilizar o acesso direto e correto a qualquer informação disponível online.
Como um URL funciona?
Um URL funciona como o endereço exclusivo que reconhece um recurso na web, permitindo que um navegador de internet saiba exatamente onde encontrar o conteúdo que o usuário deseja. Ao ser digitado, o browser inicia o processo para estabelecer a comunicação usando protocolos como HTTP ou HTTPS.
O segundo passo é a consulta ao DNS (Domain Name System), onde o nome de domínio legível para humanos é traduzido para o endereço IP do servidor que hospeda o recurso. O DNS funciona como uma lista telefônica digital, sendo essencial para o navegador conseguir localizar o servidor correto na vasta rede.
Com o endereço IP, o navegador envia a solicitação de conteúdo ao servidor, que processa a requisição e devolve os dados (como código HTML e imagens). O navegador, por fim, recebe esses dados, os interpreta e os exibe como a página da web que os usuários veem.
O URL atua em conjunto com protocolos e o DNS para obter acesso aos conteúdos na internet (imagem: Lupa Charleaux/Tecnoblog)
Quais são os tipos de URL?
Existem diferentes tipos de URL usados para formar um endereço web. Os principais são:
URL absoluta: é o endereço completo do recurso, incluindo protocolo, domínio e caminho. Permite apontar para qualquer recurso na internet, seja ele interno ou um domínio externo. Exemplo: http://www.exemplo.com/page/sobre-nos;
URL relativa: é um endereço parcial, especificado em relação ao local da página atual. É essencialmente útil para criar links entre páginas e recursos dentro do mesmo site. Exemplo: exemplo.com/imagem/logo.png ou exemplo.com/produto/item.html;
URL estática: um endereço fixo, imutável e geralmente descritivo, sem parâmetros variáveis. É mais amigável para leitura humana e tem benefícios diretos na otimização para mecanismos de busca (SEO). Exemplo: exemplo.com/sobre-nos;
URL dinâmica: endereço gerado ou modificado com base na interação do usuário ou em parâmetros de um script. Frequentemente inclui um ponto de interrogação (?) seguido por uma query string com pares de chave=valor. Exemplo: exemplo.com/search?query=tecnoblog;
URL canônica: endereço indicado aos mecanismos de busca como a versão principal. Possibilita consolidar sinais de classificação e evitar problemas de conteúdo duplicado, melhorando o SEO;
URL vanity: um endereço curto, personalizado e fácil de memorizar ou digitar. É muito usado em campanhas de marketing e publicidade para facilitar a divulgação e lembrança. Exemplo: exemplo.com/promocao.
Quais são os exemplos de URL?
Esses são alguns exemplos de URL comuns:
URL de website básica (Raiz): são os endereços mais simples, tipicamente usados para acessar a página inicial de um site. Exemplo: https://tecnoblog.net;
URLs com caminhos (Paths): contêm uma estrutura hierárquica após o domínio, direcionando o usuário para páginas ou recursos específicos no site, como uma seção ou artigo. Exemplo: tecnoblog.net/achados/ ou tecnoblog.net/responde/o-que-e-url;
URL com subdomínios: utilizam uma parte adicional (subdomínio) antes do nome do domínio principal, geralmente para organizar seções distintas ou serviços do website. Exemplo: apps.apple.com para serviços de aplicativos ou blog.exemplo.com para o blog;
URL com parâmetros de consulta (Query): possuem um ponto de interrogação (?) seguido de pares de chave=valor que transmitem dados adicionais ao servidor, frequentemente usados para gerar conteúdo dinâmico como resultados de pesquisa ou filtros. Exemplo: tecnoblog.net/?s=iphone para resultados de busca;
URL com fragmentos (Âncoras): contêm um sinal de hashtag (#) seguido de um identificador que instrui o navegador a pular para uma seção específica já carregada na página. Exemplo: tecnoblog.net/responde/o-que-e-url#exemplos;
URL de ação: são endereços que levam o usuário para uma página que realiza uma ação específica, como o acesso a uma conta ou reprodução de mídia. Exemplo: instagram.com/login para a página de acesso, youtube.com/watch?v=… para um vídeo;
URL de protocolo especial: são usados para iniciar ações não relacionadas à navegação web, como abrir o software de e-mail do usuário (mailto) ou acessar um servidor de transferência de arquivos (ftp). Exemplo: maito:contato@tecnoblog.net para enviar um e-mail.
Como é formado uma URL e suas variações (imagem: Divulgração/Semrush)
Qual é a diferença entre URL e link?
URL é um endereço web exclusivo que identifica e localiza um recurso específico na internet, como uma página web, um arquivo ou uma imagem. Sua principal função é fornecer o caminho exato para um navegador poder acessar e exibir esse recurso.
Link é um elemento clicável, geralmente um texto em destaque ou uma imagem, presente em uma página web que encapsula um URL. Seu objetivo é oferecer uma interface amigável e fácil para o usuário, permitindo que ele inicie a navegação de um recurso para outro com um simples clique.
Qual é a diferença entre URL e o domínio de um site?
URL é o endereço web completo que funciona como o localizador exato de um recurso específico em um site na internet, como uma página ou imagem. Sua estrutura engloba o protocolo, o nome de domínio e o caminho exato do recurso, fornecendo as direções detalhadas para o navegador acessar o conteúdo.
O domínio de um site é a parte central e legível de um endereço web, que serve como o nome exclusivo e principal do site na internet. Ele atua como um atalho fácil de memorizar para um complexo endereço IP numérico, sendo a identidade básica que os usuários digitam para chegar ao site.
Qual é a diferença entre URL e URI?
URL (Localizador uniforme de recurso) é um tipo de URI que, além de identificar o recurso, especifica sua localização exata na rede e o método de acesso necessário, como um protocolo (HTTP, FTP). É o endereço completo que as pessoas usam rotineiramente para acessar páginas e recursos na internet.
URI (Identificador uniforme de recurso) é um termo genérico que representa uma sequência de caracteres (string) para identificar um recurso na web ou fora dele. Ele serve como um sistema de identificação único ou um nome para qualquer recurso, seja um documento, uma imagem ou um serviço, e engloba tantos localizadores (URLs) quanto os nomes persistentes (URNs).
Qual é a diferença entre URL e URN?
URL (Localizador uniforme de recurso) é um endereço que identifica um recurso e especifica o mecanismo para localizá-lo e acessá-lo na rede, como o protocolo HTTP. Ele é o que permite que navegadores e outras aplicações encontrem e recuperem informações específicas.
URN (Nome uniforme de recurso) é um identificador persistente e baseado em nome para um recurso, funcionando como um título único e permanente. Ele identifica o recurso de forma exclusiva e abstrata, sendo independente da sua localização atual ou de como ele pode ser acessado.
Alexis Ohanian deixou o conselho do Reddit em 2020 (imagem: reprodução/Jerod Harris/Getty Images)Resumo
Alexis Ohanian, cofundador do Reddit, afirmou que a internet está se tornando “robótica” pelo aumento de conteúdo de baixa qualidade gerado por bots e IA.
Pesquisas indicam que 50,04% do tráfego da internet é de robôs, sendo 4,8% bots maliciosos.
A União Europeia projeta que, até 2026, 90% do conteúdo online poderá ser gerado sinteticamente.
O cofundador do Reddit Alexis Ohanian afirmou que a internet está se tornando um ambiente “robótico”, dominado por conteúdo automatizado e de baixa qualidade criado por inteligência artificial. A declaração foi feita em um episódio do podcast Technology’s Daily Show.
Em um momento da conversa, Ohanian disse aos apresentadores do podcast que eles “provam que a maior parte da internet está morta” ao representarem um espaço de comunicação real.
Busca por conexões mais humanas
O empresário deixou o conselho do Reddit em 2020, e desde então a plataforma vem adotando medidas para limitar o uso de seus dados por empresas de IA. Segundo Ohanian, a internet precisa de “espectadores e conteúdo ao vivo”.
Ele acredita que a “próxima geração de mídias sociais será comprovadamente humana”, movida pelo desejo de interações mais autênticas.
Nos últimos anos, apps como Signal e Discord cresceram por favorecer conexões mais diretas e pessoais. Ohanian os chamou de “padrão ouro” para interação, mas disse que ainda não representam uma inovação real.
Ohanian também afirmou no podcast que a internet precisa de novas formas de “interação próxima”, que preservem a experiência humana — algo que nem mesmo os chats em grupo garantem, já que muitos recorrem à IA para gerar ou editar mensagens.
Metade do tráfego da web já é dominado por bots, diz estudo (ilustração: Vitor Pádua/Tecnoblog)
Domínio de bots e IA preocupa
A preocupação é compartilhada. Recentemente, o CEO da OpenAI, Sam Altman, mencionou que muitas contas do X/Twitter já são controladas por modelos de linguagem de larga escala (LLMs), IAs treinadas para entender, gerar e interagir como se fossem pessoas reais. Essa percepção reflete uma tendência que estudos e análises de mercado vêm acompanhando de perto.
Dados recentes apontam para um aumento significativo na presença de bots e conteúdo gerado por IA na internet. O relatório Advanced Persistent Bots Report, de 2025, analisou 207 bilhões de transações de web e APIs em 2024. Ele revela que 50,04% do tráfego da internet é composto por robôs.
Desse total, 4,8% consiste em tráfego de bots maliciosos, que buscam monetizar dados críticos na dark web ou simular comportamento humano para manipular engajamento e algoritmos.
Em setembro do ano passado, outro estudo divulgado pela AWS indicou que mais de 57% do conteúdo online era gerado por IA, levantando preocupações sobre a precisão das informações e o risco potencial de desinformação.
A Agência de Aplicação da Lei da União Europeia projeta que, até o final de 2026, 90% do conteúdo online poderá ser gerado sinteticamente.
Tela do iPhone 15 (imagem: Thássius Veloso/Tecnoblog)
O Mercado Livre está com diversos cupons em eletrônicos: consoles, tablets, celulares e notebooks. Os descontos vão de R$ 100 a R$ 400 em compras a partir de apenas R$ 500, e são válidos até 31 de outubro ou até acabarem as unidades. E o Achados montou uma seleção com os principais cupons para você aproveitar.
*Cupons válidos até a data do vencimento, ou até acabarem as unidades.
Como aproveitar os cupons do Mercado Livre?
No caso do cupom APROVEITA, é necessário chegar até a página de pagamento, digitar o código do cupom e clicar em “Adicionar cupom”, como mostra a imagem à esquerda abaixo. Já para os demais cupons, basta selecionar a opção de aplicá-los já na página dos produtos, como mostra a imagem à direita abaixo.
Como aplicar os cupons no Mercado Livre (imagem: Laura Canal/Tecnoblog)
E para saber quando estas e outras ofertas estiverem acontecendo, vale a pena acompanhar os canais do Achados do Tecnoblog. Você nos encontra tanto no WhatsApp quanto no Telegram.
Principais ofertas com cupom no Mercado Livre
iPhone 15 tem 6,1 polegadas e processador A16 Bionic (Imagem: Thássius Veloso / Tecnoblog)
O iPhone 15 se destaca pela presença do chip Apple A16 Bionic que, apesar de não ser o mais recente, ainda deve entregar excelente desempenho para o celular. Além disso, ele também é equipado com uma câmera dupla com sensor principal de 48 megapixels, que marca um revolução em relação ao iPhone 14 e anteriores.
Galaxy Tab S10 Lite 5G (128 GB) por R$ 2.339 no Pix com o cupom de R$ 100 OFF
O Galaxy Tab S10 Lite é um tablet da Samsung com tela grande de 10,9 polegadas compatível com caneta S Pen, que já vem inclusa no pacote e é útil para desenhos e estudos. Também se destaca o desempenho, graças ao processador Exynos 1380 e a RAM de 6 GB. Assim como a conectividade 5G, que torna seu uso ainda mais prático.
PlayStation 5 Slim Disk por R$ 3.561 no Pix com o cupom de R$ 150 OFF [esgotado]
O PlayStation 5 Slim Disk se destaca por tanto ser um PS5 slim mais leve do console, quanto por contar com o leitor de mídia física (diferentemente da Edição Digital). Ademais, o PS5 Slim Disk tem SSD de 1 TB, que proporciona armazenamento e velocidade, e acompanha controle DualSense com imersivo segundo os testes no Tecnoblog.
Nintendo Switch OLED por R$ 2.035 no Pix com o cupom de R$ 100 OFF [esgotado]
O Nintendo Switch OLED é uma outra opção de console em promoção, que se destaca por oferecer, além do modo TV, os modos de jogo portátil sozinho e acompanhado da Nintendo. Neles, ainda chama a atenção o display OLED, que oferece imagem de alta qualidade com resolução 1.920 x 1.080 pixels para a jogatina.
O Notebook Lenovo LOQ-e é equipado com RAM de 16 GB e armazenamento SSD de 512 GB. Com isso, é capaz de rodar jogos e funcionalidades mais pesadas com maior tranquilidade. O notebook ainda traz GPU Nvidia GeForce RTX 3050 e tela com taxa de atualização de 144 Hz, otimizando a experiência em jogatinas.
O Galaxy Book 4 tem RAM de 8 GB e armazenamento SSD de 256 GB, ideais para um uso básico. Um dos destaques é a portabilidade, já que o notebook da Samsung pesa apenas 1,55 Kg, podendo ser transportado com maior facilidade para a faculdade ou o trabalho. O sistema operacional é o Windows 11.
Linha Samsung Galaxy Book 4 terá foco em IA (Imagem: Divulgação/Samsung)
O Notebook VAIO FE é equipado com armazenamento de 256 GB e RAM de 8 GB, sendo capaz de rodar de navegadores até jogos menos pesados, com possibilidade de upgrade posterior. O notebook ainda conta com tela de 16 polegadas antirreflexo, oferecendo bom espaço de visualização para trabalho e estudos.
Aviso de ética: ao clicar em um link de afiliado, o preço não muda para você e recebemos uma comissão.
Mercado Livre traz cupons de até R$ 400 de desconto em compras a partir de R$ 500; ofertas são válidas até o fim de outubro e incluem iPhones, tablets da Samsung e consoles
Tela do iPhone 15 (imagem: Thássius Veloso/Tecnoblog)
Como aplicar os cupons no Mercado Livre (imagem: Laura Canal/Tecnoblog)
iPhone 15 tem 6,1 polegadas e processador A16 Bionic (Imagem: Thássius Veloso / Tecnoblog)
Google testa novo modelo de exibição de anúncios (ilustração: Vitor Pádua/Tecnoblog)Resumo
Google criou a seção “Resultados patrocinados” para agrupar anúncios no topo das páginas de busca.
A área pode ser ocultada ao rolar a tela e exibirá no máximo quatro links pagos, posicionados acima ou abaixo dos resumos de IA.
A atualização já começou a ser implementada globalmente para dispositivos móveis e desktop.
O Google atualizou a exibição de anúncios nos resultados de busca. Os links patrocinados agora serão exibidos em um bloco separado chamado “Resultados patrocinados”, posicionado no topo da página. Segundo a empresa, o objetivo é facilitar a navegação e tornar mais clara a distinção entre resultados pagos e orgânicos.
A nova seção manterá o mesmo tamanho dos anúncios atuais e não exibirá mais de quatro links simultâneos. Ao rolar a tela, os usuários poderão ocultar a área de anúncios com um botão dedicado.
A empresa também confirmou que, em algumas situações, o bloco de anúncios poderá aparecer acima ou abaixo dos resumos gerados por inteligência artificial (AI Overviews), recurso que vem sendo expandido desde o início de 2024.
O que muda?
Resultados patrocinados poderão ser ocultados após a rolagem (imagem: reprodução/Google)
De acordo com o Google, o novo layout de anúncios “ajuda as pessoas a navegar pelo topo da página com mais facilidade”. A reformulação faz parte de uma série de ajustes na interface de busca, motivada pelo novo comportamento dos usuários, que passaram a rolar rapidamente os resultados para evitar seções de IA ou anúncios.
A ideia da companhia é organizar os links pagos em um espaço mais discreto, porém visualmente claro, evitando confusão entre publicidade e resultados orgânicos. Mesmo assim, a mudança mantém a presença de anúncios tanto no início quanto no final da página de resultados. O bloco de resultados patrocinados só poderá ser ocultado após a visualização completa.
A posição dos anúncios em relação aos resultados orgânicos e aos resumos de IA deve influenciar o número de cliques e o tempo de visualização. O Google já começou a implementar a mudança globalmente em desktops e dispositivos móveis, segundo o comunicado oficial.
Amazon Brasil anunciou solução que emula um supermercado físico (ilustração: Vitor Pádua/Tecnoblog)Resumo
Amazon Brasil lançou a seção Amazon Mercado, que organiza produtos essenciais por categoria, simulando um supermercado.
A plataforma usa recomendações personalizadas e oferece programas de desconto como “Mais por Menos” e “Programe & Poupe”.
Membros do programa Prime têm frete grátis em todas as compras na nova seção.
A Amazon Brasil anunciou o lançamento da nova seção Amazon Mercado dentro do site e aplicativo, dedicada à compra de itens essenciais. A solução, desenvolvida no Brasil, busca simular a experiência de um supermercado físico, agrupando produtos por categoria.
O objetivo da nova aba é simplificar a aquisição de produtos de uso diário. A plataforma também utiliza recomendações personalizadas para destacar os produtos que o cliente compra com frequência, agilizando o processo de reabastecimento do carrinho.
Como funciona o Amazon Mercado?
Amazon Mercado organiza produtos por categoria (imagem: reprodução)
Ao acessar a nova aba, o consumidor encontra uma vitrine organizada por categorias, que funcionam como os setores de um mercado. A interface reúne os produtos em seções para que o cliente não precise buscar cada item individualmente. As principais são:
Papelaria e Escritório: opções de material escolar e de escritório, como Planner Executivo Capa Dura em Couro Sintético, por R$ 59,89, além de papel sulfite, cadernos, agendas e packs de canetas.
Alimentos e Bebidas: aqui é possível encontrar itens de mercearia, como Café 3 Corações 500 g, Torrado e Moído Tradicional, por R$ 39,49, entre várias opções de grãos, massas, lanches, molhos, cereais, bebidas, enlatados e mais.
Cuidados Pessoais: itens como o sabonete líquido Nívea Óleo de Banho, por R$ 29,59. Também se encontram absorventes, cremes dentais, repelentes, desodorantes e outros.
Beleza: reúne maquiagens, produtos para cabelo, unhas e pele, como o protetor solar facial Principia FPS 60, por R$ 39,59.
Limpeza da Casa: agrupa itens como o limpador cremoso Cif, por R$ 18,59 e produtos para lavanderia.
Cuidados com o Bebê: brinquedos, itens de higiene, alimentação de bebês e até mesmo produtos maiores, como a cadeira de refeição portátil Cosco Kids, por R$ 160,46.
Pets: seção dedicada a rações, como o pack Whiskas sachê para gatos adultos, por R$ 56, e acessórios para animais.
Suplementos e Vitaminas: categoria com produtos para saúde e bem-estar, como Whey Protein da Adaptogen por R$ 148,50 e barras nutricionais e creatina.
A ideia, segundo a empresa, é que o Amazon Mercado resolva o desafio de ter que pesquisar e adicionar vários itens de baixo valor um a um, processo que tornava a montagem de um carrinho de compras de supermercado demorada.
Dentro de cada um desses corredores principais, os produtos são organizados em subcategorias para detalhar a navegação. Na seção de “Alimentos e Bebidas”, por exemplo, o usuário encontra divisões como “Lanches e Doces”, “Molhos e Condimentos” e “Grãos e Massas”, facilitando a busca por itens específicos.
Programas e descontos
A Amazon também integrou ao Mercado os programas de economia da plataforma, como o “Mais por Menos”, que concede 10% de desconto em compras de 10 ou mais unidades de produtos selecionados, e o “Programe & Poupe”, que oferece de 5% a 10% de desconto em compras com entrega recorrente.
“Nossa missão é reinventar continuamente a experiência de compra de itens essenciais para os brasileiros”, afirma Maria Eduarda Cyreno, diretora de Varejo da Amazon Brasil. “O Amazon Mercado transporta a familiaridade e intuitividade das lojas físicas para o ambiente digital”, completa.
Para membros do programa Prime, a empresa oferece frete grátis em todas as compras na nova seção, sem valor mínimo de pedido.
Aviso de ética: ao clicar em um link de afiliado, o preço não muda para você e recebemos uma comissão.
Saiba como ampliar o armazenamento do iPhone usando o iCloud (imagem: Lupa Charleaux/Tecnoblog)
O jeito mais simples de aumentar a memória do iPhone é assinando um dos planos do iCloud. Este serviço de nuvem da Apple permite guardar fotos, vídeos e outros dados para liberar espaço físico no aparelho.
O plano básico do iCloud oferece 5 GB gratuitos, mas é possível optar por planos pagos. As opções de upgrade incluem 50 GB, 200 GB, 2 TB, 6 TB e 12 TB de armazenamento, adaptando-se a qualquer necessidade.
Veja o passo a passo para comprar armazenamento no iPhone realizando a assinatura do iCloud pelo celular, Mac ou Windows.
Acesse o aplicativo “Ajustes” no iPhone para ver mais opções de configurações do dispositivo.
Acessando o app “Ajustes no iPhone (imagem: Lupa Charleaux/Tecnoblog)
2. Acesse as informações da Conta Apple
Toque no seu nome de usuário, na parte superior do app, para acessar mais informações da Conta Apple ID.
Abrindo as opções do usuário do iPhone (imagem: Lupa Charleaux/Tecnoblog)
3. Vá até a opção “iCloud”
Toque em “iCloud” para verificar as informações do serviço de armazenamento na nuvem.
Selecionando o menu “iCloud” (imagem: Lupa Charleaux/Tecnoblog)
4. Selecione “Fazer o upgrade para o iCloud+” ou “Ver todos os planos”
Toque em “Atualizar para o iCloud+”, caso não seja assinante, ou “Ver todos os planos” para ver as opções de upgrades para comprar espaço no iPhone por meio do iCloud.
Escolhendo a opção “Fazer o upgrade para o iCloud+” ou “Ver todos os planos” (imagem: Lupa Charleaux/Tecnoblog)
5. Escolha um plano do iCloud
Confira as opções de upgrade de armazenamento do iCloud e selecione o plano que melhor combine com as suas necessidades. Em seguida, toque em “Fazer upgrade” para avançar.
Escolhendo o novo plano do iCloud+ (imagem: Lupa Charleaux/Tecnoblog)
6. Confirme a compra no novo plano
Por fim, confirme pressionando duas vezes o botão lateral direito do iPhone para assinar o iCloud+. Assim, você terá mais espaço de armazenamento no iPhone e em outros dispositivos da Apple.
Confirmando a assinatura do iCloud+ (imagem: Lupa Charleaux/Tecnoblog)
Comprar armazenamento do iCloud pelo Mac
1. Abra os “Ajustes do Sistema” do Mac
Clique no menu Apple, ícone de maçã no canto superior esquerdo da tela do sistema operacional Mac, e selecione a opção “Ajustes do Sistema”.
Acessando a opção “Ajustes do sistema” no computador Mac (imagem: Lupa Charleaux/Tecnoblog)
2. Acesse as informações da Conta Apple
Clique em cima do seu nome de usuário, no canto esquerdo da tela, para abrir as opções da Conta Apple.
Abrindo as opções de usuário (imagem: Lupa Charleaux/Tecnoblog)
3. Selecione o menu “iCloud”
Selecione a opção “iCloud” para ver mais informações do serviço de armazenamento em nuvem da Apple.
Selecionando o menu “iCloud” (imagem: Lupa Charleaux/Tecnoblog)
4. Clique em “Gerenciar” iCloud
Na seção “iCloud”, clique na opção “Gerenciar” no canto direito da tela, para abrir um novo menu de opções.
Clicando em “Gerenciar” iCloud (imagem: Lupa Charleaux/Tecnoblog)
5. Acesse a opção “Adicionar armazenamento”
Clique em “Adicionar armazenamento”, no canto superior direito da nova janela, para avançar.
Abrindo a opção “Adicionar armazenamento” do iCloud (imagem: Lupa Charleaux/Tecnoblog)
6. Escolha o plano do iCloud+
Selecione a opção de upgrade do iCloud+ que melhor atende às suas necessidades e, depois, clique no botão “Próximo” no canto inferior direito.
Escolhendo o plano de upgrade do iCloud+ (imagem: Lupa Charleaux/Tecnoblog)
7. Conclua a compra do armazenamento
Insira sua senha da Conta Apple e clique no botão “Comprar” para assinar o plano do iCloud+.
Importante: embora o procedimento seja feito pelo Mac, ele também serve para aumentar o armazenamento do iPhone e outros dispositivos Apple vinculados a sua conta.
Confirmando o pagamento do armazenamento do iCloud (imagem: Lupa Charleaux/Tecnoblog)
Comprar armazenamento do iCloud pelo Windows
1. Clique em “Gerenciar” iCloud
Abra o aplicativo do iCloud no Windows e desça a tela até ver a seção “iCloud”. Em seguida, clique no botão “Gerenciar” para avançar.
Acessando a opção “Gerenciar” iCloud no app do Windows (imagem: Lupa Charleaux/Tecnoblog)
2. Selecione “Adicionar armazenamento”
Clique na opção “Adicionar armazenamento”, no canto superior direito da nova janela, para ver as opções de planos de armazenamento do iCloud+.
Clicando em “Adicionar armazenamento” do iCloud (imagem: Lupa Charleaux/Tecnoblog)
3. Escolha o plano do iCloud+
Escolha a opção de upgrade do iCloud+ e, depois, clique em “Próximo” para continuar.
Escolhendo o plano de upgrade do iCloud+ (imagem: Lupa Charleaux/Tecnoblog)
4. Confirme o upgrade de armazenamento do iCloud+
Digite a sua senha da Conta Apple e, em seguida, clique em “Comprar” para realizar a assinatura do armazenamento do iCloud+.
Importante: mesmo com a assinatura sendo feita por meio de um PC Windows, o upgrade para o espaço de armazenamento na nuvem é válido para o iPhone e outros dispositivos vinculados à sua Conta Apple.
Confirmando a compra de espaço de armazenamento no iCloud (imagem: Lupa Charleaux/Tecnoblog)
Por que não consigo comprar espaço de armazenamento no iPhone?
Há alguns cenários que impedem você de comprar espaço de armazenamento no iPhone via iCloud+. Os mais comuns são:
Problemas com método de pagamento: ocorrem devido ao saldo insuficiente, dados incorretos do cartão de crédito ou endereço de cobrança não coincidir com o registro do banco. Verifique e atualize as informações de pagamento para solucionar;
Conexão com a internet: uma conexão fraca ou instável impede a comunicação do dispositivo com os servidores da Apple para concluir a assinatura. Tente se conectar a uma rede Wi-Fi estável ou usar os dados móveis em um ambiente com sinal forte;
Falhas temporárias no sistema: um erro temporário no dispositivo ou no sistema pode estar interferindo no processo de upgrade. Muitas vezes isso pode ser resolvido ao reiniciar o dispositivo ou ao entrar e sair da conta Apple;
Interrupções nos sistemas da Apple: os servidores ou sistemas da Apple podem estar com problemas ou passando por manutenção, resultando em falhas nas transações. Confira o status dos sistemas e tente realizar o procedimento mais tarde;
Restrições de dispositivos ou conta: o dispositivo pode ter restrições de rede ativas ou a Conta Apple ID pode estar suspensa por motivos de segurança, bloqueando a compra. Entre em contato com o suporte da Apple para verificar as restrições.
Precisa ter cartão de crédito para comprar espaço de armazenamento no iPhone?
Não, a Apple oferece outros métodos de pagamentos além do cartão de crédito para assinar o iCloud+ e expandir o armazenamento do iPhone. Por exemplo, é possível pagar a assinatura do iCloud+ usando o saldo de cartões-presente (Gift cards) resgatados pela Conta ID Apple.
Posso comprar espaço de armazenamento no iPhone com Pix?
Não é possível comprar diretamente espaço no iCloud+ usando Pix como forma de pagamento. Contudo, dá para adquirir cartões-presente da Apple em lojas ou plataformas que aceitam o Pix e, depois, resgatar o valor como crédito em sua Apple ID para realizar a compra do upgrade de armazenamento no iPhone.
É possível comprar armazenamento em nuvem no iPhone sem ser pelo iCloud?
Sim, você pode comprar e usar armazenamento em nuvem de terceiros no iPhone, como o Google Drive ou o Dropbox, para salvar fotos, vídeos e outros arquivos. Contudo, esses serviços não oferecem o backup completo do sistema, como configurações e dados de aplicativos, sendo uma função exclusiva do iCloud.
Dá para usar cartão de memória no iPhone?
Não, o iPhone não possui entrada para cartões microSD ou qualquer forma de expansão de armazenamento físico. Para gerenciar o espaço quando estiver cheio, a melhor alternativa é apagar arquivos desnecessários e liberar espaço no iCloud.
Qual é a diferença entre comprar armazenamento e liberar espaço no iPhone?
Comprar armazenamento se refere a ter uma assinatura do iCloud+ para expandir o armazenamento em nuvem para fotos, vídeos, arquivos e backups. Ele mantém os dados sincronizados em todos os dispositivos Apple vinculados a conta e garante um backup seguro fora do aparelho físico.
Liberar espaço no iPhone é o ato de apagar dados, fotos, vídeos ou aplicativos desnecessários diretamente na memória interna do aparelho. O objetivo é recuperar o espaço físico local para permitir a instalação de novos aplicativos, atualizações de software ou o registro de mais fotos e vídeos.
Saiba como funciona o modo de transmissão de dados de ponto a ponto (Imagem: Vitor Pádua/Tecnoblog)
Unicast é um modo de transmissão de dados em redes, caracterizado por uma comunicação de ponto a ponto (um-para-um). Nele, um único remetente envia dados diretamente para um único destinatário, sendo o método mais comum para a maioria das atividades na internet.
Seu funcionamento se baseia no envio de pacotes de dados para o endereço IP específico do destinatário. Protocolos como TCP/IP estabelecem uma conexão dedicada entre os dois dispositivos, garantindo a entrega segura e confiável da informação.
Alguns exemplos comuns de uso de unicast incluem a navegação na web (acessar um site), envio de e-mails e serviços de streaming de vídeo sob demanda. Também é essencial em chamadas de vídeo e na transferência de arquivos específica entre dois pontos.
A seguir, entenda o conceito de unicast, para que ele serve, suas vantagens e desvantagens. Também conheça as aplicações que usam esse modo de transmissão de dados.
Unicast é um método de comunicação em redes, estabelecendo uma conexão ponto a ponto na qual um único remetente transmite dados diretamente para um único destinatário específico. Esse modelo um-para-um é a base da maioria das interações na internet, essencial para navegação na web, envio de e-mails e transferência de arquivos.
O que significa unicast?
O termo “unicast” surge da união das palavras “uni” (único) e “cast” (transmissão, em inglês). Nos dicionários de língua inglesa, a palavra é definida como a “transmissão de um pacote de dados ou um sinal audiovisual para um único destinatário”.
O unicast serve de base para a maioria das atividades na internet (imagem: Divulgação/Microsoft)
Para que serve o unicast?
O unicast permite a comunicação ponto a ponto (um-para-um), onde um único remetente envia dados diretamente para um destinatário único e específico. Isso é feito usando endereços de rede exclusivos (endereço IP), garantindo que apenas o destinatário pretendido receba a informação.
Este modelo de comunicação é ideal para a entrega de dados personalizados e direcionados. Ele serve como base de serviços comuns como navegação na web, e-mail, transferência de arquivos e streaming sob demanda.
Quais são exemplos de uso do unicast?
Estes são alguns exemplos do uso do unicast:
Navegação na web: ao acessar um site, os navegadores fazem uma solicitação usando o protocolo HTTP ou HTTPS a um servidor, que responde enviando o conteúdo, como páginas HTML e imagens, diretamente para o usuário solicitante;
E-mail: a comunicação para envio e recebimento de mensagens entre um cliente de e-mail e um servidor de e-mail é estabelecida como uma conexão ponto a ponto dedicada;
Streaming de vídeo sob demanda: plataformas como Netflix e Disney+ usam o unicat para entregar o streaming de dados de forma exclusiva, garantindo uma experiência personalizada para cada usuário;
Jogos online: o dispositivo de cada jogador mantém uma conexão única com o servidor do jogo, enviando e recebendo informações de status, posição e ações constantemente de forma individualizada;
Transferências de arquivos (FTP): protocolos como FTP (File Transfer Protocol) e SFTP (Secure File Transfer Protocol) empregam o unicast para enviar arquivos grandes diretamente de um servidor para um cliente ou vice-versa, garantindo a entrega precisa;
Videoconferências privadas: cria conexões seguras e individuais para reuniões virtuais entre dois participantes, assegurando que os dados de vídeo e áudio sejam entregues somente aos convidados da sessão;
Redes privadas virtuais (VPNs): estabelecem túneis de comunicação seguros e criptografados baseados em unicast, protegendo o tráfego de dados e informações confidenciais entre o dispositivo do usuário e um servidor remoto.
Serviços de streaming utilizam o modo de comunização unicast (imagem: Vitor Pádua/Tecnoblog)
Como funciona o unicast
O unicast funciona com um único remetente enviando pacotes de dados para um único receptor específico, garantindo exclusividade na entrega. A operação um-para-um se baseia em protocolos como IP (Internet Protocol) e Ethernet, que usam endereços únicos de rede (IP e Mac) para identificar precisamente o destino e a origem.
Na prática, o dispositivo remetente encapsula os dados e insere o endereço IP do destinatário no cabeçalho de cada pacote, que é então enviado pela rede. Protocolos de roteamento guiam o pacote por meio de routers até o destino, e o protocolo de camada de enlace usa o endereço MAC do destinatário para a entrega exata.
O TCP (Transmission Control Protocol) e o UDP (User Datagram Protocol) são os principais protocolos que usam o unicast. O TCP garante uma entrega confiável, ordenada e com confirmação para o receptor, enquanto o UDP oferece uma entrega mais rápida e sem garantia de recebimento.
Este mecanismo fundamental e direto sustenta a maioria do tráfego da internet e de redes locais, sendo a forma padrão que se exige em uma conexão única e dedicada. Ele assegura que a informação chegue apenas ao dispositivo pretendido, permitindo a transferência segura e privada de dados.
Os procolos TCP/IP são essenciais para o funcionamento do unicast (imagem: Vitor Pádua/Tecnoblog)
Quais são as vantagens do unicast?
Estes são os pontos fortes do unicast:
Comunicação personalizada: permite o envio de um fluxo de dados exclusivo para um destinatário específico, proporcionando uma experiência de alta qualidade e individualizada;
Uso eficiente da largura de banda: transmite dados diretamente ao destinatário sem desperdícios, evitando o consumo desnecessário de recursos de rede que ocorre em métodos como o broadcast;
Entrega confiável: a natureza ponto a ponto garante uma entrega precisa e facilita a utilização de mecanismos de confirmação, tornando-o ideal para comunicações críticas;
Comunicação segura: oferece segurança elevada, pois as informações são acessíveis somente pelo destinatário e podem ser facilmente protegidas com criptografia e autenticação;
Adequação para aplicações interativas: é essencial para serviços que exigem respostas em tempo real, como videoconferências e jogos online, garantindo uma conexão dedicada e estável.
Quais são as desvantagens do unicast?
Estes são os pontos fracos do unicast:
Ineficiência em escala (grandes redes): exige que o remetente envie uma cópia separada dos dados para cada destinatário, o que se torna altamente ineficiente em grandes redes com diversos dispositivos que precisam da mesma informação;
Alto consumo de recursos: resulta em maior uso da largura de banda e aumento do custo de processamento no dispositivo remetente, que precisa estabelecer e gerenciar uma conexão e transmissão individual para cada destino;
Vulnerabilidade e falta de redundância nativa: não oferece mecanismos de redundância ou tolerância a falhas nativamente. Se o único servidor unicast falhar ou precisar de manutenção, o serviço e os dados se tornam imediatamente indisponíveis;
Alvo único para ataques DDoS: um servidor unicast é alvo singular por ser um ponto central de comunicação de um-para-um, podendo ser facilmente sobrecarregado e derrubado por um ataque de negação de serviço distribuído (DDoS);
Degradação do desempenho com a distância: a performance da entrega dos dados é sensível à localização do destinatário. Usuários geograficamente mais distantes do servidor podem experimentar latência devido às maiores distâncias de rede a serem percorridas.
Multicast: envia um único fluxo de dados de uma fonte para um grupo específico de destinatários de forma simultânea. É ideal para serviços de streaming ao vivo, jogos online, IPTV e videoconferências em grupo, otimizando o uso da largura de banda;
Broadcast: transmite dados de uma única fonte para todos os dispositivos conectados em uma determinada rede ou domínio de broadcast. É usado em protocolos de rede para descoberta de serviços ou em transmissões de rádio e TV aberta;
Anycast: permite que o mesmo endereço de IP seja compartilhado por múltiplos servidores distribuídos geograficamente. O tráfego é roteado para um servidor mais próximo, otimizando a velocidade e oferecendo alta disponibilidade;
Geocast: envia informações apenas para um grupo de destinatários localizados em uma área geográfica específica. É usado em aplicações baseadas em localizações, como sistemas de alerta de trânsito ou notificações de emergência regionais.
Diferença do direcionamento do fluxo de dados no unicast, multicast e broadcast (imagem: Vitor Pádua/Tecnoblog)
Qual é a diferença entre unicast e broadcast?
Unicast é um modo de transmissão de rede um-para-um, onde os dados são enviados de uma única origem para um único destino específico. O remetente usa o endereço exclusivo do receptor para garantir uma entrega direta, tornando-o eficiente, seguro e ideal para comunicações individuais como navegação web ou envio de e-mail.
Broadcast é um meio de transmissão um-para-todos, enviando dados de uma única origem para todos os dispositivos conectados na mesma rede simultaneamente. Ele usa um endereço especial que garante que todos os destinatários recebam o pacote de dados, o que é ineficiente e menos seguro, mas é comum em radiodifusão.
Qual é a diferença entre unicast e multicast?
Unicast é um formato de transmissão um-para-um, no qual os pacotes de dados são enviados de uma única fonte para um único destino específico na rede. Esta comunicação direta e privada é o formato mais comum, usado em atividades como navegação na web e troca de e-mails.
Multicast é um método de transmissão um-para-muitos, onde um único fluxo de dados é enviado para um endereço de grupo, alcançando os dispositivos que optaram por recebê-lo. A rede replica o fluxo de dados de forma eficiente apenas nos pontos onde o caminho de destino se divide, sendo ideal para streaming ao vivo, IPTV e videoconferências.
Saiba como funciona o modo de transmissão “um-para-muitos” e em quais aplicações ele é empregado (imagem: TheDigitalArtist/Pixabay)
Multicast é um modo de transmissão em rede que permite que uma única fonte (remetente) envie pacotes de dados para múltiplos destinatários específicos ao mesmo tempo. Diferente do unicast (um-para-um) e do broadcast (um-para-todos), ele opera no modelo um-para-muitos.
Seu funcionamento se baseia no envio de um pacote a um endereço IP de um grupo específico. Então, roteadores e switches replicam e encaminham esses dados somente para os dispositivos que se declaram membros desse grupo, otimizando o uso da largura de banda.
Um exemplo de uso do multicast é o serviço de IPTV, onde canais são distribuídos eficientemente para muitos assinantes simultaneamente. Outras aplicações importantes incluem streaming de vídeo e áudio, teleconferência e distribuição de dados em tempo real.
A seguir, entenda o conceito de multicast, para que ele serve, seu funcionamento, suas vantagens e desvantagens.
Multicast é um método de comunicação de um-para-muitos onde uma única cópia de um fluxo de dados é enviada de um remetente para múltiplos destinatários simultaneamente. Esse modelo roteia os dados apenas para um grupo específico de dispositivos, minimizando o tráfego e otimizando o uso da largura de banda da rede.
O que significa multicast?
O termo inglês “multicast” significa o “ato de enviar dados por meio de uma rede de computadores para vários usuários ao mesmo tempo”, conforme o Oxford Dictionary. Ele surge da união das palavras “multi” (mais de um, em inglês) e “cast” (transmissão).
TV Box para IPTV adotam o métro de comunicação multicast (imagem: Vitor Pádua / Tecnoblog)
Para que serve o multicast?
O multicast serve para realizar a transmissão de dados de um-para-muitos de forma eficiente, principalmente em rede IP. Ele permite que um único remetente envie um fluxo de dados para múltiplos destinatários específicos simultaneamente, em vez de enviar cópias individuais.
Isso conserva a largura de banda e minimiza o congestionamento da rede, pois o tráfego é replicado apenas onde necessário. Ele é indicado para aplicações em tempo real, como streaming de vídeo ao vivo, IPTV e videoconferências.
Quais são as vantagens do multicast?
Estes são os pontos fortes do multicast:
Uso eficiente da largura de banda: um único fluxo de dados é enviado para vários destinatários, reduzindo drasticamente o tráfego de rede em comparação com o envio de fluxos individuais para cada usuário (unicast);
Escalabilidade: é facilmente escalável para acomodar inúmeros assinantes, pois a largura de banda usada se mantém consistente, independentemente do aumento no tamanho do público;
Redução da carga do servidor de origem: os recursos do servidor e da rede de origem são utilizados de forma mínima, já que é preciso gerar e gerenciar um único fluxo de dados em vez de múltiplos fluxos separados;
Otimização para comunicação em grupo: é ideal para aplicações que exigem a distribuição de informações para múltiplos usuários ao mesmo tempo, como IPTV, videoconferências e streaming de vídeo de alta definição.
Quais são as desvantagens do multicast?
Estes são os pontos fracos do multicast:
Configuração e gerenciamento complexos: implementar e gerenciar o multicast requer uma configuração de rede intrincada, incluindo o uso e manutenção de protocolos de roteamento especializados;
Suporte limitado e fragmentado: não é um recurso universalmente suportado, visto que a internet pública geralmente não oferece suporte a multicast. Sua disponibilidade e implementação também pode variar entre diferentes provedores, redes e dispositivos;
Falta de confiabilidade nativa: não inclui, por padrão, mecanismos de transporte confiáveis, como confirmação de recebimento. Isso significa que pacotes perdidos não são retransmitidos automaticamente;
Dependência de infraestrutura de rede controlada: é mais adequado e eficiente em redes privadas ou gerenciadas, tornando-o uma opção menos viável ou inadequada para proprietários de conteúdo que não controlam a infraestrutura de rede por onde o tráfego passará.
Serviços de streaming de víde e áudio se beneficiam do modelo de comunicação multicast (imagem: Vitor Pádua/Tecnoblog)
Como funciona o multicast
O multicast é um método de comunicação de um-para-muitos que utiliza endereços IP, como a internet. Essa técnica é chamada de multicast IP, utilizando faixas de endereços especiais para o envio do fluxo de dados para um grupo específico de múltiplos destinatários.
Para o multicast IP funcionar, os destinatários devem usar protocolos como IGMP (IPv4) ou MLD (IPv6) para se juntar ao grupo, identificado por um único endereço IP. Roteadores e switches usam esses protocolos para construir um “caminho de distribuição”, replicando e encaminhando pacotes de forma inteligente.
Assim, os pacotes são enviados uma única vez pelo remetente e são replicados apenas nos pontos da rede onde há a necessidade de entrega a um membro do grupo. Isso contrasta com o unicast (um-para-um) e o broadcast (um-para-todos), sendo ideal para streaming de vídeo e teleconferências.
Embora o princípio seja semelhante, o conceito de multicast pode ser implementado em outros sistemas de comunicação, como a TV por assinatura via satélite ou cabo. Nesses casos, o sinal é transmitido em uma frequência específica que é distribuída, e os decodificadores sintonizam essa frequência para acessar o conteúdo.
No multicast, o remetente envia um fluxo de dados e ele é direcionado para os dispositivos interessados em receber o conteúdo (imagem: Reprodução/NetworkLessons)
Quais são exemplos de uso do multicast?
Estes são alguns exemplos onde o multicast é usado:
IPTV e streaming de vídeo: transmissão de canais de TV, como em IPTV, ou eventos ao vivo para muitos assinantes de forma eficiente, enviando um único fluxo de dados;
Videoconferências e ensino a distância (EAD): envio de áudio e vídeo em tempo real para todos os participantes de uma reunião ou de uma aula virtual ao mesmo tempo;
Jogos online e realidade virtual (VR): distribuição de atualizações do estado do jogo e informações em tempo real para múltiplos jogadores simultaneamente, minimizando a latência;
Mercado financeiro e cotações: entrega de dados de mercado, como cotações de ações em tempo real, para inúmeros traders e sistemas de análise;
Distribuição de software e implantação de sistemas: envio de patches, atualizações ou imagens de sistemas operacionais para múltiplos dispositivos na rede local;
Sinalização digital: distribuição de gráficos, vídeos e informações atualizadas para painéis digitais e telas espalhados por lojas, aeroportos ou campi.
Existem alternativas ao multicast?
Sim, existem outros modos de transmissão de sinal que servem como alternativas ao multicast, cada um com seus próprios casos de uso. Os principais são:
Unicast: transmissão direta e privada de um remetente para um único destinatário, sendo o modo mais comum na internet. É usado para conexões ponto a ponto como acesso a um site ou chamada de vídeo individual;
Broadcast: transmite os dados de uma única fonte de origem para todos os dispositivos conectados em uma rede, ou de forma mais ampla, como na radiodifusão e televisão, onde o sinal é captado por receptores;
Anycast: permite que o mesmo endereço IP seja configurado em múltiplos servidores distribuídos geograficamente, roteando o tráfego automaticamente para o ponto mais próximo, otimizando a velocidade e oferecendo alta disponibilidade;
Geocast: envia informações exclusivamente para um grupo de destinatários localizados em uma área geográfica específica. É ideal para aplicações baseadas em localização, como sistemas de alerta de trânsito ou notificações de emergência regionais.
O broadcast é bastante usado para transmissões de rádio e TV (imagem: Vitor Pádua/tecnoblog)
Qual é a diferença entre multicast e broadcast?
Multicast é um método de comunicação onde os dados são enviados de uma única fonte para um grupo específico de destinatários que manifestam interesse. É uma comunicação um-para-muitos, ideal para streaming de vídeo e jogos online, pois otimiza a largura de banda ao direcionar o tráfego apenas para os dispositivos relevantes.
O broadcast é um formato onde os dados são enviados de uma única fonte para todos os dispositivos conectados à mesma rede, sem exceção. É um modelo um-para-todos, comumente usado em transmissões de rádio e TV, mas é menos eficiente por gerar tráfego desnecessário em dispositivos que não precisam das informações.
Qual é a diferença entre multicast e unicast?
Multicast é um método um-para-muitos, onde um único fluxo de dados é enviado simultaneamente para um grupo de destinatários predefinido. É uma abordagem altamente eficiente para comunicação em grupo, como streaming de vídeo, pois conserva a largura de banda da rede.
Unicast é um modelo um-para-um, onde um pacote de dados é enviado de uma única fonte para um único destino. Isso estabelece um fluxo de dados exclusivo e dedicado para cada destinatário, sendo ideal para atividades como navegação na web ou chamadas de vídeos individuais.


")

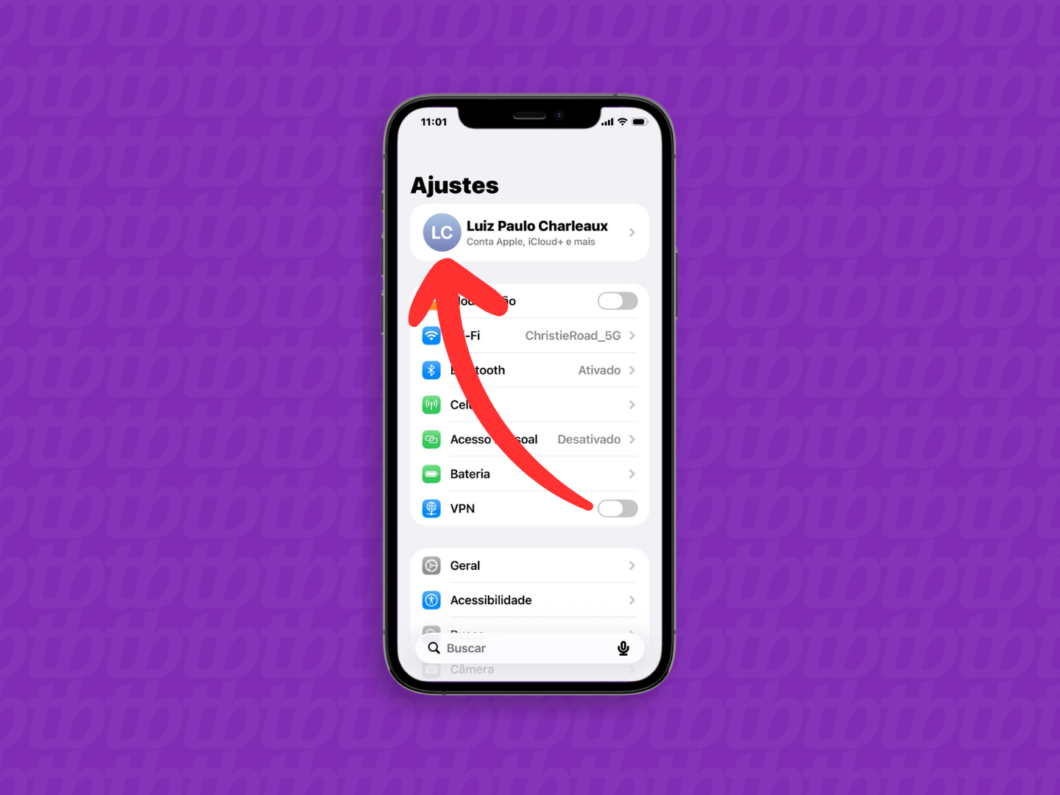
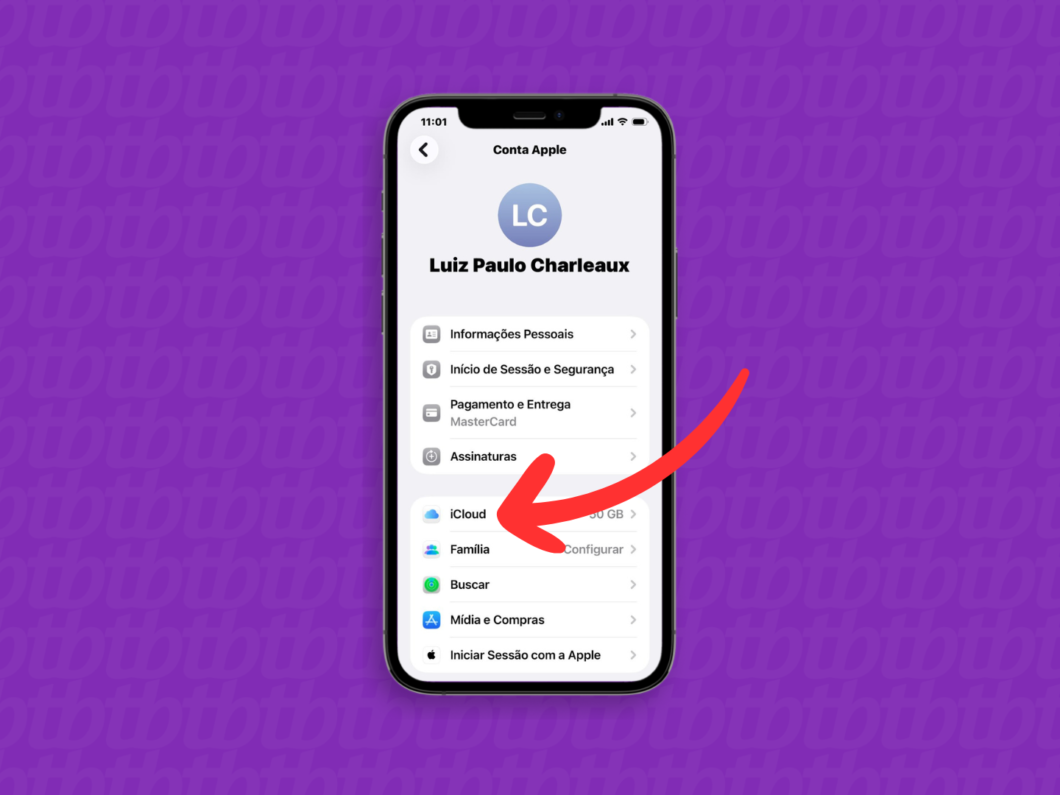
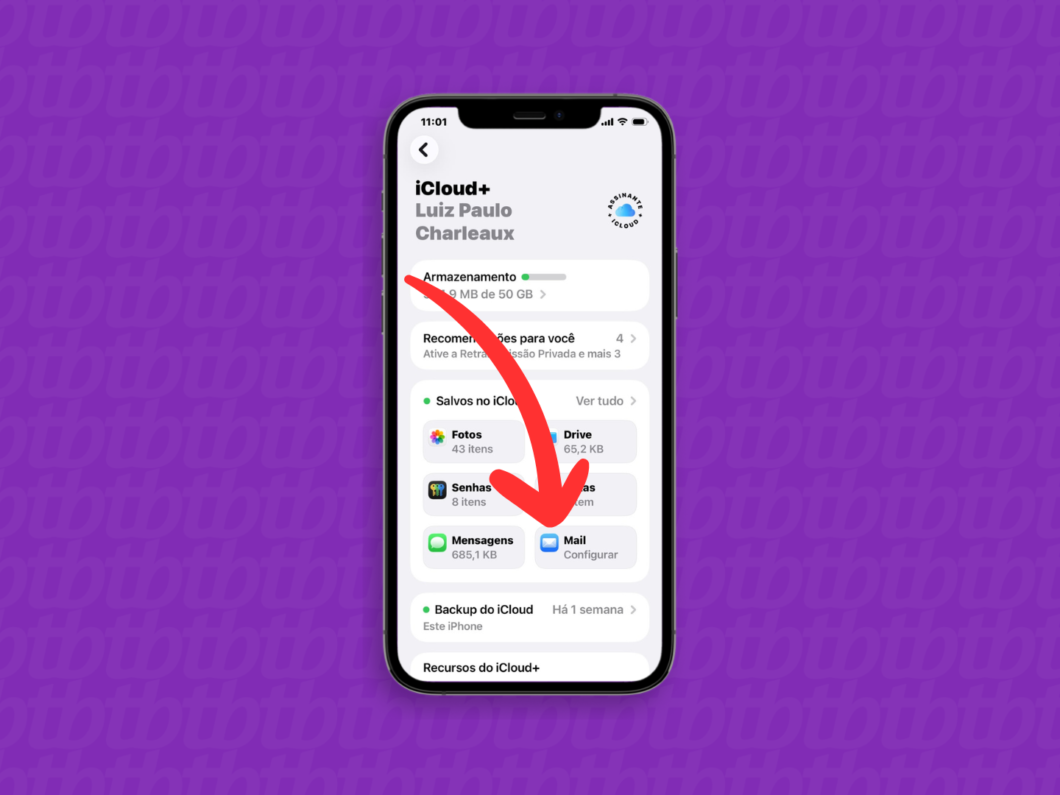
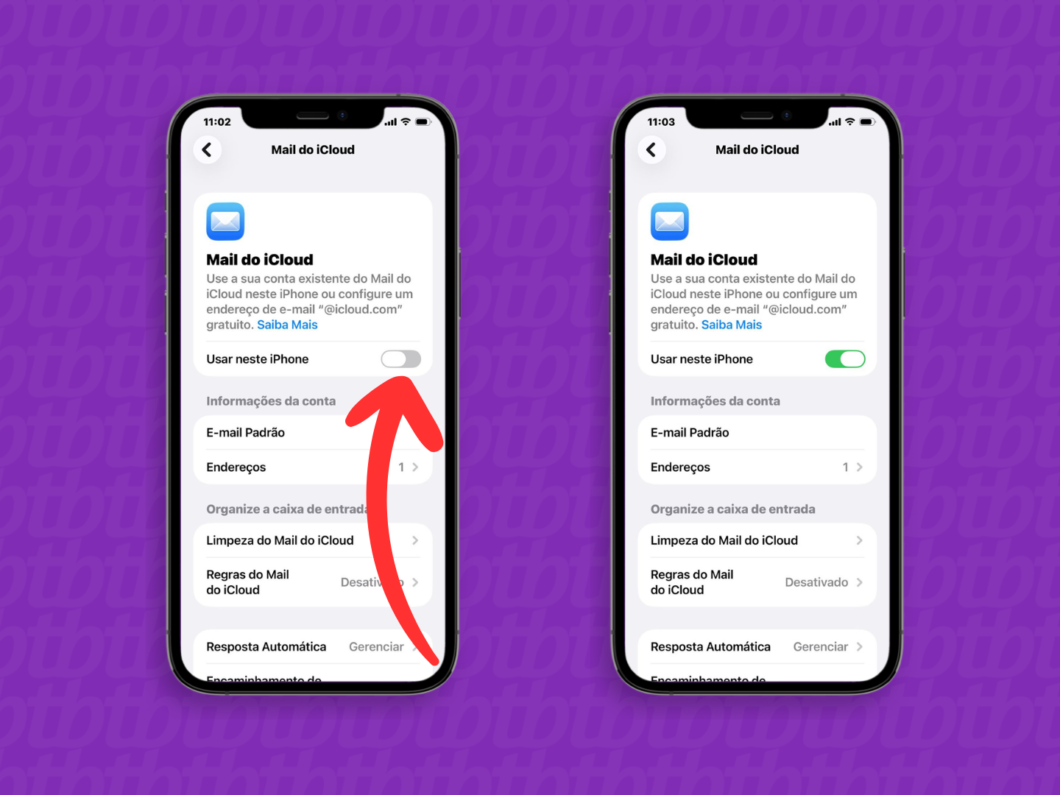
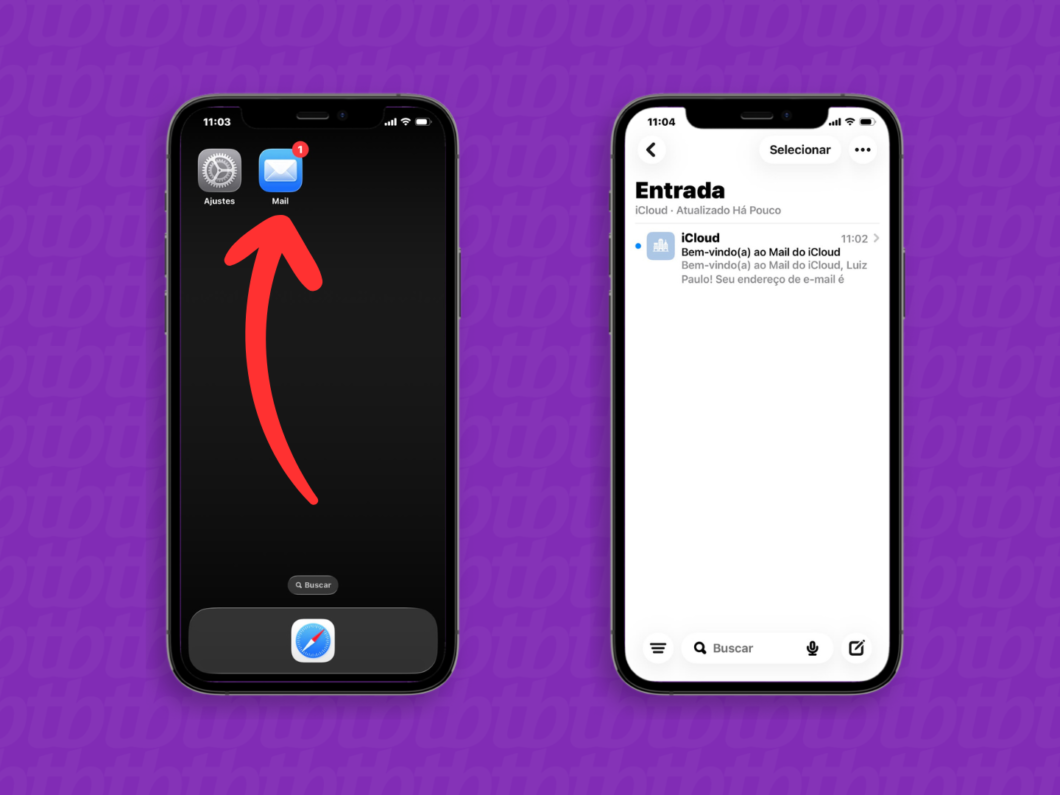
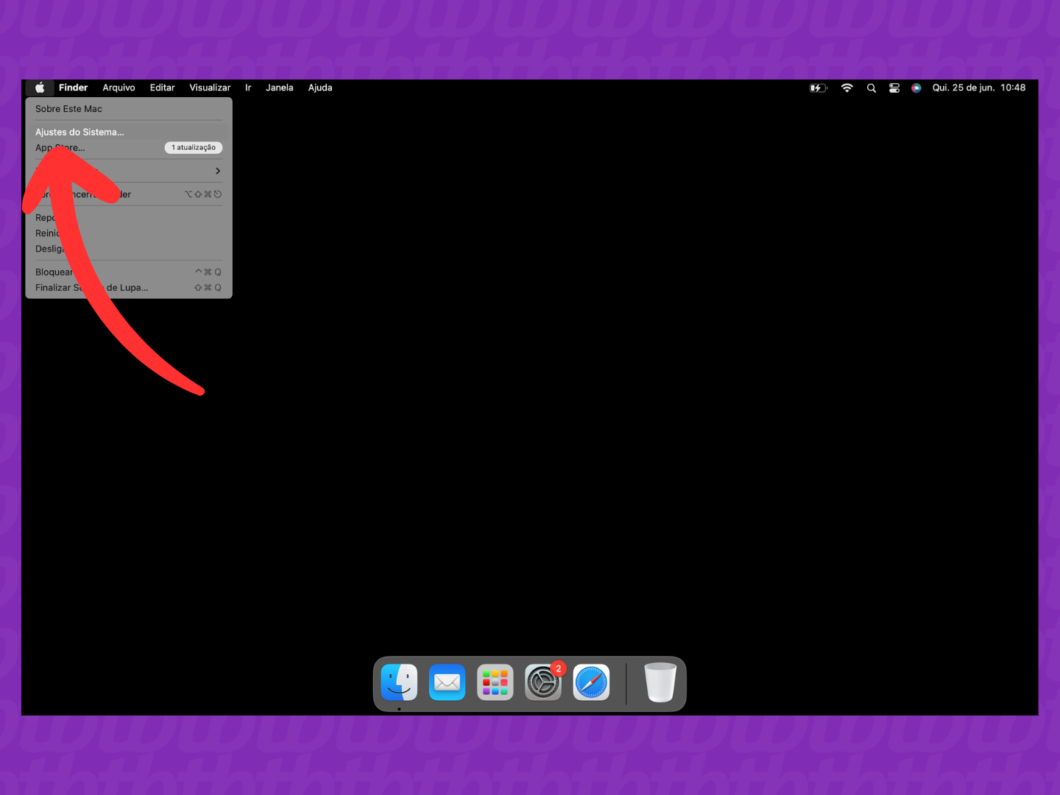
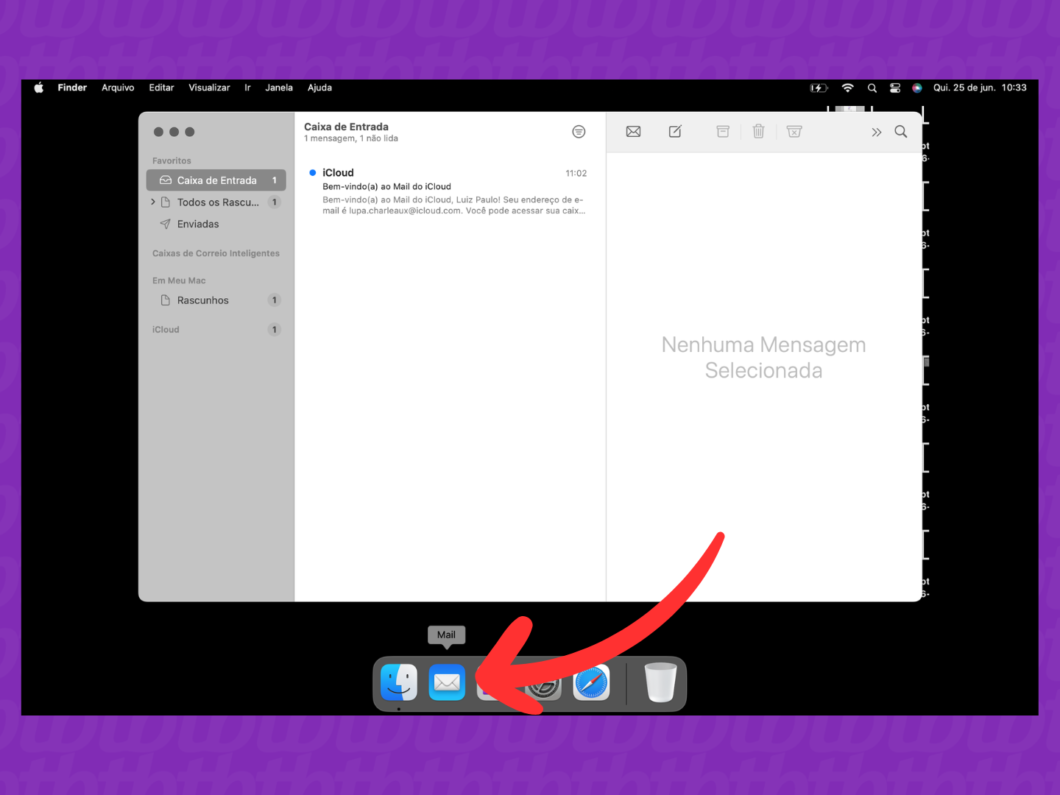
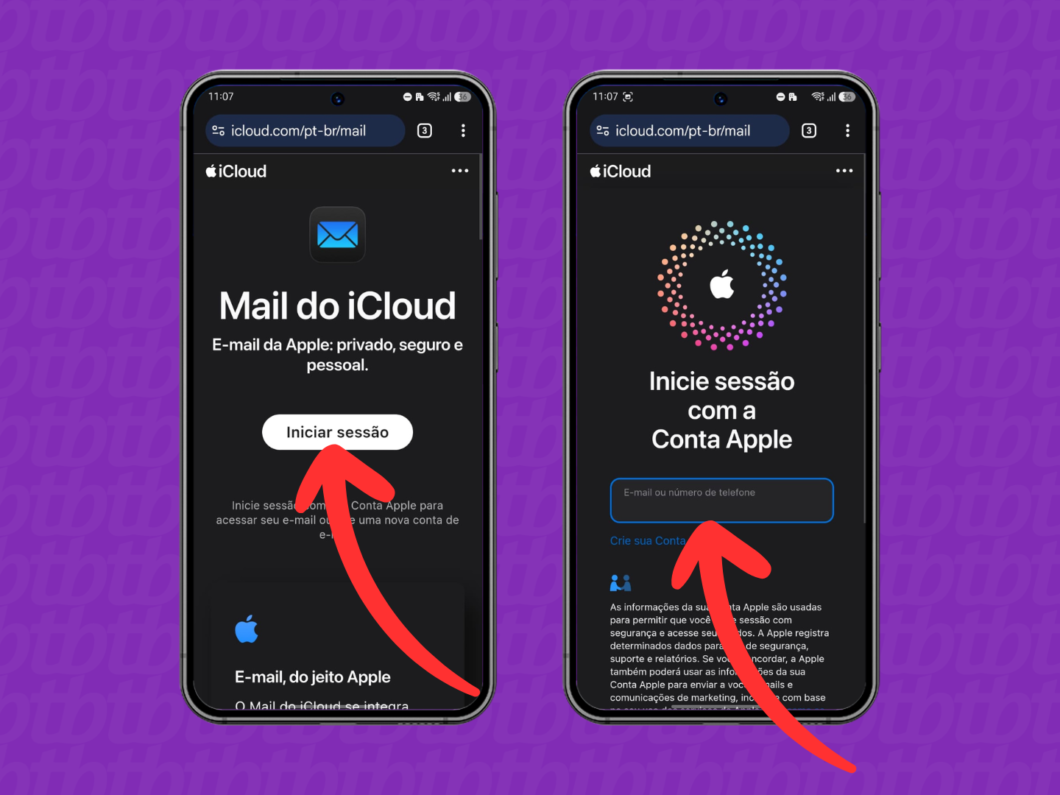
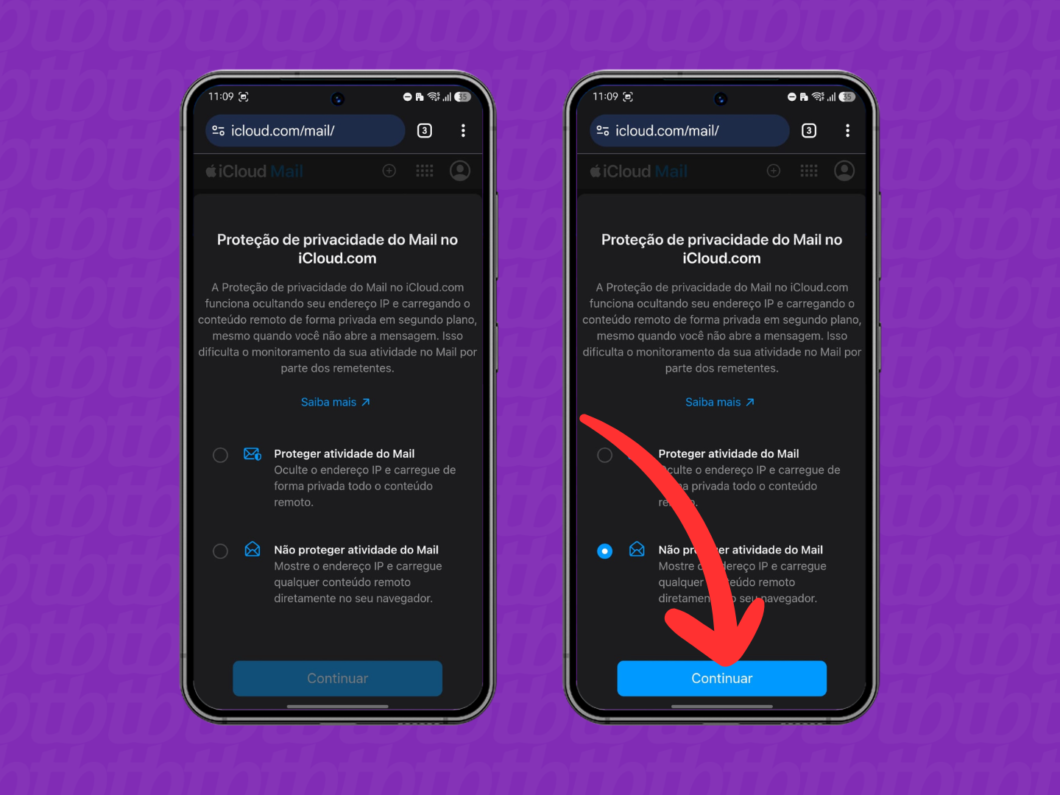
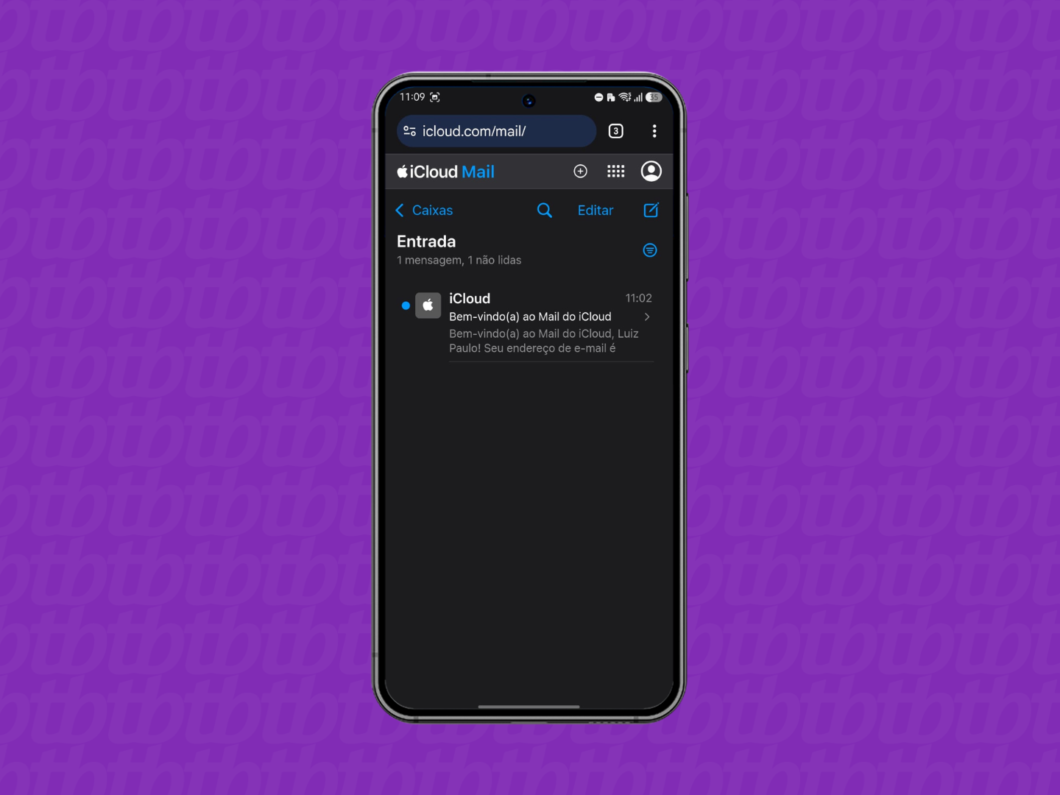


































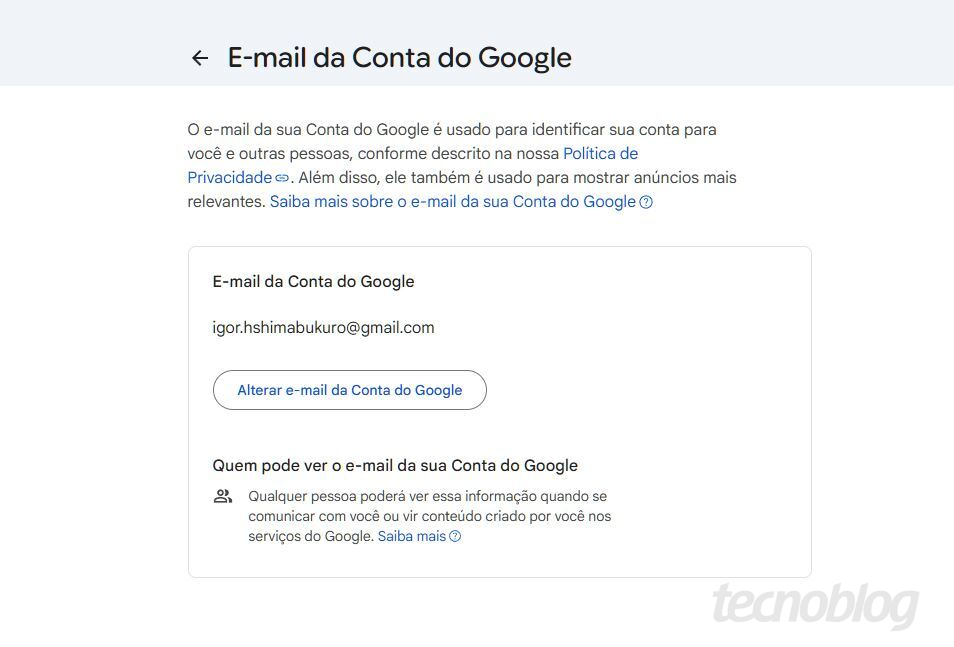


")



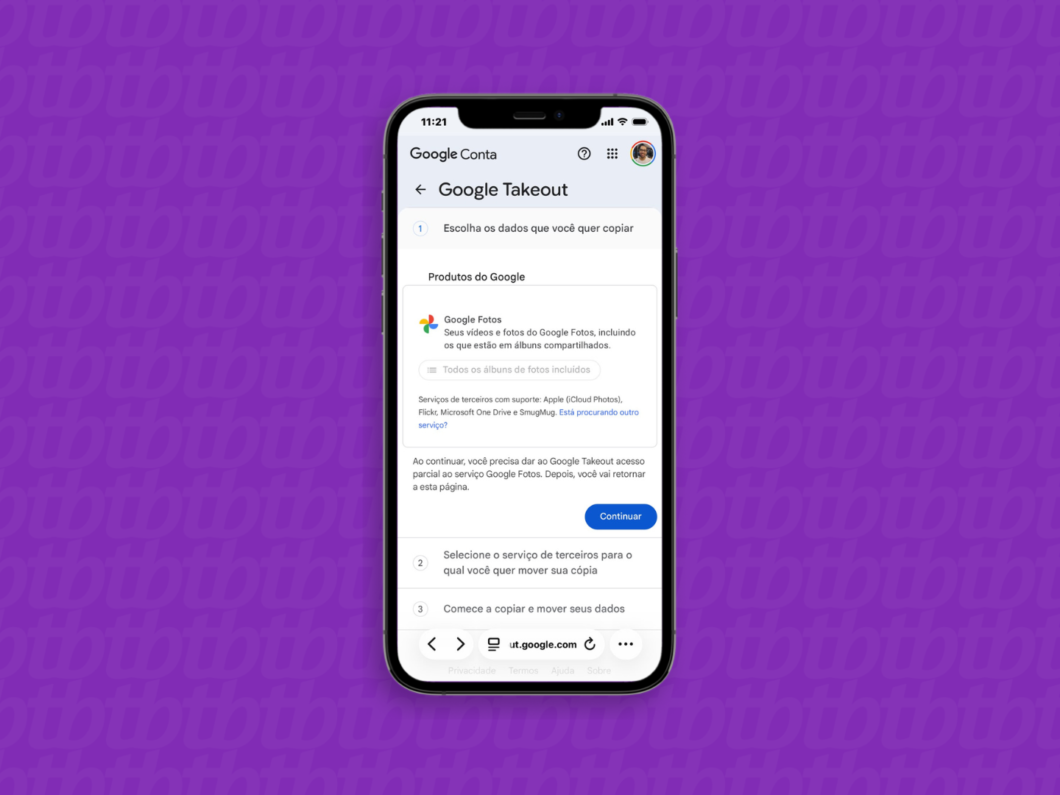
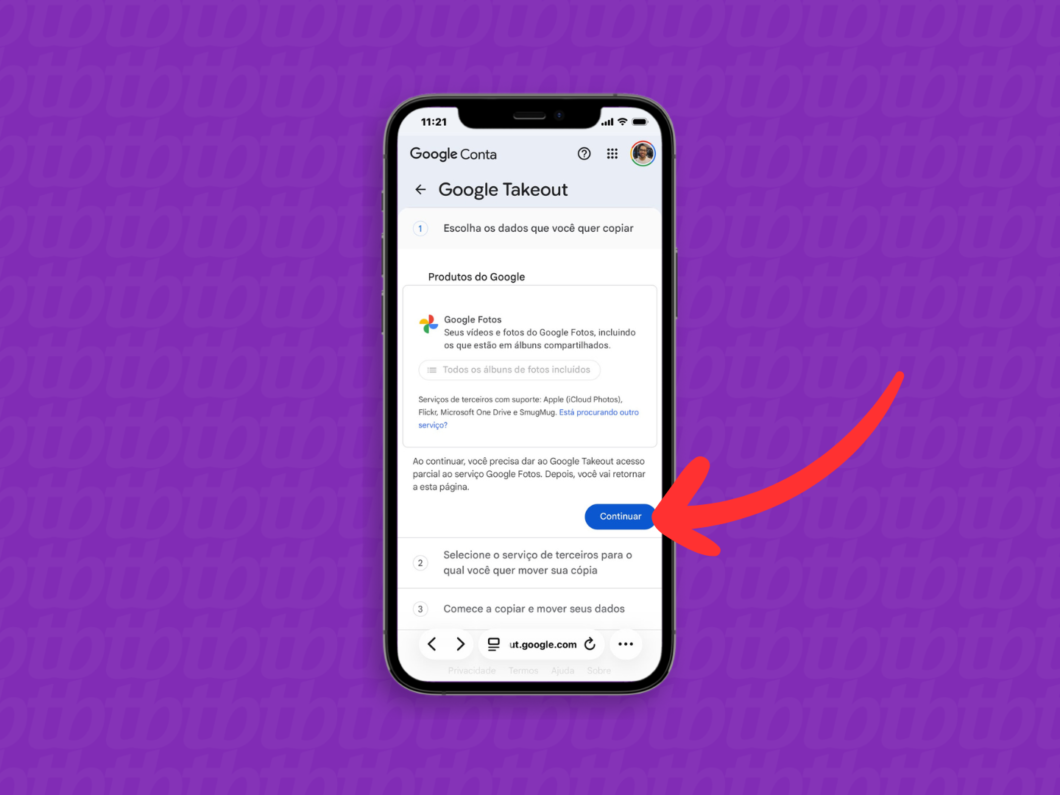
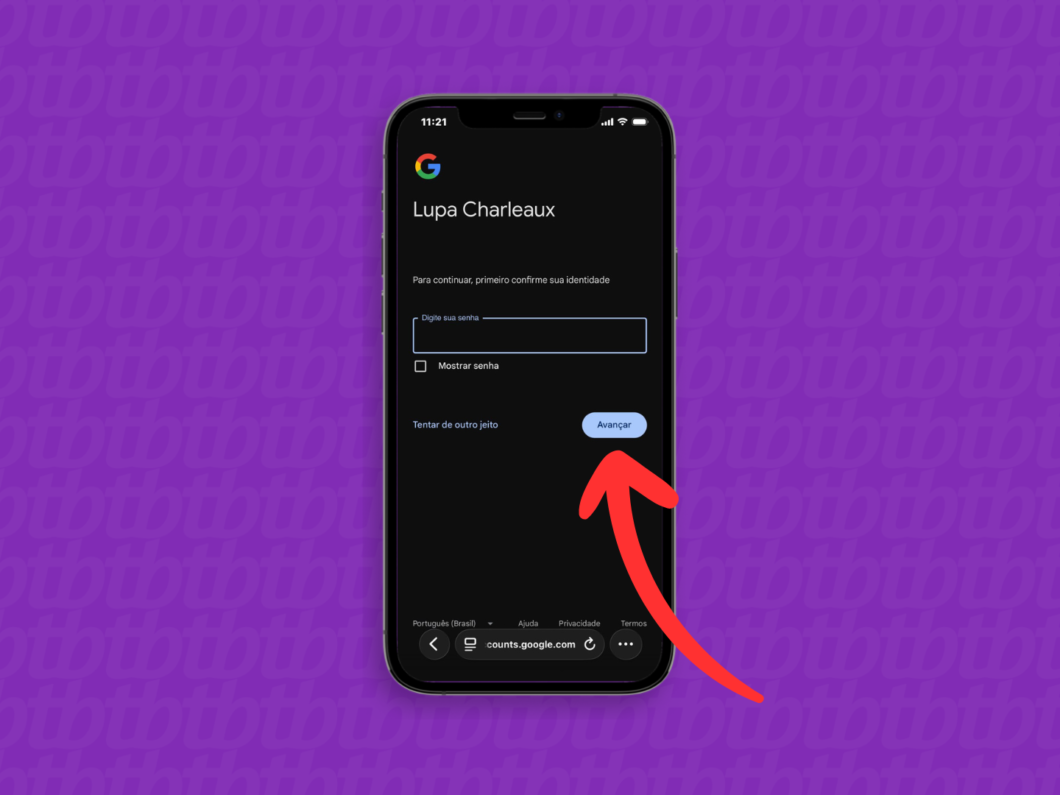
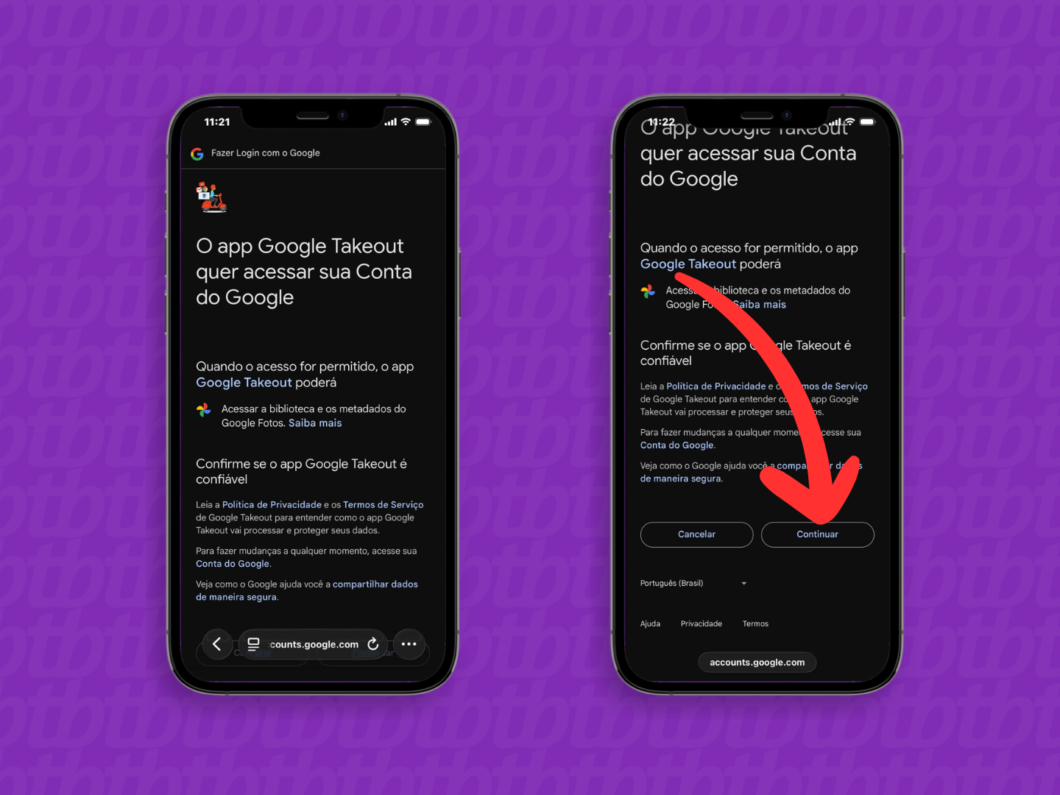
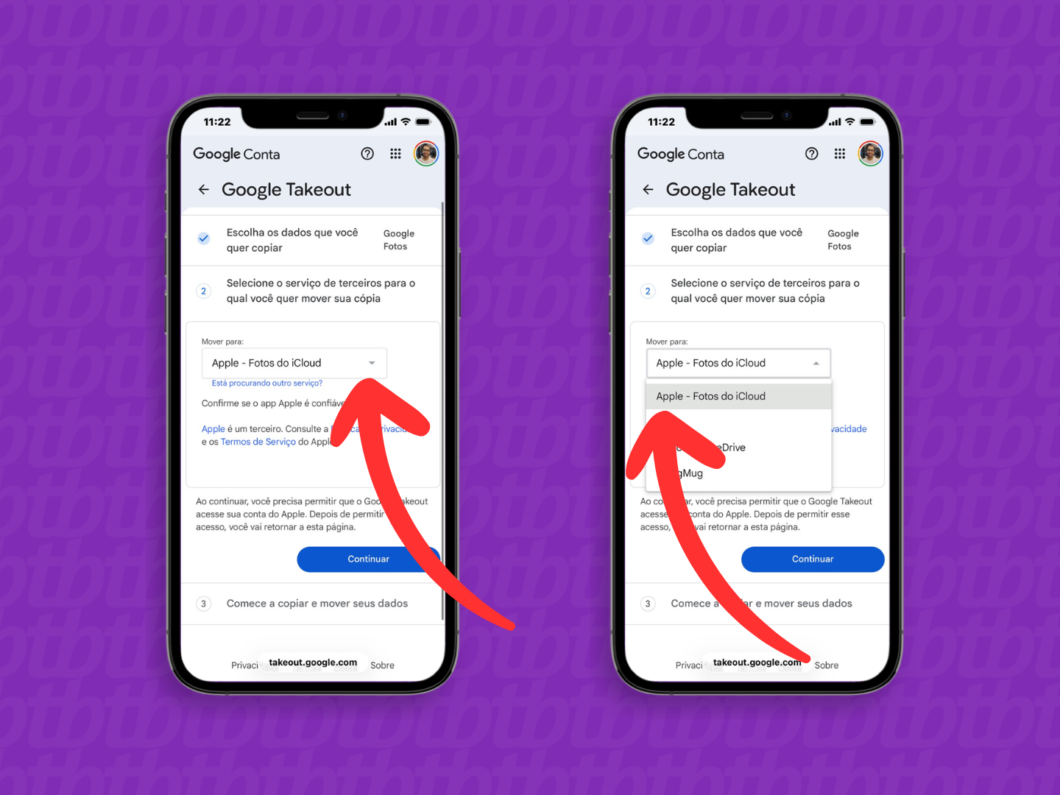
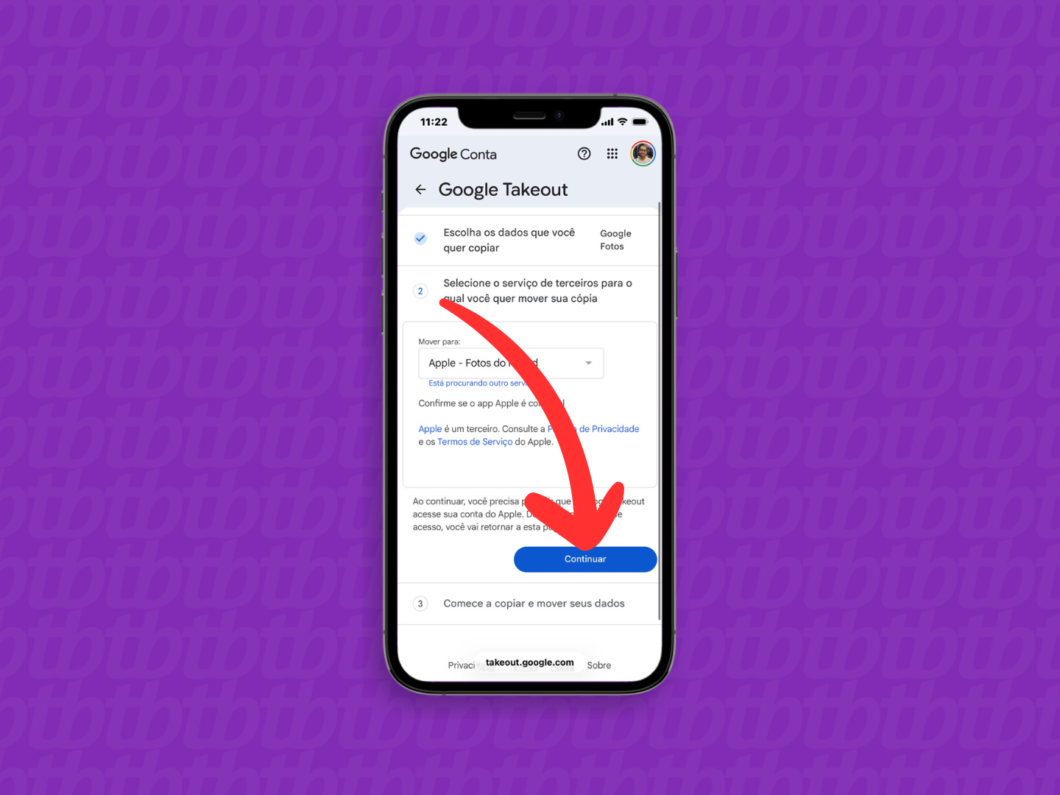
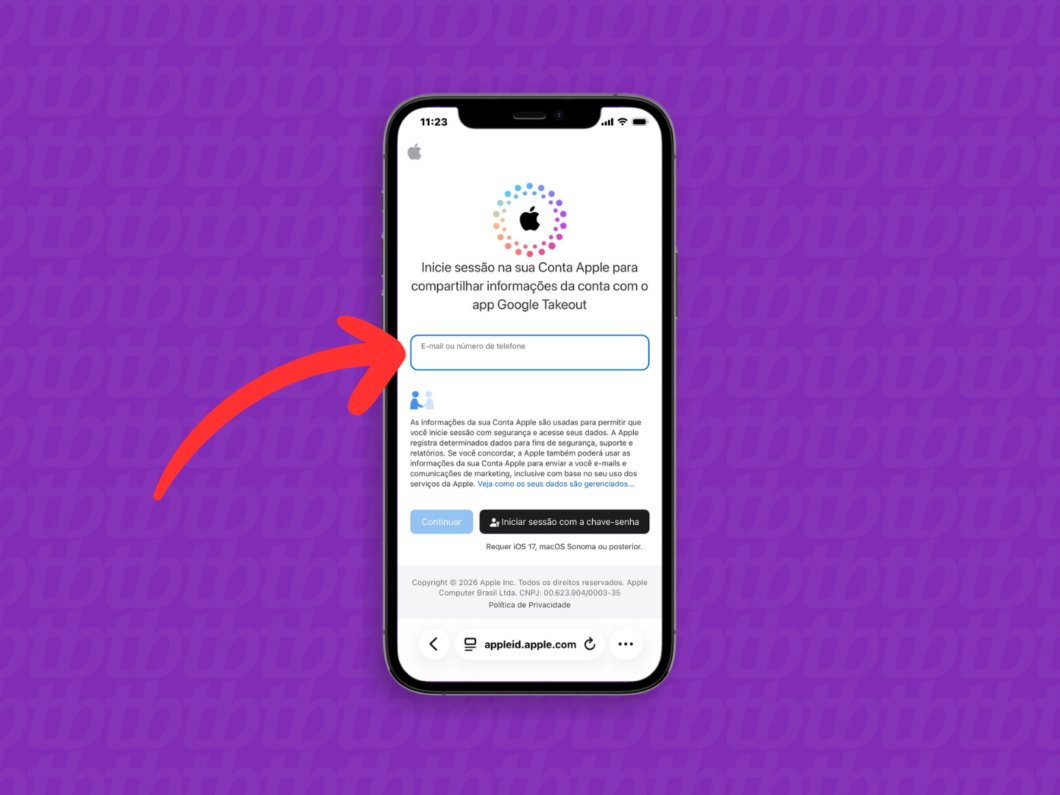
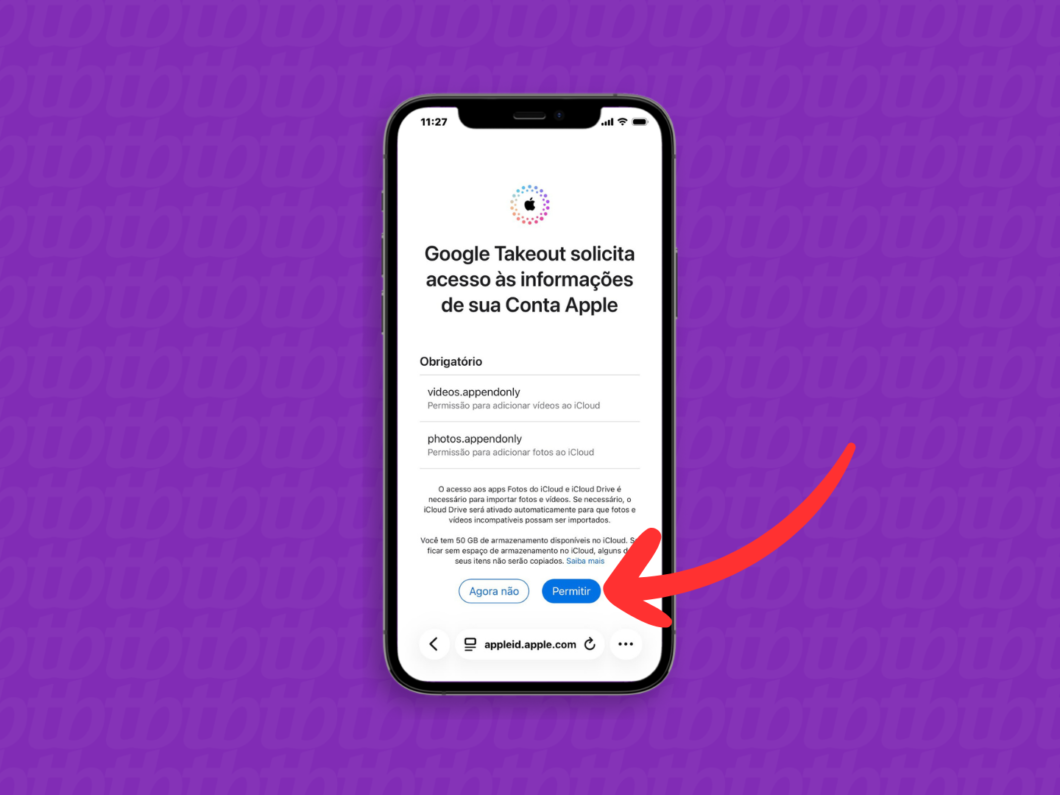
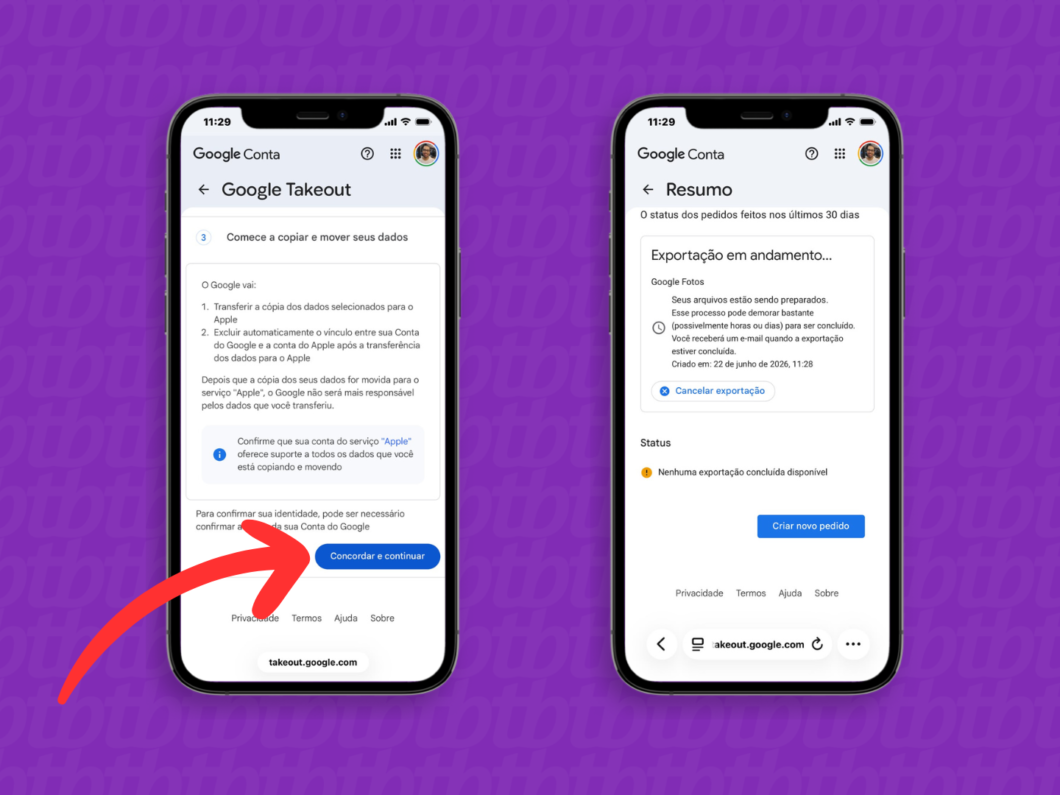
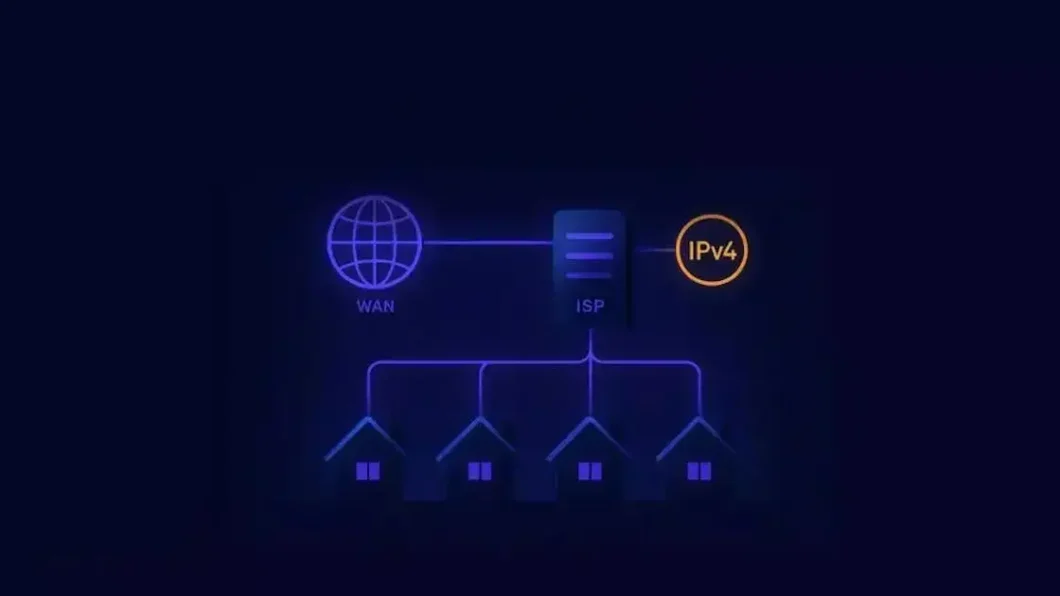

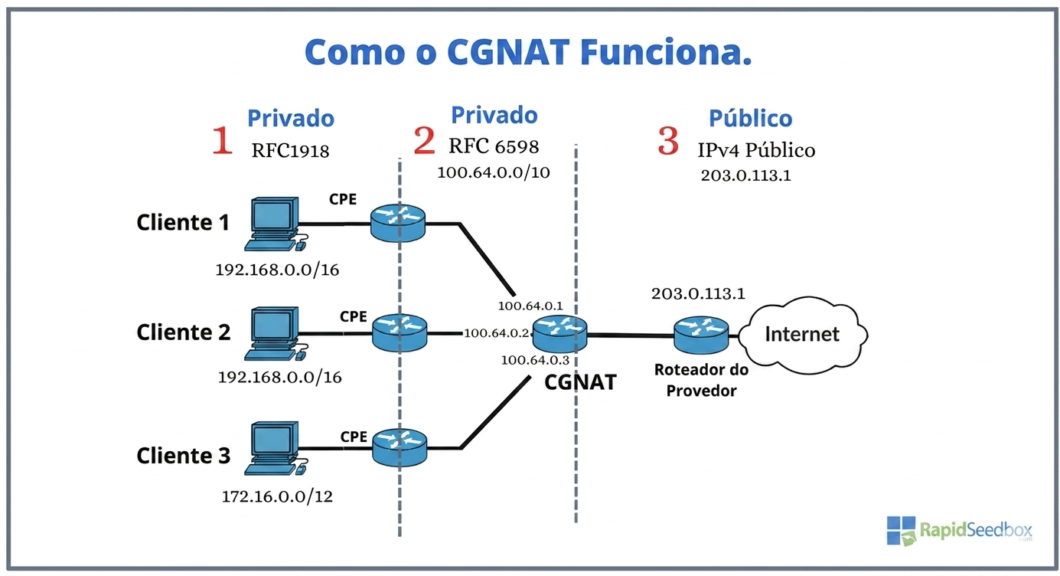















")
")
")
")
")
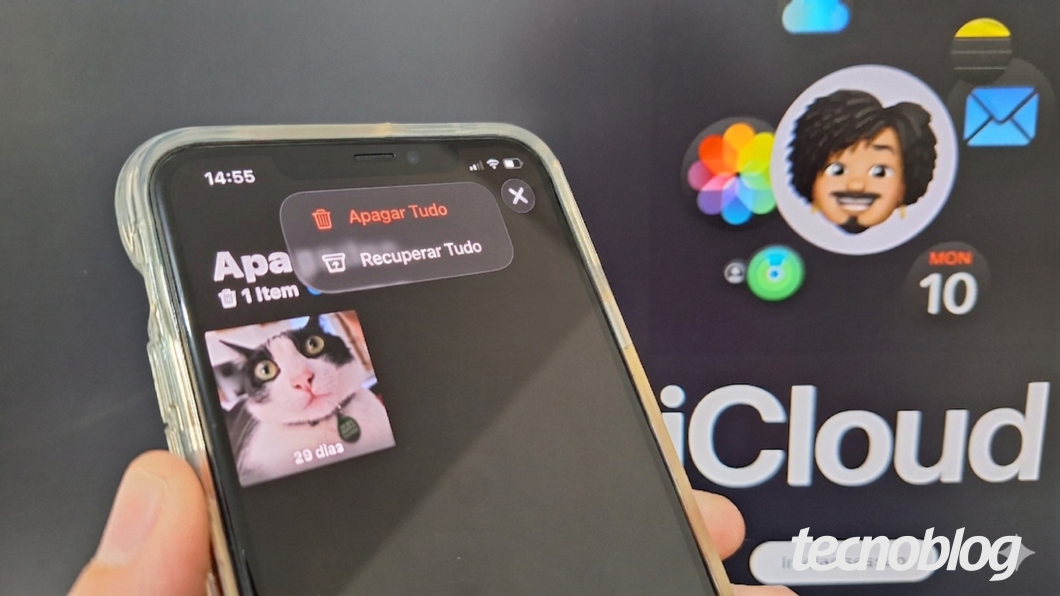

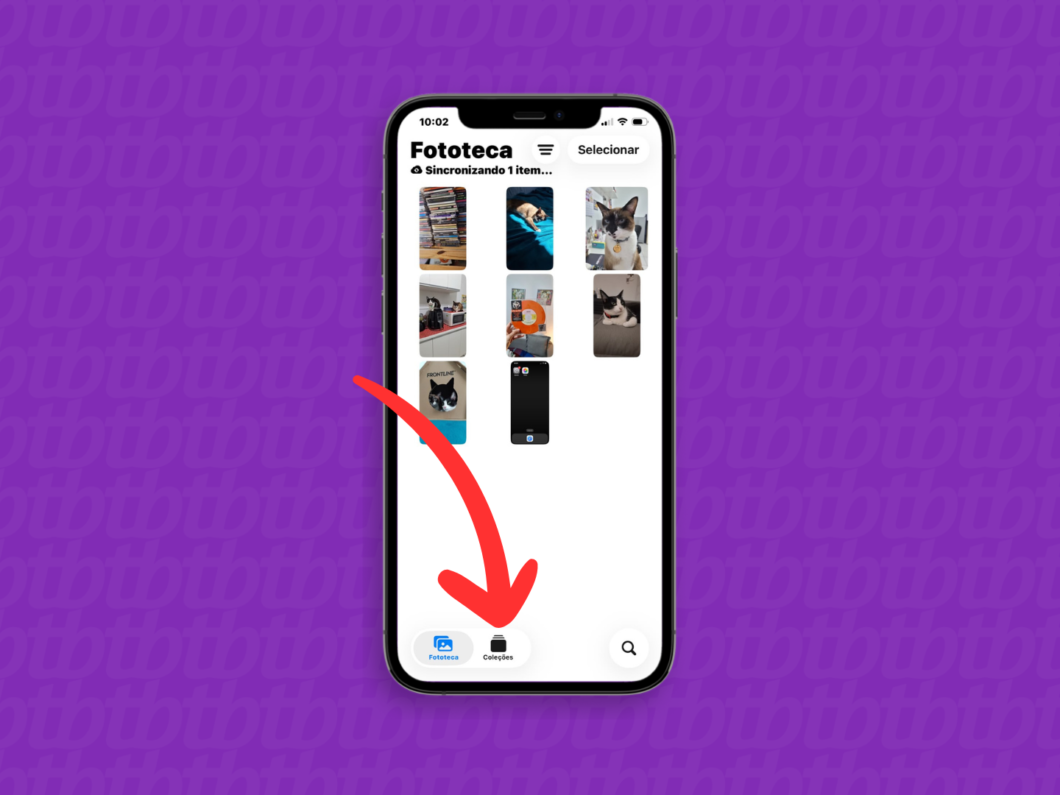
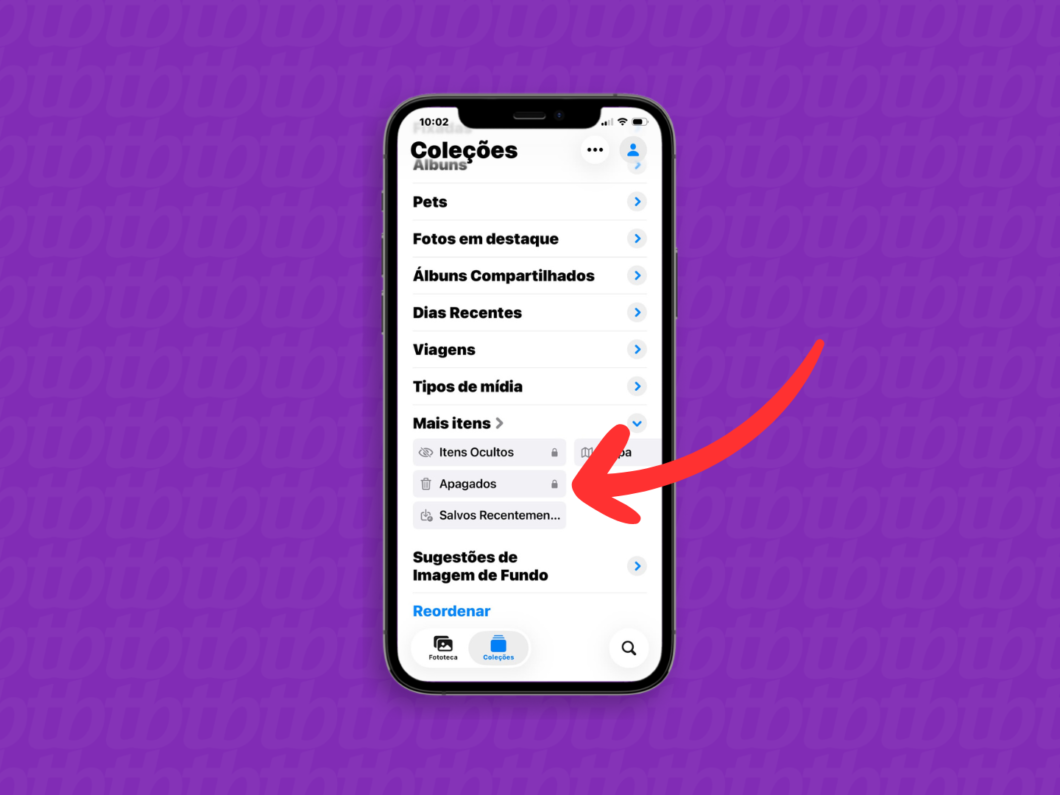
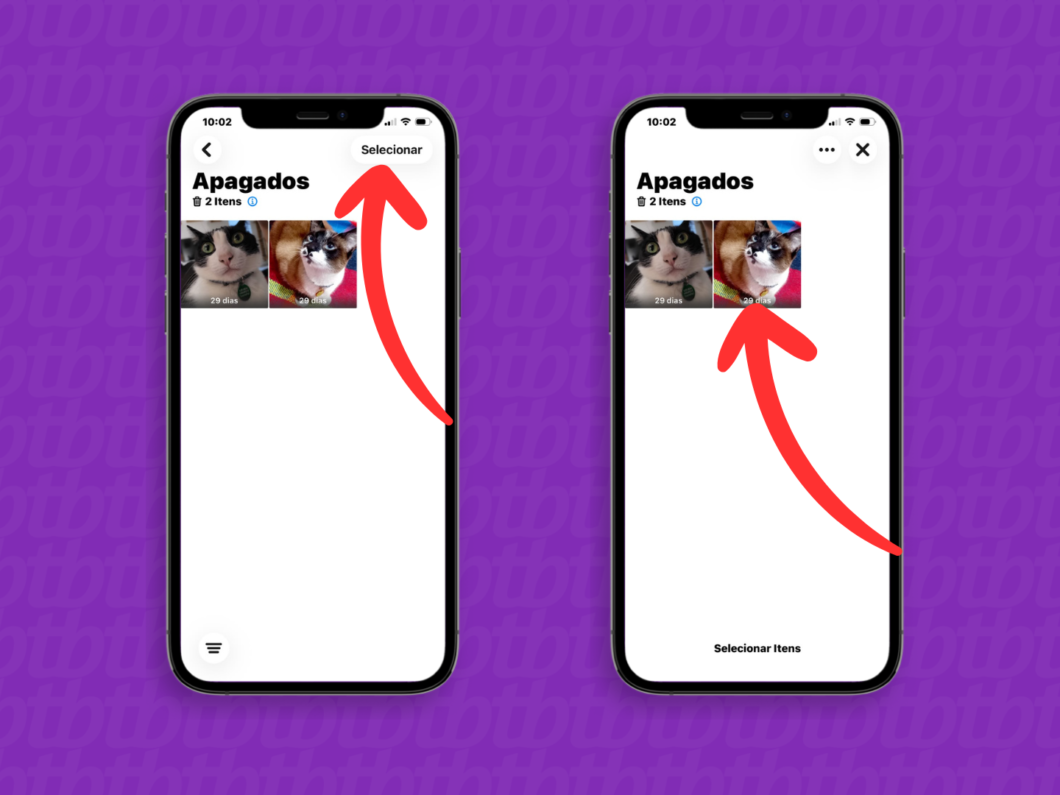
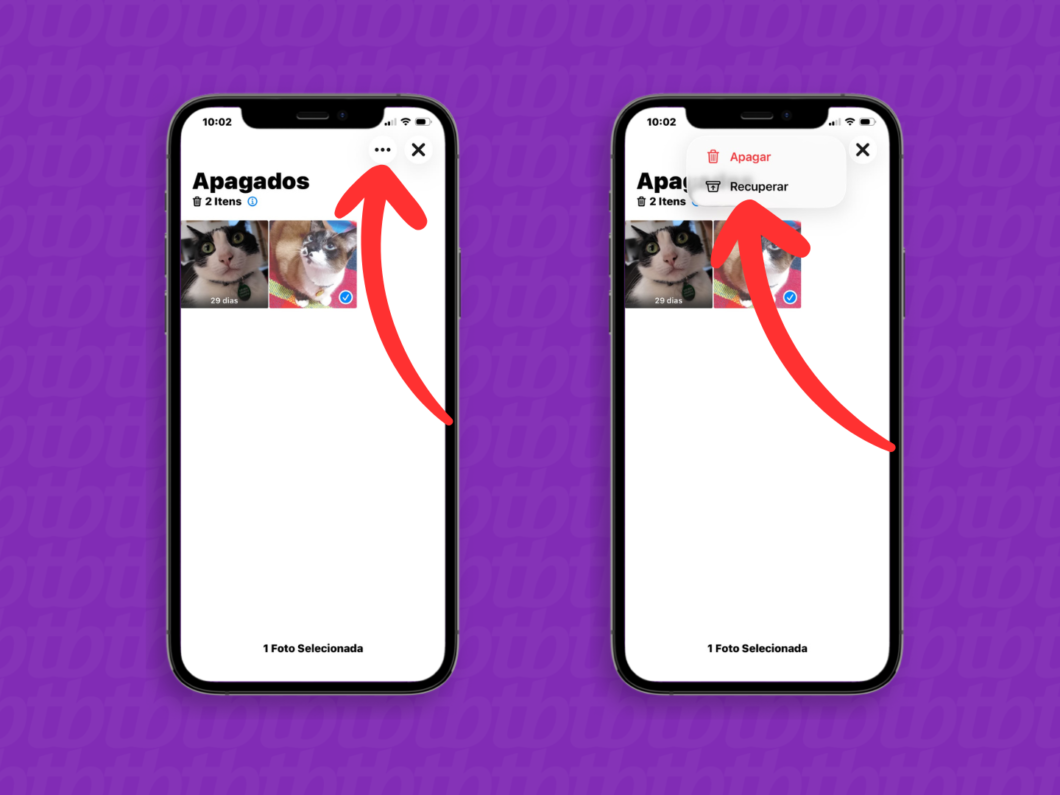

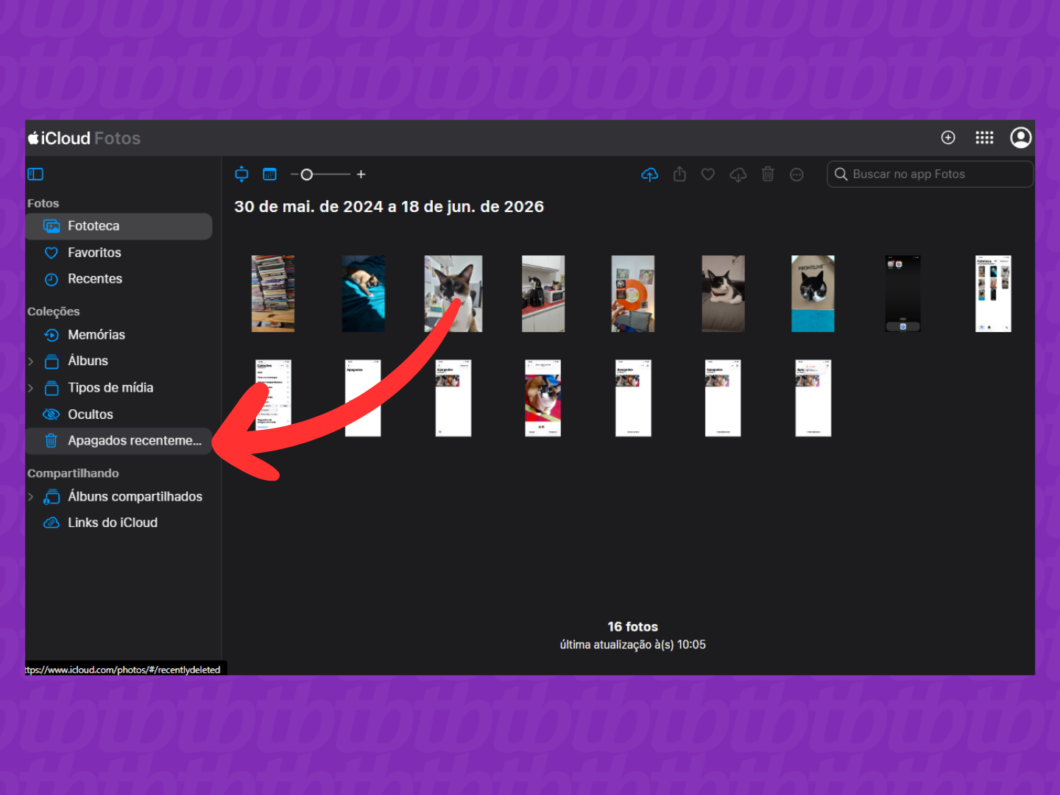
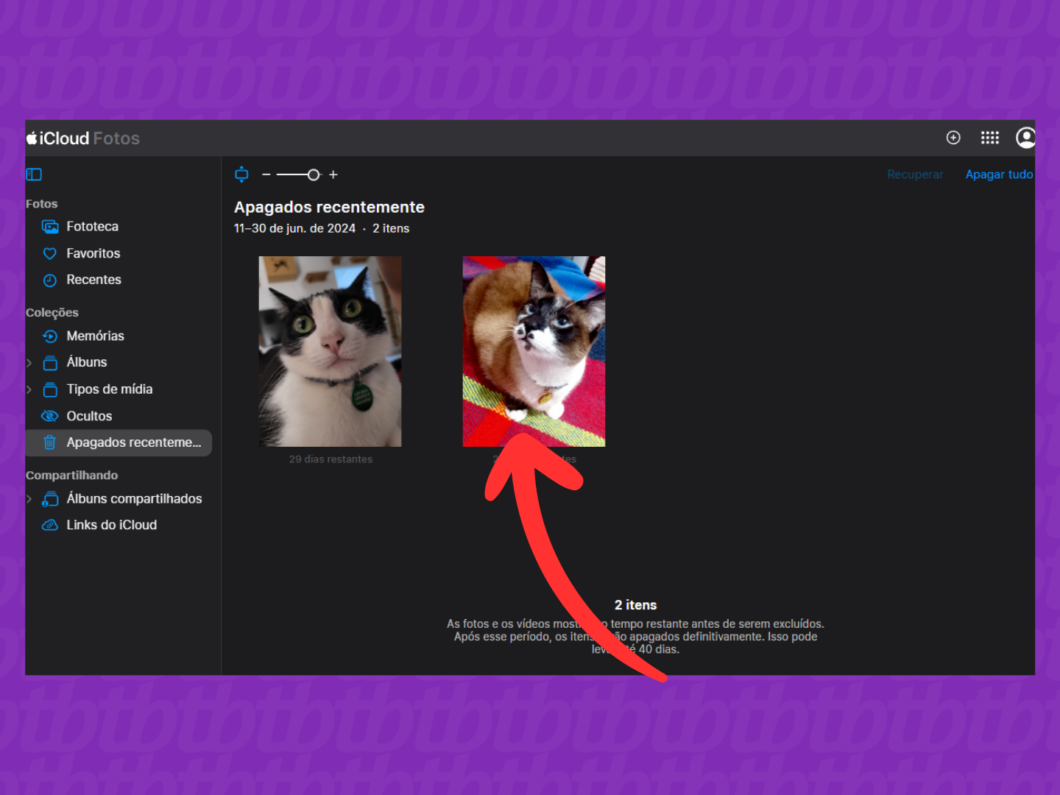
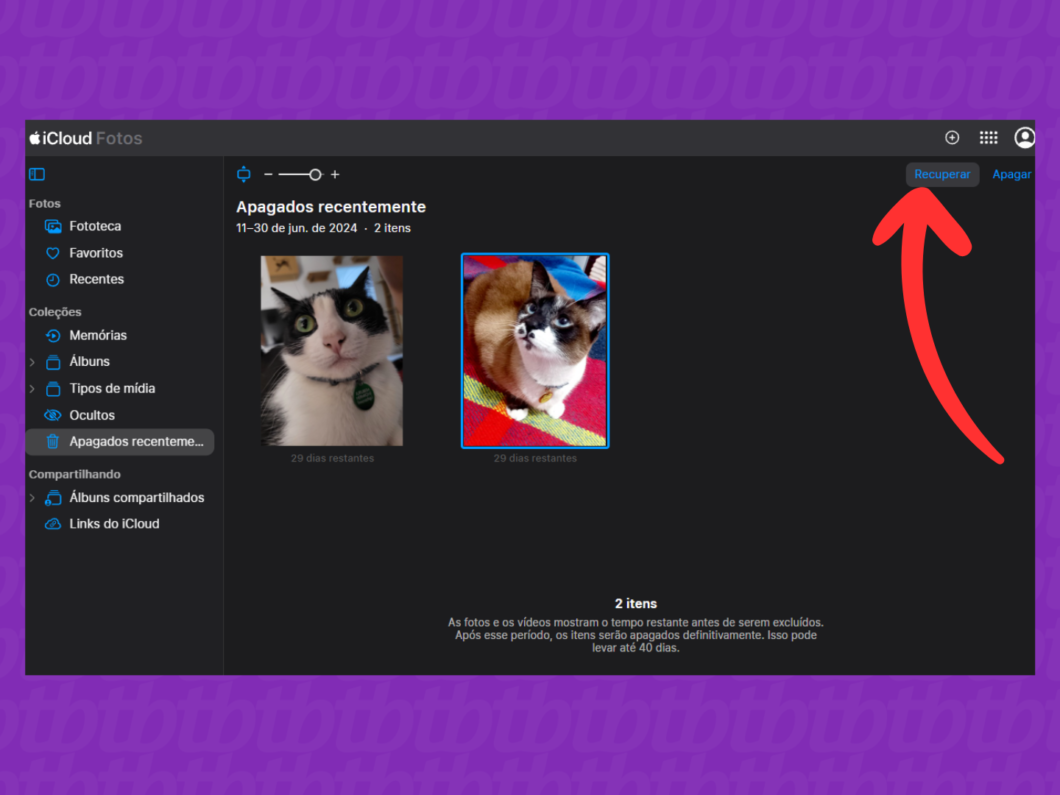
























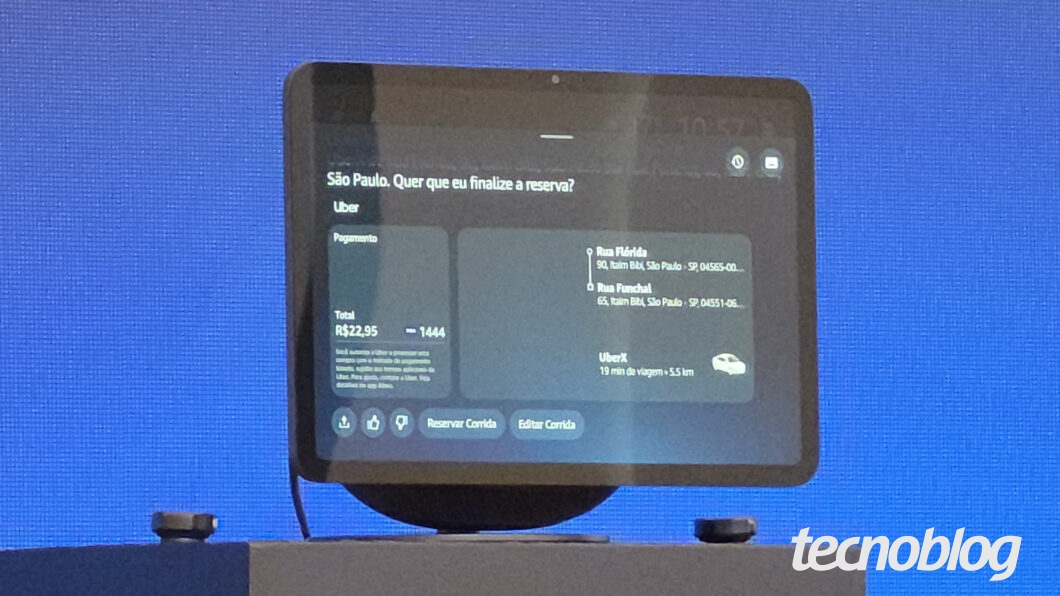



")
")
")
")
")
")
")
")
")



")
")

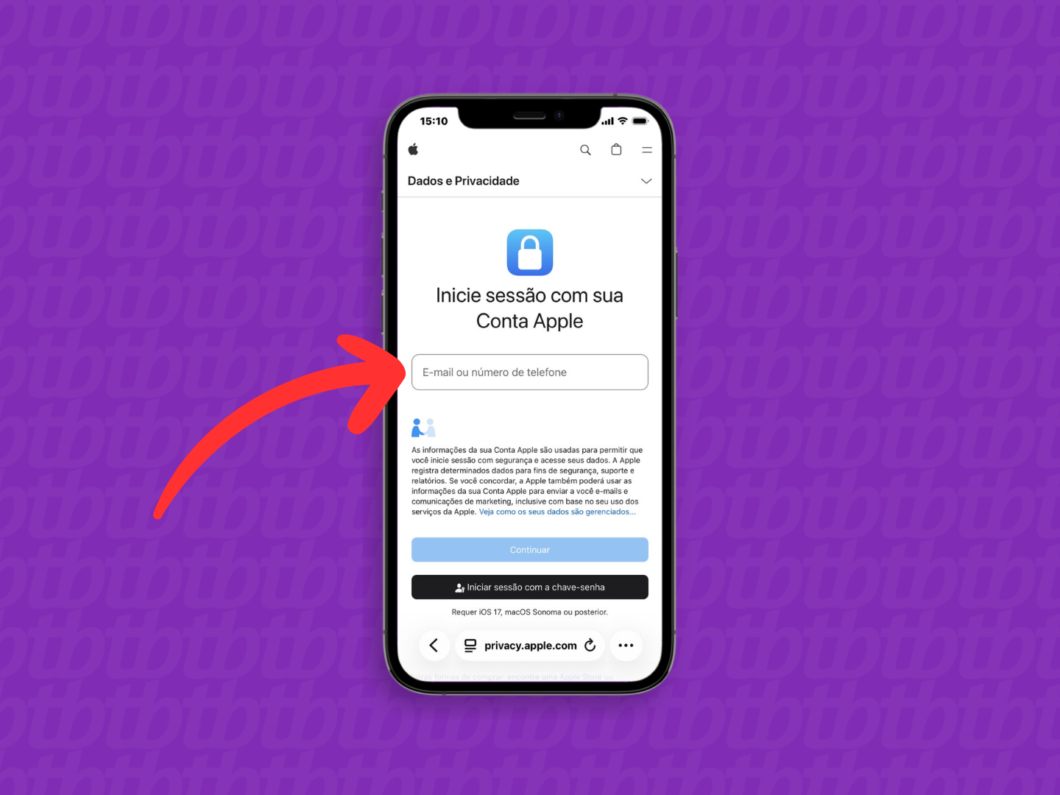
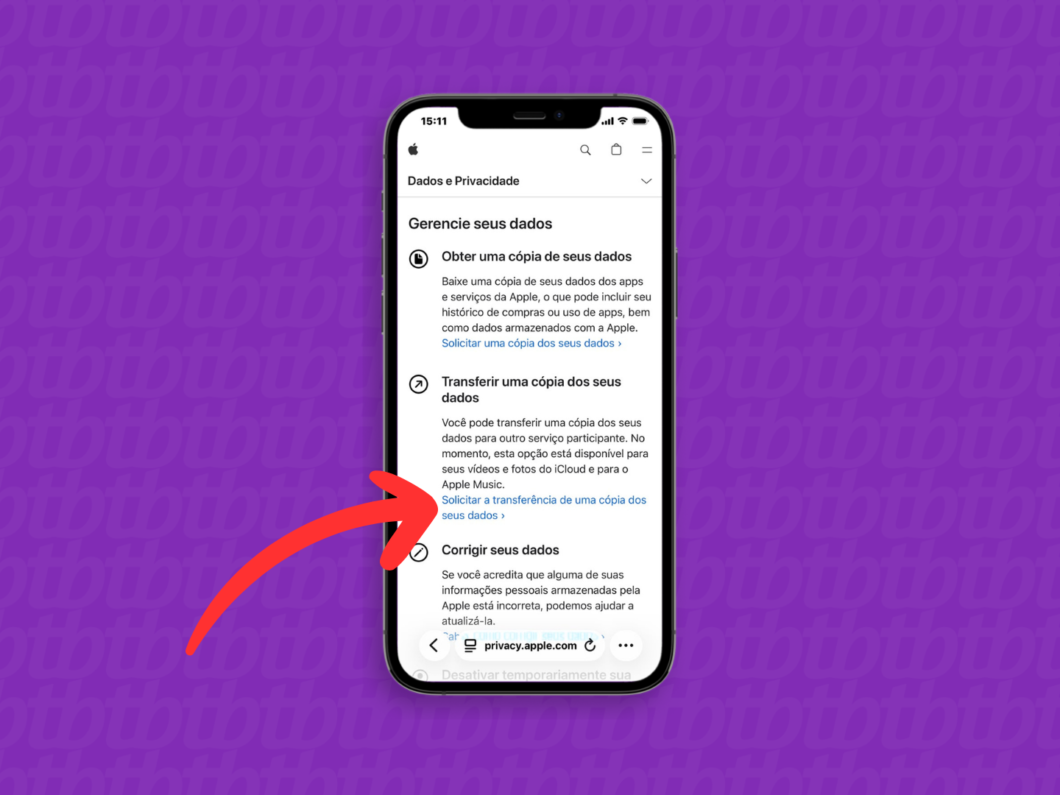
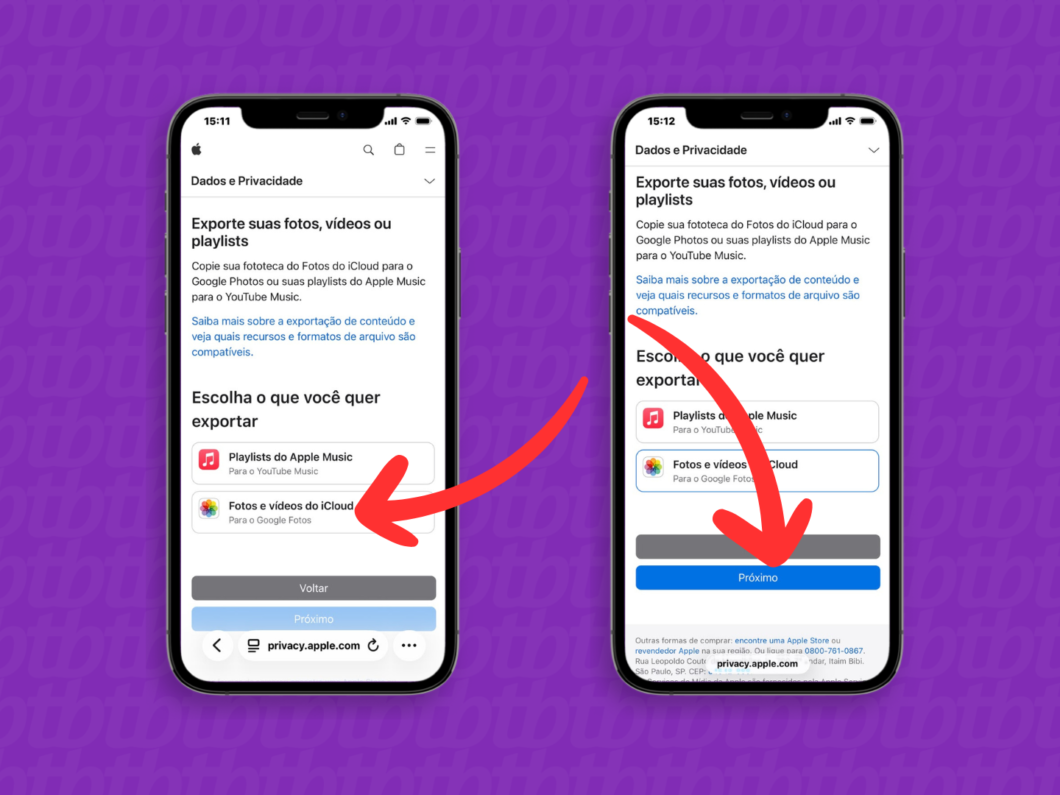
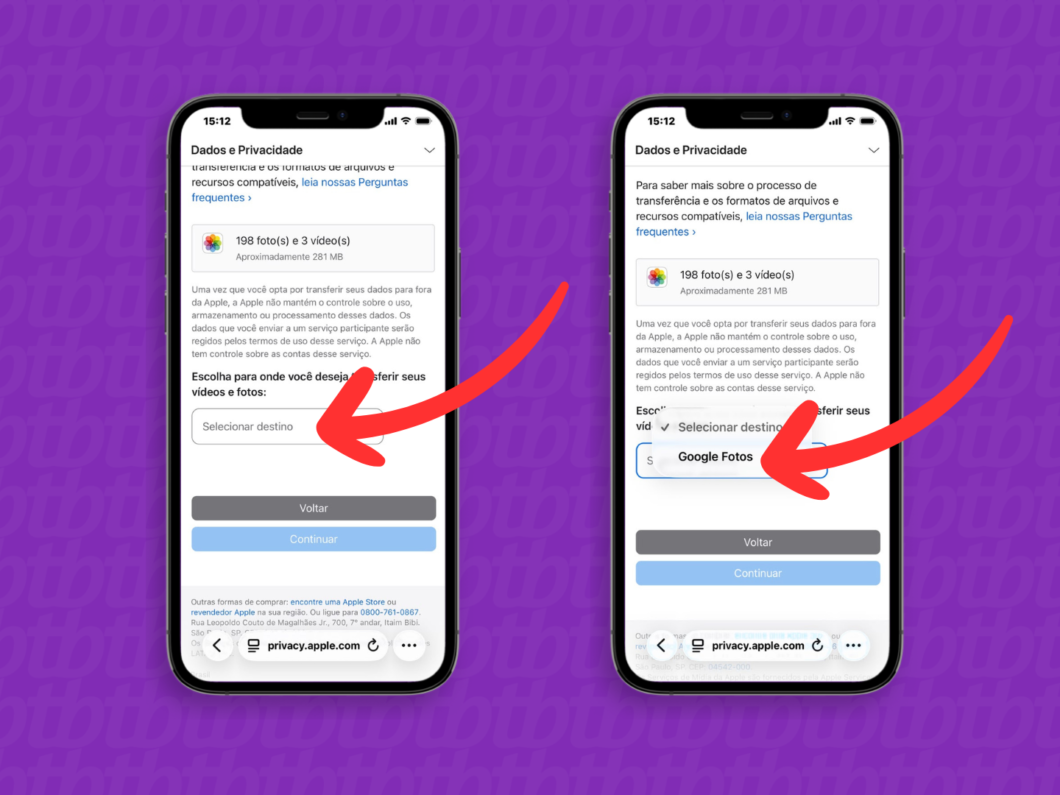
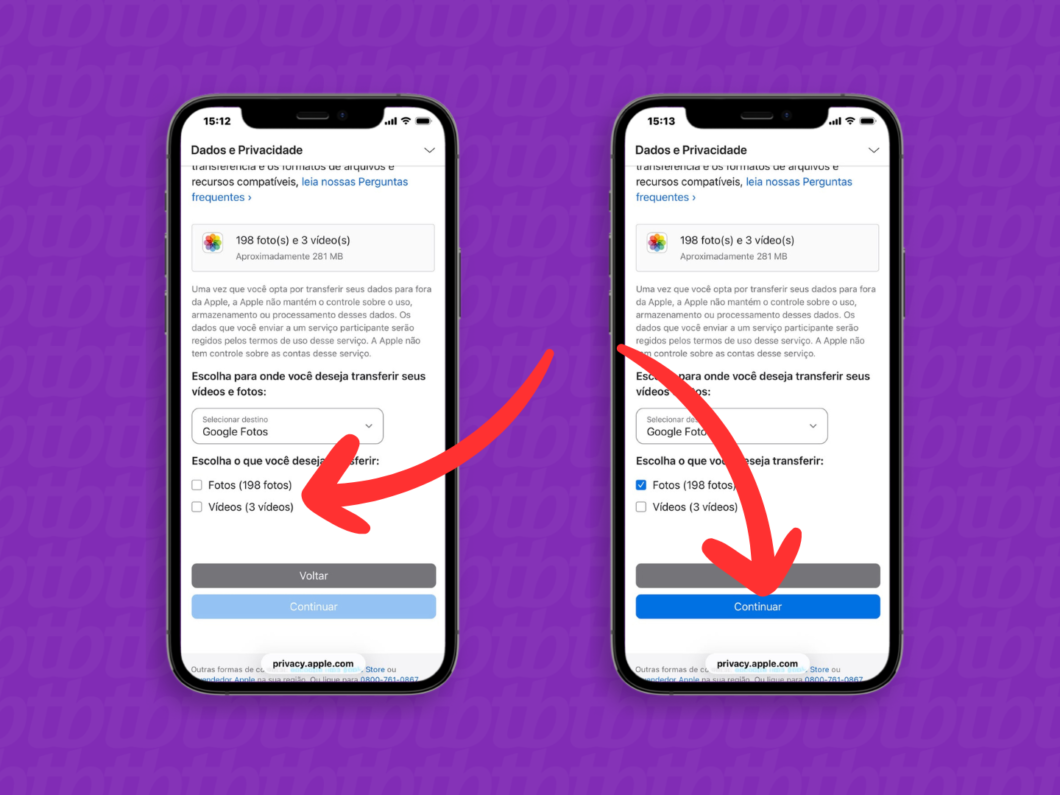
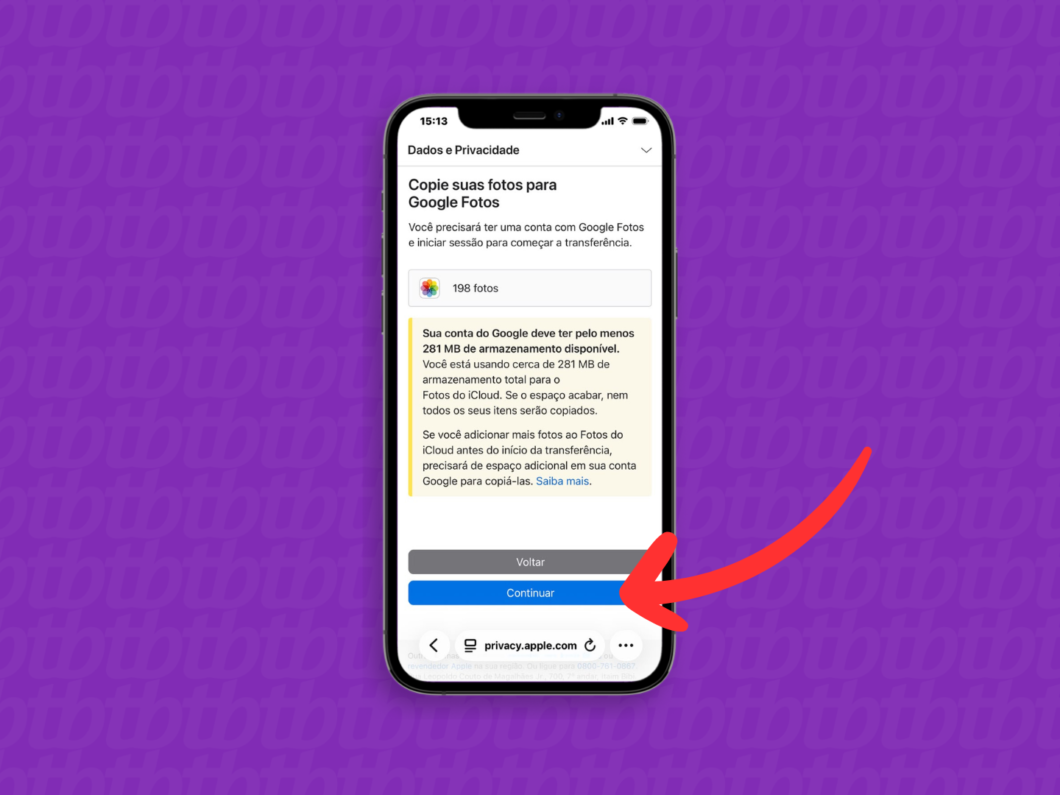
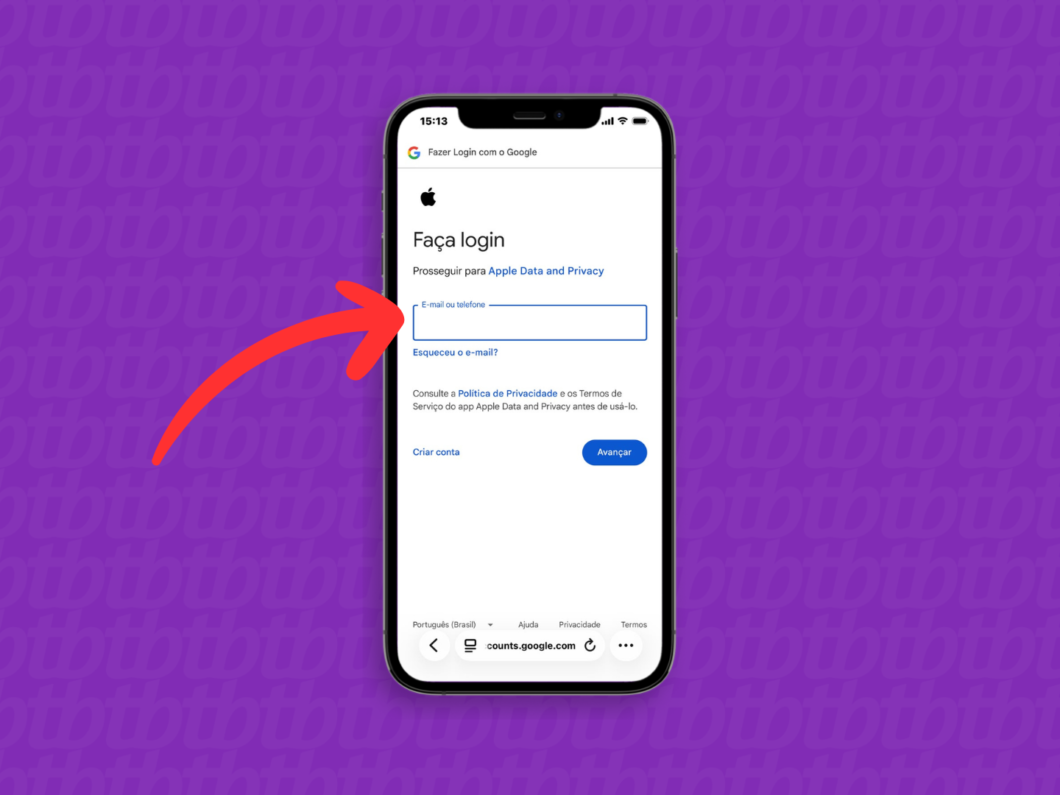
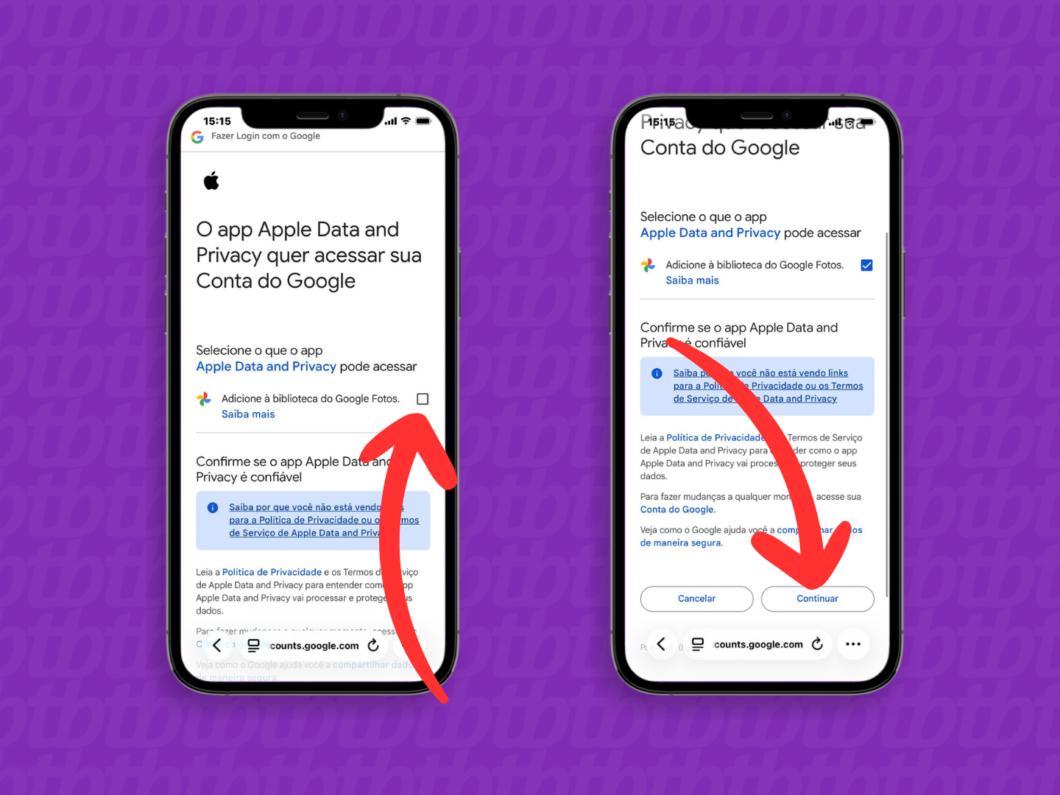
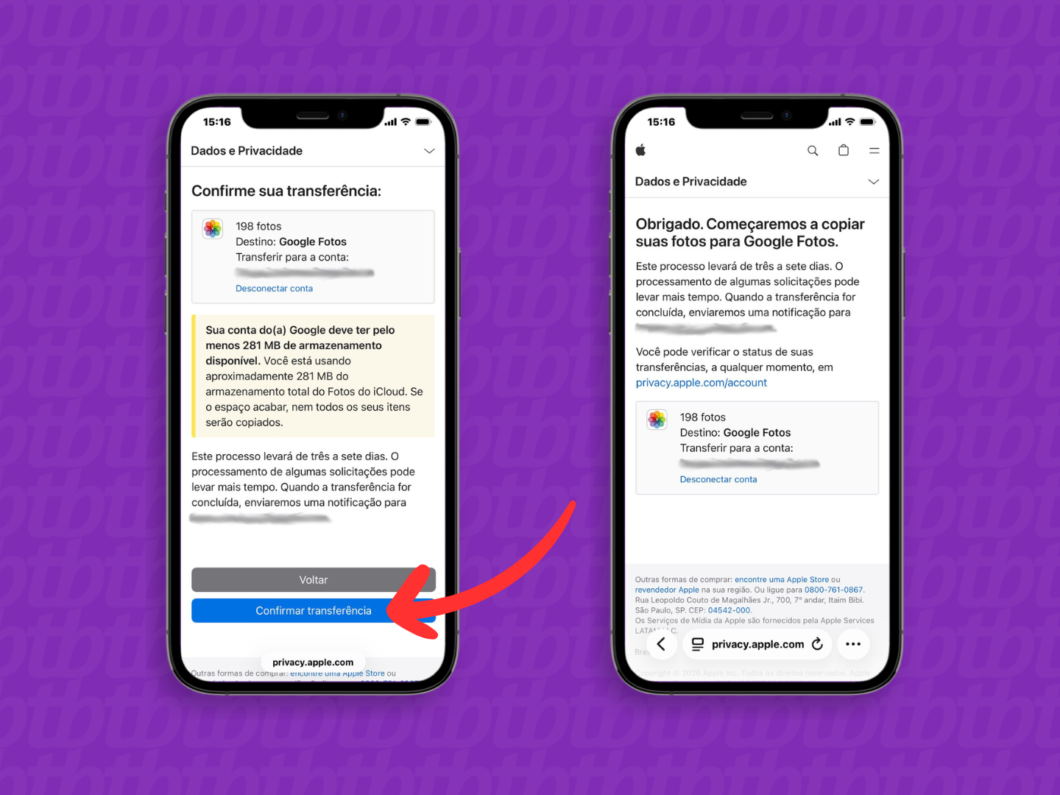



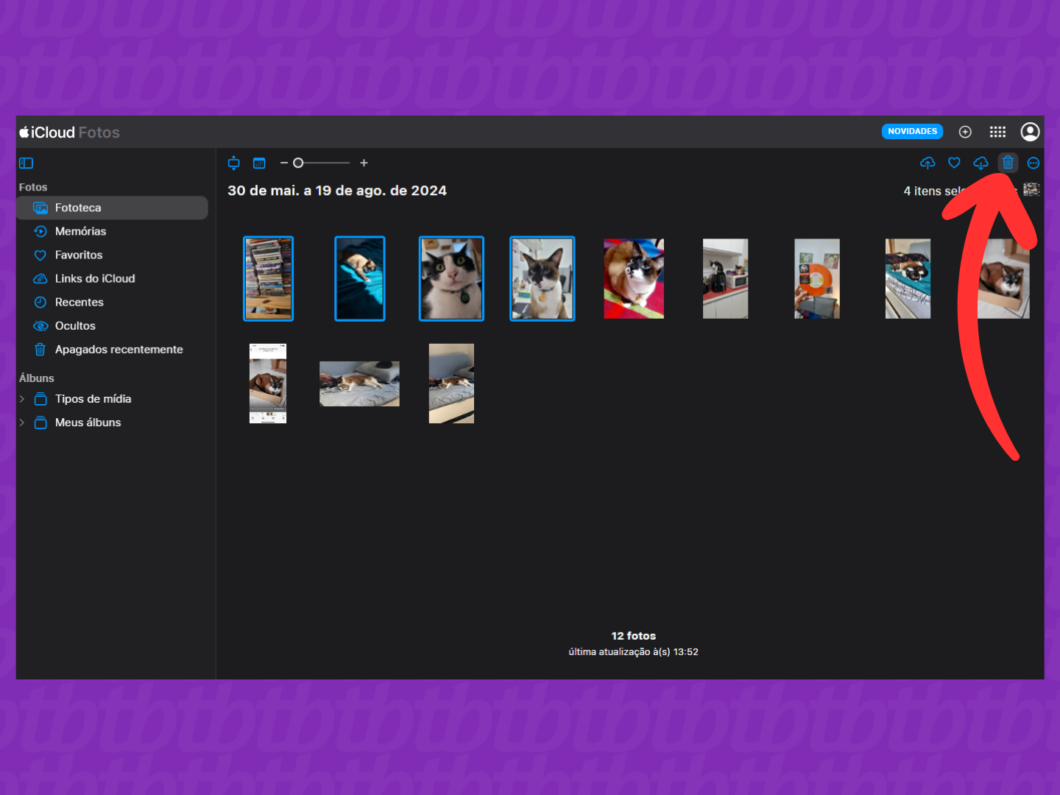


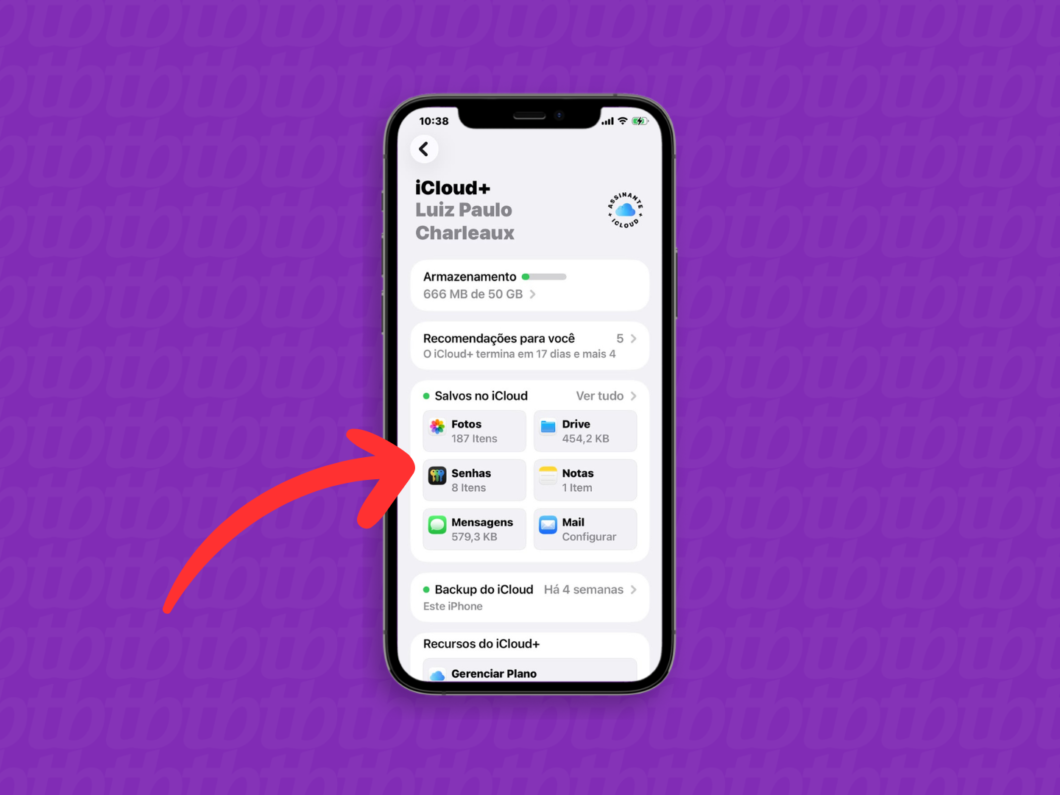
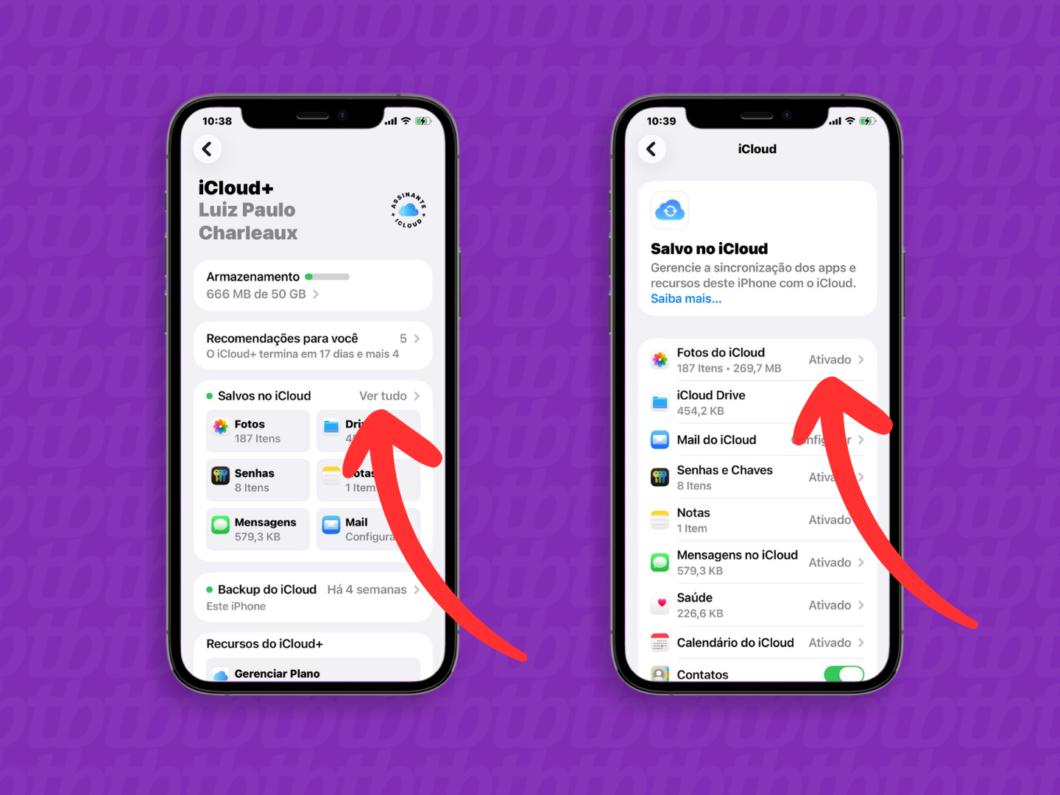
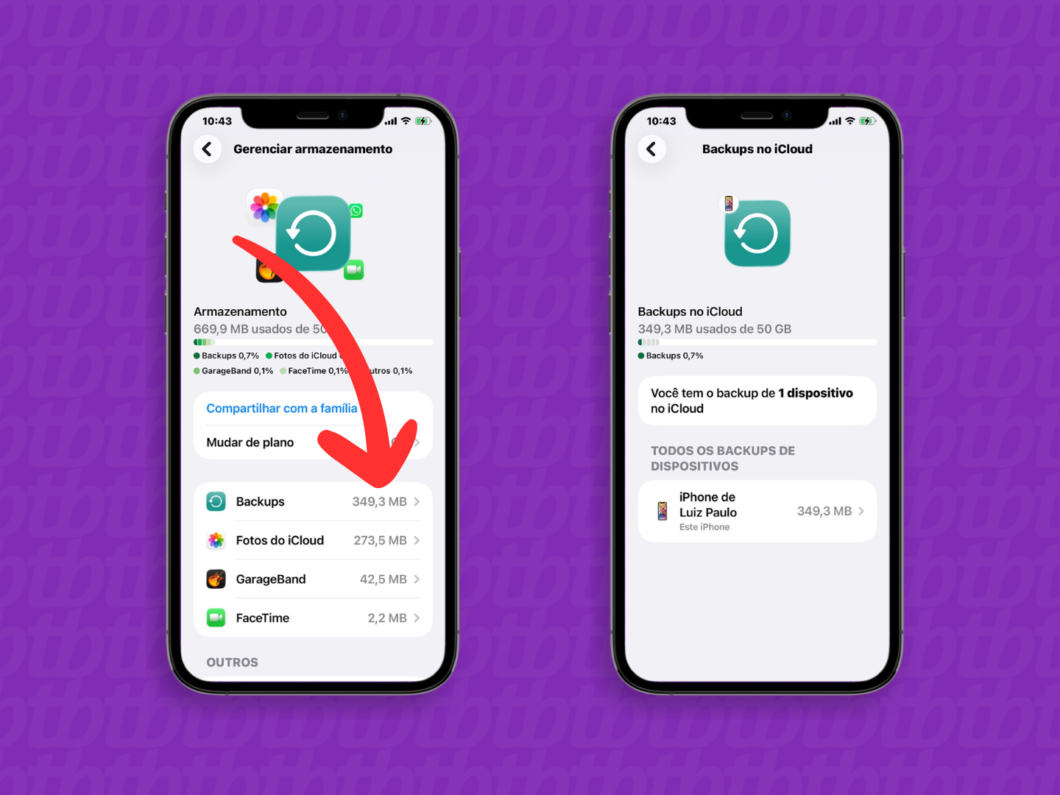
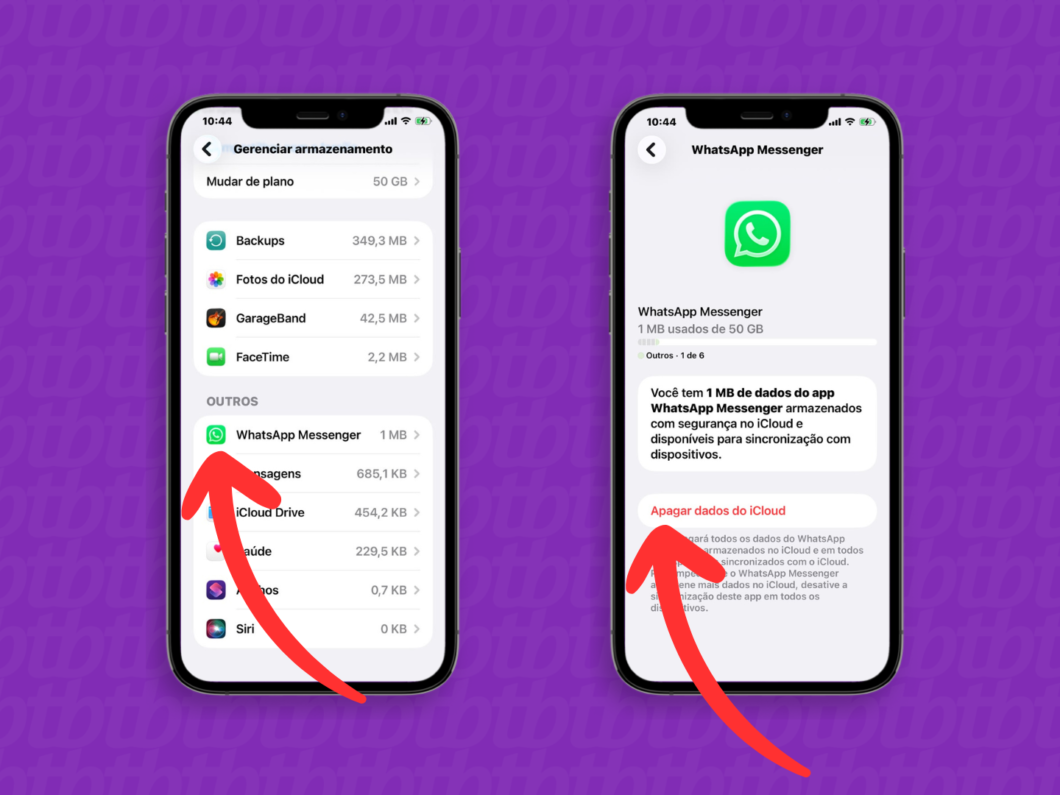














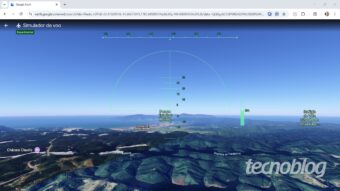
")
")
")


")





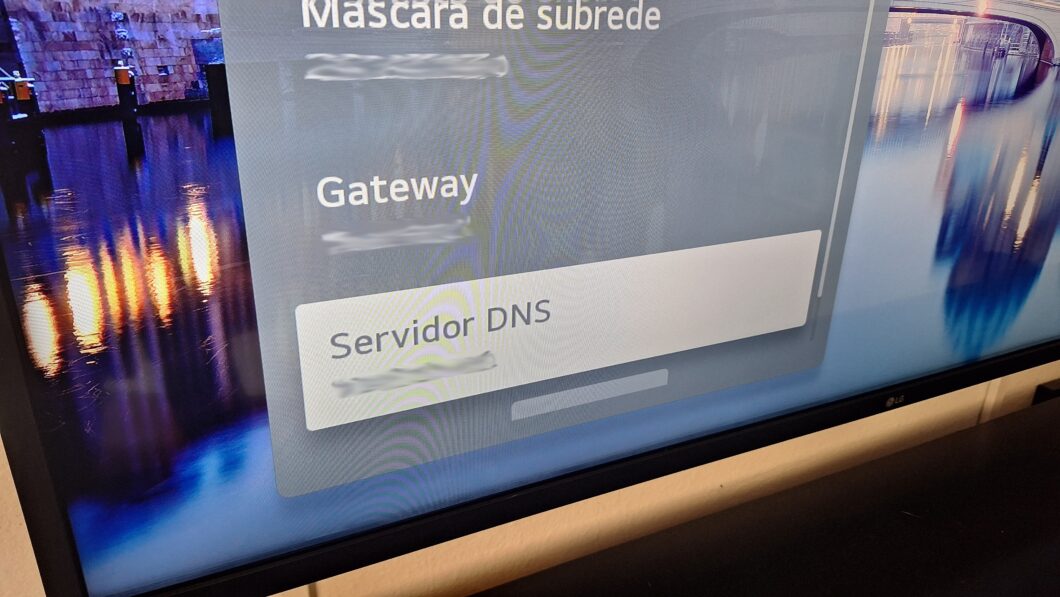































")
")
")





")
")


































")
")
")
")
")















")
")






")






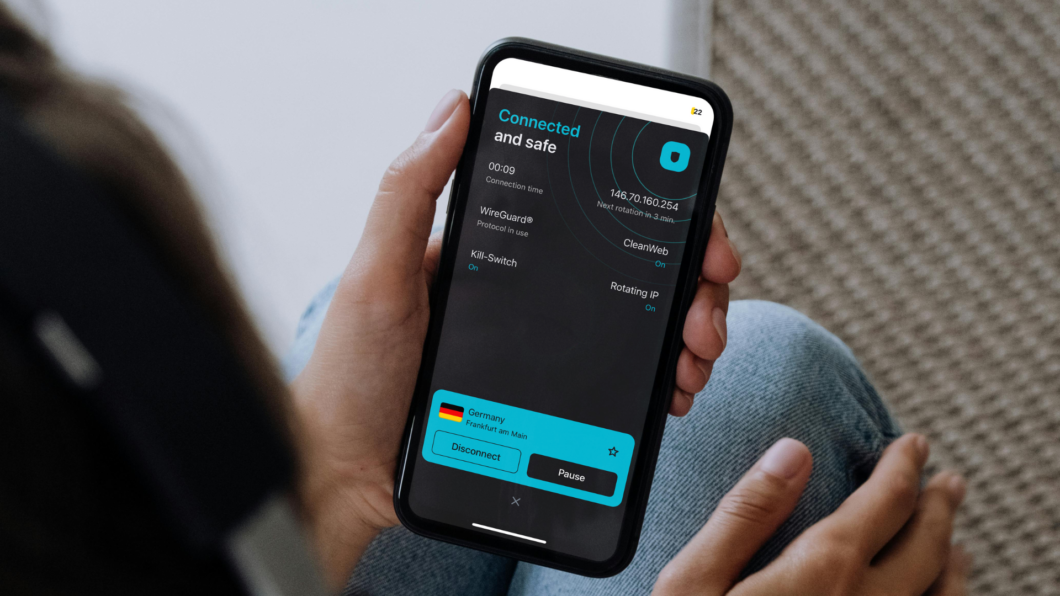

")
")
")





")






 facilitará localização de malas perdidas (imagem: reprodução/Google)")















")
")






")




")
")









")
")


")
")
")
")
")
")
")
")











")









 John Cairns")
 John Cairns")




")
")













")
")










")
")
")
")


")
")


















")














")























")


































")
")



")




















")
")
")
























")
")